 |
Bayesian Approaches to Learning from Data: Using NHTS Data for the Analysis of Land Use and Travel Behavior
MARCO G. SCUDERI 1
KELLY J. CLIFTON 2, *
ABSTRACT
This paper introduces the application of Bayesian belief networks (BBNs) to the investigation of the relationship between land use and travel behavior and emphasizes the use of 2001 National Household Travel Survey (NHTS) data. Bayesian statistics are used to reason under uncertainty and provide the basis for a methodological approach that does not require stringent a priori assumptions about the statistical model employed to analyze the data. For this reason, this method is appropriate for exploring new relationships between land use and travel behavior that may not be apparent using more traditional approaches. This study focuses on the utilization of the NHTS add-on data for the Baltimore metropolitan region. The paper provides an introduction to modeling relationships between variables based on the structures of BBNs, provides insight into the specific methodological constructs needed to analyze NHTS data, and develops the potential to contribute alternative insights into the land use-travel behavior relationship.
KEYWORDS: Bayesian belief networks, meta-heuristic search algorithms, travel behavior, land use, travel survey data.
INTRODUCTION
This paper develops and tests a method to analytically derive a representation of land-use and travel behavior relationships using data from the National Household Travel Survey (NHTS). This research attempts to bridge the different existing theories, which tend to take a "top down" or inductive approach, by employing a complementary "bottom up" or deductive approach based on what the data may represent rather than how they may be analyzed. This approach, using Bayesian belief networks (BBNs), contributes a new and original method for the analysis of complex spatial-behavioral systems such as human interaction in the urban environment, and it presents an opportunity to expand further our theoretical knowledge in the area of land use and travel behavior.
Despite more than 20 years of intensive studies in this area, no unified theory exists to explain the interactions between land use and travel behavior. Conflicting results and frameworks remain a central theme in the debate about the possibility of recursive effects between the domains. Several issues arise due to these theoretical and empirical shortcomings. The impacts of land-use and transportation policy interventions on travel demand cannot be accurately gauged. Expensive transportation projects rarely result in accurate forecasts of future numbers of users, in part because forecasting methodologies do not adequately consider the effects of land-use changes resulting from transportation investments and how these changes alter travel demand (i.e., induced demand). This area of inquiry could benefit from a more specific and quantitative characterization of the relationships between land use and travel behavior than is available today.
Using 2001 NHTS add-on data for the Baltimore region, this paper proposes and tests a new approach to the analysis of the interactions between land use and transportation choices that does not require the design of statistical models prior to the analysis of the data. This approach is based on a process of knowledge discovery that uses BBNs to identify potential causal dependencies among variables, rather than imposing or assuming those relationships a priori. In this paper, not only does the output of BBNs become the foundation for an analytically oriented approach to model the land-use and travel behavior interaction, it also provides quantitative measures, in the form of conditional probability distributions, of how the various factors affect and interact with each other. The combination of Bayesian probability theory, graph theory, and geographic information systems gives a series of additional analytical perspectives to this problem. For example, in transit mode share, conditional probability distributions can be used to identify the highest probabilities of usage of a particular transit mode or the probabilities of obtaining a specific transit usage. The resulting maps also help distinguish among localities with similar urban characteristics but where the differing qualities of urban environments result in different behavioral responses.
The 2001 NHTS data, supplemented with local land-use data, offer a number of areas in which to test this Bayesian approach. For one, travel diary data provide a complete accounting of daily travel for all trip modes and purposes. Two, data from the add-on survey for the Baltimore region can be combined with a variety of land-use, urban form, transportation system, and community attributes. Three, the Baltimore region exhibits much variation in the urban environment, allowing for a robust study design. The variables proposed in this research design, including accessibility indices, land uses, and socioeconomic diversity, have all been identified in past studies as key factors in this relationship. The transport choices derived from the 2001 NHTS Baltimore add-on data are considered the behavioral response to social and economic conditions, transportation availability, and land-use characteristics.
The paper is organized as follows. First, the case for employing Bayesian approaches to land use-travel behavior research is made. Then, BBNs are explained in some detail with emphasis on the benefits of applying this data-driven approach to the topic of interest.
