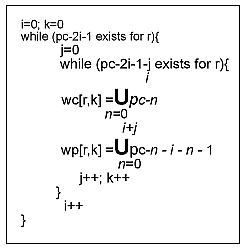|
|
|||||||||||||||||
|
Dispatches Application of Data Mining to Intensive Care Unit Microbiologic Data1Stephen A. Moser, Warren T. Jones, and Stephen E. Brossette
We have defined a new exploratory data mining process for automatically identifying new, unexpected, and potentially interesting patterns in hospital infection control and public health surveillance data. This process, and the system based on it, Data Mining Surveillance System (DMSS), use association rules to represent outcomes and association rule confidences to monitor changes in the incidence of those outcomes over time. Through experiments with infection control data from the University of Alabama at Birmingham Hospital, we have demonstrated that DMSS can identify potentially interesting and previously unknown patterns. Future work on prospective clinical studies to determine the usefulness of DMSS in hospital infection control is needed, as is improved event presentation for the user and strategies for handling larger datasets. The statistical strategies developed for automatically detecting temporal patterns in surveillance data require that analysts explicitly define outcomes of interest before surveillance begins. The Data Mining Surveillance System (DMSS), on the other hand, is not constrained to monitoring changes in user-defined outcomes. In DMSS, complex outcomes are represented by association rules, and outcome incidence is captured monthly. An early version of DMSS, along with association rules and early experiments with a single organism, has been described (1). We briefly describe a newer version of DMSS and experimental results obtained by using it to analyze 1 year's data from intensive care units (ICUs) at the University of Alabama at Birmingham Hospital. DMMS uses the following definitions. An itemset is a subset of the set of all items. The support of an itemset x, sup (x), is the number of records that contain x. If sup (x) > FSST, where FSST is the frequent set support threshold (FSST), then x is a frequent set. An association rule, A ==> B, where A and B are frequent sets and A n B = Ø, is a statement about how often the items of B are found with the items of A. The incidence proportion of A ==> B, denoted ip(A ==> B), is equal to sup(A u B)/sup(A). The precondition support of association rule A ==> B is sup(A). The incidence proportion of an association rule A ==> B in data partition pi describes the incidence of the outcome, B, in the group, A, during time ti. A series of incidence proportions for A ==> B from partitions p1, p2, …, pn describes the incidence of the outcome B in group A from t1 through tn. Therefore, by analyzing the series of incidence proportions of an association rule A==> B, it should be possible to detect important shifts or trends in the incidence of B in A over time. In this way, surveillance of B in A is possible. Bacterial susceptibility and related demographic data of patients in the University of Alabama at Birmingham Hospital ICUs (medical, surgical [SICU], cardiac, neurologic [NICU]) during 1997 were extracted from the PathNet laboratory information system. Each record describes a single isolate and contains the following data elements: date of admission, date of sample collection, date of results reported, source of isolate (e.g., sputum, blood), organism isolated, organism Gram stain and morphologic features, patient's location in the hospital, and resistant (R), intermediate (I), or susceptible (S) test results to relevant antibiotics, according to the National Committee for Clinical Laboratory Standards MIC breakpoints (2). Duplicate records were removed so that for each patient, no more than one isolate per organism per month was included. In each remaining record, certain antimicrobial drug items were removed (only drugs to which the organism is historically susceptible at least 50% of the time remained). Additionally, items of the form S~Antimicrobial were removed so that only I~Antimicrobial and R~Antimicrobial items remained. Finally, data were divided into 1-month partitions (p1…pn) before analysis. For each partition pi, all frequent sets with support of at least 3 (FSST >2) and association rules with precondition support greater than 5 were generated. Both the frequent set discovery and association rule-generating algorithms are beyond the scope of this review (3). Each generated association rule must pass a set of rule templates that describe families of interesting and uninteresting rules. Each template is a construct of the form be1 ==> be2, where be1 and be2 are Boolean expressions over items and attributes. Association rule A ==> B satisfies rule template be1 ==> be2 if A satisfies be1 and B satisfies be2. Two types of association rule templates are used: include templates and exclude templates. An association rule A ==> B passes a set of rule templates if A ==> B satisfies at least one include template in the set and does not satisfy any exclude template in the set. Rule templates are handcrafted by domain experts to eliminate inherently uninteresting or nonsense rules. This is accomplished through iterative experiments with representative data by initially using few templates and then creating and modifying templates on the basis of pattern review. History is a database that holds association rules and their incidence proportions for different data partitions. In DMSS, the user specifies a set of rule templates that contains any number of inclusive and restrictive templates (Table 1). Only association rules that pass the rule templates are included in the history. To establish a baseline for an association rule, the incidence proportions of the rule for the three previous partitions are obtained and stored in the history. Once stored in the history, a rule is updated for each new partition regardless of whether or not it is generated in the partition. Therefore, for every association rule, the history contains an up-to-date time-series of incidence proportions.