THE CASE FOR BAYESIAN APPROACHES
Traditional deductive research approaches suffer from a few drawbacks that can limit their ability to identify relationships. Statistical studies are often designed prior to data analysis (and sometimes data collection) and can be driven by theoretical assumptions. A distinction is made a priori about the nature of the relationships under investigation, including the direction and degree of the relationships between and among variables. It is a challenge to consider all of the complex phenomena and processes that influence travel behavior concurrently. Even more challenging is identifying the relationships among and between these factors. These underlying assumptions and model specifications, if incorrect or incomplete, can limit the findings and potentially mask important relationships.
Inductive reasoning breaks away from this deductive reasoning process and allows the analyst to directly query actual data for possible relationships among them so that the analyst can become more confident about the correct theoretical framework to use, one that could possibly be less fragmented and more universal than what is currently in use. BBNs provide a means to rise to this task because of their ability to assess an infinite number of relationships at the same time and their ability to present them in graphical form. In such an inductive environment, questions can be asked without the confinements dictated by specific statistical constructs or analytical methods.
Within the above set of relationships and behavioral decisions related to transportation outcomes, the linkages between daily activity participation and travel in the short term is of keen interest and is explored in more detail in this paper. The literature in this area presents a great number of differing conclusions using a variety of analytical approaches (e.g., Badoe and Miller 2000; Crane 2000; Ewing and Cervero 2001). The attempts to model these relationships are many; however, a robust behavioral framework is lacking (Waddell 2001). From a preliminary review of past studies, it appears that a great need still exists to study the relationship between land use and travel behavior because of its indetermination and the limitations of previous results, which can be identified as:
- The tendency to determine a priori the statistical output by selecting specifically diverse neighborhoods with contrasting characteristics, in order to prove that different land uses are associated with specific travel choices and vice versa.
- The difficulty of differentiating among qualitative properties of urban forms, which in this study can be resolved by observing and quantifying the human response to the built environment.
- Reliance on ad hoc statistical models based on the personal knowledge of specific researchers, inconclusive results, or excessive emphasis given to anecdotal and contradictory empirical evidence.
BBNs, however, are capable of addressing many of the shortcomings commonly found in existing approaches to the study of land use and travel behavior interactions. BBNs, also referred to as decision networks or probabilistic causal networks, have been quietly gaining momentum within the research community, mainly as a result of the great advantages obtained in the field of computer science, artificial intelligence, and automated learning (see Jensen 1996 and 2001 for an introduction). BBNs provide an easily understandable and easy-to-use environment for the analysis of complex spatial processes and the investigation of relationships between numerous variables. Still, the application of such a method would be meaningless without a comprehensive dataset that characterizes individual socioeconomic characteristics and captures individual preferences about transportation choices over a period of time. One potential data source is the NHTS and its information on American households, the individuals comprising them, and their transportation choices.
BBNs are a graphical representation of probabilistic causal information based on two components: a directed acyclic graph and a probability distribution (Glymour and Cooper 1999; Torres and Huber 2003). Nodes in the directed acyclic graph (DAG) represent stochastic variables and arcs represent directed stochastic dependencies among these variables. Thus, the graph provides a simple summary of the dependency structure relating the variables. This is an effective way to describe the overall dependency structure of a large number of variables, thus removing the limitation of examining the pair-wise associations of variables.
BBNs can also be used to reveal causal relationships among variables, which is an advantage when trying to gain an understanding of a problem domain, as in exploratory data analysis, and to predict the consequence of intervention. For example, Bayesian approaches are being used to predict credit card fraud and in the causal analysis of health issues. A classic example (Heckerman et al. 1995) looks at a marketing analyst trying to assess whether or not it is worthwhile to promote a specific advertisement in order to increase the sales of a product. The answer to this question depends on whether the advertisement is a cause for increased sales or not, and if so to what degree.
BBNs are an ideal representation for combining prior knowledge and data, because they combine both causal and probabilistic semantics. In many cases, real-world analysis benefits from prior knowledge and, in some cases, when data are incomplete or expensive, information from experts in the field is the only available source. Thus, it follows that a system that can integrate such prior knowledge into an analytical framework is a great advance.
OVERVIEW OF AUTOMATED LEARNING: THE BAYESIAN ALTERNATIVE
BBNs are computational objects able to represent compactly joint probability distributions by means of DAGs, which denote dependencies and independencies among variables as well as the conditional probability distributions of each variable, given its parents in the graph (Aliferis et al. 2003; Neapolitan 1990). The fundamental axiom of BBNs is the Markov Condition that allows for a concise factorization of the joint distribution and captures the main characteristic of causation in macroscopic systems, namely that causation is local (Glymour and Cooper 1999). In the graphs, nodes represent the variables, and the dependencies between variables are depicted as directional links from a parent node to a child node, which also correspond to conditional probabilities (Torres and Huber 2003).
Under uncertainty, the probability of B given A,p(B|A), represents the strength of the link in the graphs. A simple example of a BBN graph is shown in figure 1, where both nodes A and B are parents of node C, the child. However, if node C is itself a parent of B as in the feedback loop of figure 1(C), then we do not know how node B and C behave; they may cooperate or counteract each other in various ways. For these reasons, BBNs do not yet model feedback processes even though the differential calculus required to implement this functionality is well understood.
A BBN has the following properties:
- a set of variables and a set of directed edges between variables,
- each variable has a finite set of mutually exclusive states,
- the variables, together with the directed edges, form a DAG (a directed graph is acyclic if there is no directed path A1
→ … → An s.t. A1= An),
- for each variable A with parents B1,...,Bn, there is a potential table p(A|B1,...,Bn) attached.
Any conditional dependence represented by an edge (or link) is quantified by the set of conditional distributions of the child variable given a configuration of the parent variables. In a statistical experiment where nodes represent stochastic variables X= (X1, X2, ..., Xv), the conditional probability distribution is factorized as in:
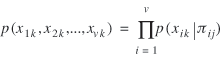 , ,
where (x 1 k, x 2 k, …, xv k, ) is a combination of values of the variables in X. For each i, the variable Πi denotes the parents of Xi, while xi kand π i j denote the events Xi= xi k, and Π i = π i j; the latter is the combination of values of the parent variable Π i in the event X= (X1, X2, …, Xv ).
While, traditionally, BBNs have been designed manually, one BBN represents all but one hypothetical dependency structure relating the variables. Many structures can be derived from the same set of data; thus, the analyst faces two problems: how to design the networks efficiently, and how to assess which one is better at encoding the relationship among the variables. In both cases, the latest advances in computer science and artificial intelligence now allow for the automatic learning of such structures by means of meta-heuristic search algorithms in which the subjectivity of individual beliefs is replaced by the tenets of probabilistic reasoning. Several commercial programs such as Bayesware Discoverer (http://www.bayesware.com) or Hugin (http://www.hugin.com) are now available to researchers. The authors of this paper use WinMine from Microsoft (http://www.winmine.com).
It is important to note that most search algorithms used to derive BBNs treat the data as a collection of cases where unique records are identified by a particular combination of values in the variables. Progressively, each case is read and compared with other cases in the dataset in order to derive the likelihood that a given event takes place in relation to the likelihood of other events in identical or similar cases.
STRUCTURE LEARNING
A generic model of the relationship among variables is little more than a starting point; what follows is a search for the best model that represents the relationship among the variables. This model is obtained by learning the structure of a BBN. In general terms, there are two approaches to learning these structures: constraint-based and search-and-score. They differ greatly, because the constraint-based approaches usually start with a fully connected graph and progressively remove the relational links connecting the variables if certain conditional independencies are measured in the data. This has the disadvantage that repeated independence tests lose statistical power and, therefore, this approach is used less often.