By analyzing information stored in the history, DMSS generates alerts that describe an
extreme change in the incidence of an outcome B in a group A over time. For example, Table
2 describes the incidence of Acinetobacter baumannii in a nosocomial
tracheal aspirate and in SICU isolates over the past six partitions. Clearly, a shift in
incidence occurs between the first 4 months and the most recent 2 months of the series. If
we call months 1, 2, 3, and 4 the past window, wp, and months 5 and 6 the
current window, wc, we can ask if there is an extreme change in the incidence
between wp and wc. We compute the cumulative incidence proportion
for wp (0/43) and for wc (5/18) and compare
the two by a statistical test of two proportions. To generate an alert for an association
rule r, DMSS first constructs a current window (wc) and a past window (wp)
on the series of incidence proportions of r (wc[r,0], wp[r,0] from
the algorithm in the Figure). Second, it computes the cumulative
incidence proportion for each window. Third, it compares the two cumulative incidence
proportions by a test of two proportions. Finally, if the difference between the
proportions is statistically extreme (p <
Current and past window pairs are generated by the algorithm in the Figure. If n is the number of incidence proportions in the history for a given rule, (wc:wp) pairs are generated for that rule in the following order: (pc:[pc-1,pc-2]}),...,(p c:[pc-1,...,pc-n]]),([p c,pc-1],[pc-2,pc-3 ]}),([pc,pc-1]},[pc-2 ,pc-3,pc-4]),([pc,p c-1],[pc-2,pc-3,pc -4,...,pc-n]), ([pc,pc-1,pc-2],[p c-3,pc-4,pc-5]}),([p c,pc-1,pc-2]},[pc-3 ,pc-4,pc-5,pc-6]}),...,([p c,pc-1,pc-2]},[pc-3 ,pc-4,pc-5,pc-6,...,p c-n]). For each pair, wp must be at least as large as wc. The total number of events was reduced from 251, by including all rules, to 36, by using the templates in Table 1; thus, classes of inherently uninteresting rules were eliminated. A retrospective look at the 155 events eliminated by the rule templates showed that they were uninformative. Therefore, the introduction of templates resulted in a more focused presentation of DMSS output. Of the 36 events, 18 were judged potentially interesting. Table 3 contains several representative events, one per row. Each row contains the association rule, the incidence proportions in wc (bold), and the incidence proportions in wp (nonbold). For example, event 1 in Table 3 describes an increase in the number of Staphylococcus aureus resistant to oxacillin, clindamycin, and erythromycin isolated from tracheal aspirates in the fourth partition, and compared with those isolated in the 2nd and 3rd partitions. Of the events identified by DMSS, only the NICU and SICU had events that were location-specific (Table 3), while eight events were not. The events identified by DMSS must be investigated by domain experts to determine their actual importance. In this example, the data burden was small since in a prospective analysis only a few events would be presented to the user each month, thus allowing for the investigation of each event.
We believe that this approach to surveillance will allow hospital infection control programs to focus their limited resources on issues of probable significance. We also believe that this approach is a step toward the public health surveillance system described by Dean, Fagan, and Panter-Conner (4). This work was supported in part by cooperative agreement U47-CCU411451 with the Centers for Disease Control and Prevention (SAM) and a predoctoral research fellowship LM-00057 from the National Library of Medicine (SEB). Dr. Moser is associate professor, Department of Pathology, University of Alabama at Birmingham, and serves as director of Laboratory Information Services, associate director of Clinical Microbiology for University Hospital, and director of the Pathology Informatics Section. His research interests are applied research in diagnostic microbiology and the application of software as an aid to the intelligent analysis of medical information, especially that generated in laboratory medicine. Address for correspondence: Stephen A. Moser, University of Alabama at Birmingham, Department of Pathology, P246, 619 19th St., South Birmingham, AL 35233-7331, USA; fax: 205-975-4468; e-mail: moser@uab.edu. 1Presented in part at the International Conference on Emerging Infectious Diseases, March 8-11, 1998, Atlanta, Georgia. References
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
Home | Top of Page | Current Issue | Expedited | Upcoming Issue | Past Issue | EID Search | Contact Us CDC Home | Search | Health Topics A-Z This page last reviewed July 1, 1999 Emerging Infectious Diseases Journal |