In the more commonly used search-and-score approach, the main step is a search through the space of all possible DAGs, which is intended to return one, or in some cases, a set of possible sample networks, which represent an approximation of the ideal dependency structure in the data. Unfortunately, the number of possible DAGs is a function of the number of nodes G(n), and it is super-exponential with respect to n. There is no known closed form formula for G(n), but the first few values for n = 1,2,...,10 are listed in table 1 (from Bayesware Discoverer). Because the number of possible networks is super-exponential in the number of nodes, it is not feasible to exhaustively examine the entire search space, so a local search algorithm (e.g., greedy hill climbing) or a global search algorithm (e.g., Markov Chain Monte Carlo—MCMC) is generally employed. The most basic procedure used for this task is the K2 algorithm, which tries to find the best structure by recursively selecting the best set of parents for each node independently. This implies that the total ordering of the variables is known, a situation that may not always be true. If the variable ordering is unknown, a search over the most likely orderings is usually more efficient than searching over DAGs (Friedman and Koller 2000).
In addition to the search procedure, the specifications for the scoring function are as follows: let the set M= {M1,M2,...,M3} be a grouping of BBNs for the discrete random variables. With p(M h) denoting the prior probability of M h for each h= 1,..., g, the typical solution to the model selection problem is to choose the network with the maximum posterior probability:
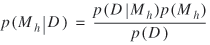
The quantity p(D|Mh) is the marginal likelihood that provides the Bayesian score with which to compare different models.
Selecting the network with the maximum posterior probability as derived by the search and score algorithm is quite a brute force approach to structure learning because of the need to generate and score all possible DAGs. This approach, however, provides a baseline for comparing the performance of other algorithms used to generate BBNs. More effective than the K2 algorithm, the hill-climbing algorithm searches all points in space and their nearest neighbors, defined as all "graphs that can be generated from the current graph by adding, deleting or reversing a single arc" (Chickering et al. 1997). It then moves to the neighbor that has the highest score, and if no neighbors have a higher score than the current point, the algorithm stops. The best practice is then to restart the procedure at a different point in space n number of times until the scores converge.
Another technique to automatically generate BBN structures is the MCMC algorithm that effectively searches the space of all possible DAGs, a property that characterizes it as being polynomial (not exponential) in the dimensionality of the search space. This makes the MCMC approach difficult for practical applications requiring the use of more than 10 variables.
Finally, the search and score approach used by the authors of this paper is the one developed by Chickering et al. (1997) at Microsoft Research. Similar to the hill-climbing approach, this algorithm adds, deletes, and reverses the possible arcs among the variables, but it does so in the context of decision graphs used to represent the relationship among each pair of variables. This algorithm also integrates aspects of the Expected Maximization algorithm, which requires the calculation of the expected sufficient statistics for the data. The expected sufficient statistics are then used to ensure the convergence of the results obtained using a dataset with missing values with the results generated from a complete dataset.
With this technique, the analysis begins with the observation that the local distribution for variable Xiin a dependency network is the conditional distribution p(xi| X \ xi), which can be estimated by any number of probabilistic classification techniques (or regression techniques, if we were to consider continuous variables) such as generalized linear models, neural networks, probabilistic support-vector machine, or embedded regression/classification models (Heckerman et al. 2000). The method we chose in this case is a probabilistic decision tree where for each variable Xiin domain X, the classification algorithm independently estimates its local distribution from the data. Once all estimates for the local distributions are obtained, the structure of the Bayesian network can be constructed from the (in)dependencies encoded in these estimates (Heckerman et al. 2000). Each variable is modeled as a multinomial distribution and the learned decision tree corresponds to the Bayesian network.
The algorithm searches each row of data for unique combinations of categorical data. Each unique combination is called a "case" and it forms the basis of the following analytical steps, where the algorithm greedily grows decision trees using the Bayesian scoring criterion. This is a greedy algorithm that combines global search over the structure's relational links with local search over all of the nodes in the decision graphs. It begins with one node (variable) and evaluates its relationship to the other nodes (variables) by means of decision trees; then it scores the corresponding Bayesian structure based on its posterior probability of such a network considering the given cases. The procedure is as follows:
- Score a generic network structure. For each node x(variable) in the graph:
- Add every nondescendant that is not a parent of x to the parent set
- For every possible operator O in the graph:
i.
Apply O to BS
ii. Score the resulting structure
iii.
Un-apply O
- Remove any parent that was added to x in step 3
- If the best score from step ii is better than the current score
a.
Let O be the operator that resulted in the best score
b. If O is a split operator (either complete or binary) on a node x that is not in its set of parents then add a new node to the parent set
c. Apply O to BS
d. Go to 1
- 6. Otherwise, return BS.
Three operators (O) are allowed:
- Complete split adds a child node to a set of parents,
- Binary split adds two children to a set of parents,
- Merge split combines two or more children in a single new node inheriting all of their parent nodes.
To learn a decision-tree structure for Xi, the search algorithm is initialized with a single root node having no children. Then, each leaf node is replaced with a binary split on some variable Xj in X \ Xi until no such replacement increases the score of the tree. The binary split on Xj is a decision-tree node with two children: one of the children corresponds to a particular value of Xj, and the other child corresponds to all other values of Xj(Chickering et al. 1997).
BBN APPLICATION TO LAND USE AND TRANSPORTATION RESEARCH USING THE 2001 NHTS
As mentioned earlier, significant questions remain about the land-use and transportation relationships and their interdependencies. A variety of approaches and data sources have been applied to this problem with varying results and often with conflicting findings. BBNs, coupled with automatic learning, could provide new insight and perhaps offer a better approach to the analysis of this subject. The focus of the research reported here is to assess the effectiveness of such a method. Efforts have so far centered on testing survey data and analytical requirements of BBNs. Here, we pay particular attention to the use of 2001 NHTS data for the Baltimore metropolitan area.
This paper expands Torres and Huber's application of BBNs to research travel behavior questions (Torres and Huber 2003) by adding land-use variables and by employing a more advanced search algorithm. Torres and Huber investigated the use of BBNs to estimate travel mode choice as a function of socioeconomic variables only. Their approach made use of the K2 algorithm that is now obsolete, largely because it required the analysts to design a hypothetical BBN that was used as the starting point for the search algorithm. The method presented in this paper drops such requirements and is truly heuristic.
STUDY AREA AND DATA
The study area was the Baltimore metropolitan region, which covers the counties of Carroll, Howard, Anne Arundel, Baltimore County, Harford, and Baltimore City. Detailed data for sampled households and individuals were obtained from the 2001 NHTS Baltimore add-on survey. To these were added derived profiles of typical land-use patterns, socioeconomic characteristics, and road density for each tract and zip code in the study areas. The variables used in this analysis are shown in table 2.
All variables were reclassified into categorical form. In many cases, the number of classes within each variable was reduced to simplify the analysis. For example, the variable age for the respondents was reduced to four classes, with an important separation for teenagers at 16 years of age to reflect the possibility of acquiring a driving license. The response variable race was reclassified into four categories. More importantly, the race of the respondent was also assigned to the remaining members of the family, an assumption that might not always hold true. The personal income variable was created by first classifying the household income into 11 classes and then dividing the midway dollar amount associated with each class by the number of people living in a particular household. Transportation mode choices were reduced to just three classes: private vehicle, walking, and public transit. Private vehicle trips include the use of private cars, trucks, motorcycles, vanpooling, etc. Walking trips include bicycling, wheelchair mobility, jogging, and any other nonmotorized trip. The choice for transit included all public transportation systems except for ferry and water taxi, which given their limited presence in the data were not analyzed in this study.
The land-use variables were derived from the Maryland Property View Data; in particular, we used the 1997 Land-Use/Land Cover geographic information system information layer updated to the year 2000. Each land-use polygon was assigned to a zip or a tract and its boundaries reshaped to fit into such administrative units. Based on the total area of each administrative boundary, land-use variables were then calculated as a percentage of the total area and then reclassified into 10 discrete amounts of land-use covers for each type of residential, commercial, or other land use. The road network was subject to similar processing where each road segment was assigned to a tract or zip and its spatial length recalculated accordingly. A discrete ratio of the total road length within each administrative unit over the total areas for such units created an index of road density.
Land-use variables are available as continuous percentage values, but the decision was made to classify them into discrete categories, as was done for the other NHTS data. The resulting dataset can be organized in at least four different ways for analysis with BBNs. Each data framework has its own advantages and disadvantages as summarized below. In this paper, individual trip records were used as the unit of analysis for the transportation data.
- Individual trip records allow for the maximum number of cases that the search score can use to generate the most compelling networks. For this study, 22,000 trip records were used to generate a model linking land-use variables, socioeconomic factors, and other variables to transportation mode choice. The drawback of trip-level analysis is that the total numbers of trips by mode cannot be analyzed.
- Spatial units such as tracts or zip codes could also be used as the basic unit of analysis. For the study area here, there are just over 600 census tracts and just over 150 zip code areas covering the 6 counties. With this data structure, the characteristics of each spatial area could be summarized and transportation mode choice could be analyzed in terms of overall number of trips made by each mode. For the technically inclined, this data structure is the transpose of the case above and although it results in a considerably lower number of records, it could be considered as a more geographically based approach. However, the number of trips in any given census tract or zip code may be limited due to the sampling structure of the NHTS and it may be insufficient to yield robust results.
- Individuals or households, too, could form the basis for analysis. For the Baltimore add-on, there were approximately 7,800 individual records and 5,000 household records to analyze for the entire area of interest. An individual's full array of trips on the travel day could be the focus of analysis that would highlight an individual's autonomy in decisionmaking and the role of individual circumstances, resources, and constraints. Basing the analysis on households has the advantage of examining the full array of trips (or trips by specific modes) made at the household level, which may be the preferred decisionmaking unit and reflect shared resources and household responsibilities.
- Finally, trip tours could be constructed and analyzed to understand the interdependencies that occur between a sequence of trips and their relation to personal, household, and land-use characteristics. Considerable effort would be required to construct trip tours, but this remains a very promising and relatively new area of investigation.
PRELIMINARY RESULTS
For this paper, the unit of analysis was Case 1 presented above—the individual trip. However, the land-use attributes for the trip origin were aggregated and tested at two geographic scales: census tracts and zip codes. As such, there were multiple resulting BBNs depending on the spatial unit of aggregation. The analysis was also carried out with and without all control variables, such as age, household size, and vehicle count, to investigate the influence of variables with considerably fewer discrete classes. Finally, the models were run with and without specifying variable ordering, such as the characterization of the variables as input, output, and super-groups. Table 3 summarizes the six model specifications.
Models 1 and 4 created the most comprehensive results with a graphical representation of the relationship between land use, transportation choice, and all the control variables. In all cases, the graphs represent a relationship with a nondirected link having an arrow at both extremes. In the case of strong directional relationships that can be interpreted as causal relationships, the links show one single arrow pointing toward the child variable and originating from the parent node by which the child is influenced. All the relationships are quantitative in the sense that their strength is computed by the algorithm.
In figure 2, we present this strength in three sequential snapshots of the two models (where the land-use measures are calculated at both the tract and zip code level) that show first the strongest links, then the links with an average strength, and finally all links. In reality, the user can select the link strength as a continuum and obtain the appropriate display at any stage, a case that cannot be replicated on paper because of obvious space limitations. For the zip code model in figure 2, the analyst has selected the mode choice node as the one node of interest. The nodes in black are the parent set of the mode choice child, and they are presented in order of influential strength. In fact, the algorithm also distinguishes among variables predicted by and predictive of the variable of interest (mode choice) with appropriately colored nodes (not shown).
It is interesting to explore these outputs of the models in more detail. As the calculation of the land-use variables is moved from tract to zip level, it can be seen that land-use variables have a weaker influence on mode choice and in fact the percentage of vacant land is even excluded from our resulting BBN. These results can be explained by the fact that at coarser spatial aggregation, each spatial unit becomes more and more homogeneous compared with other polygonal areas and there is less variation in land use across tracts.
Although the goal of this paper is to present results as a proof of concept rather than an in-depth discussion of the land-use/travel behavior relationship, it is worth noting how the mode choice is influenced by the other variables. The strongest links associated with the choice of transportation are the availability of a private vehicle (condition sine qua non for driving), the driver status (having a license or not), age (another condition required to have a driving license), and how empty the landscape looks around the point of origin. This result is even more interesting if we consider that the land-use variable other includes agricultural land, which is critical in suburban or ex-urban conditions.
Figure 2 shows a limited sequence of how these links are progressively presented as part of the relationship structure; as the strength of the relationships weakens, we detect ethnicity, driver status, and the land-use variable of medium residential as also influencing mode choice. Household size, income, and number of commercial spaces were the least influential variables. These may be interpreted as important results, because they demonstrate that, despite their low income, poorer families also use private vehicles to a great extent. Weak relationships with income underscore the fact that low-income households rely on all modes of transportation, not just transit. It is only from the analysis of the conditional probability distribution (CPD) (table 4) that a broader interpretation for income is possible. Household size can be seen as a proxy for generating trips, but it is not a good predictor of mode choice and neither is the amount of commercial activity around the point of trip origin. This is a surprising result for those advocating mixed commercial uses around denser neighborhoods, but we will see later how this variable should in fact be grouped with other land-use variables.
If the BBN outputs were limited solely to graphs, such as those presented in figure 2, the analysis would be little more than an intellectual exercise. However, each BBN algorithm provides the analysts with decision trees, based on a multinomial choice distribution about how the various nodes behave in relation to each other in a quantitative way.
Figure 3A presents the decision tree associated with Model 1 when analyzing mode choice. Each node presents a binary split of one variable based on the conditions of the parent set of variables. For example, the trees can examine detailed questions such as: what are the probabilities that someone living in a medium-level residential area will choose driving versus transit as a function of vehicle availability and race? From the decision tree, one can see that for a vehicle count other than zero and for any race group other than white, the probability of a motorized trip is low; the probability of a nonmotorized trip is high; and the probability of a transit trip is medium. As we move toward the tree's end-leaves, these conditional probabilities are retained but the tree adds the case of no licensed driver available in the household, in which case the probability of transit trips almost doubles (from 30% to 60%).
Graphically, we have followed the path from the node medres(medium-density residential land-use) to other(other land uses) in figure 3A and, for each node, the probability information is presented as in figure 3B. The remaining details in figures 3C, 3D, 3E, and 3F zoom out to include all the paths of evidence from the strongest variable affecting mode choice (vehicle count) to the one variable of interest, in this case income and percentage of commercial land uses. In all cases, the probability of choosing one mode over another changes as the influence of a new variable is added to the set of parents.
The application of meta-search algorithms for the creation of BBNs results in graphs and decision trees. If using categorical data, it is also possible to calculate tables containing the CPD of each node and its parent set. The results look similar to table 4, table 5, and table 6, where the probability of each mode choice is calculated as a function of the status of all the classes within the variables of driver count, vehicle count, percentage medium-density residential, and percentage high-density residential. The algorithm used in this research calculates the probability for the state of a class in all variables so the resulting tables are quite large. For example, in the case of the classes for variable driver count, which reports the number of drivers per household, these are assigned a probability of occurrence based on the occurrence of all other classes in all other variables. This is quite useful, but the algorithm has no knowledge that the land-use variables should all add up to 100% of the land-use cover for a given area. It follows that the CPD tables for land-use variables include situations where the occurrence of an 80% high-density residential area is compared with the occurrence of a 60% commercial land use, a case that clearly does not happen in reality.
One interesting outcome derived from the analysis of the six models' CPDs is that high probabilities of transit share and nonmotorized trips occurred either when the land-use variables have shown a large concentration of residential land use (as in a downtown area) or when there were small percentages of a mix of different land uses. This result would tend to quantitatively support the argument of those who favor mixed use as a means to improve transit ridership and abate private vehicle use and pollution.
DISCUSSION AND CONCLUSIONS
This paper presents the successful application of BBNs to the land-use/travel behavior relationship using data from the 2001 NHTS add-on, supplemented with local land-use and socioeconomic data. This "bottom up" or inductive approach can potentially contribute to the knowledge base by identifying relationships that might otherwise be masked by the limitations of traditional deductive approaches and by aiding in the development of theoretical models. The limited results presented here, however, were not meant to form the basis for theory building per se but rather demonstrate the utility of the NHTS data and the BBN method for future applications to theoretical and empirical investigations of transportation questions. In doing so, a number of advantages and limitations of this method were identified, as well as opportunities for future work.
The creation of BBNs provides the analyst with a model of the relationships among variables under study that is derived by means of meta-heuristic search methods. No statistical model needs to be specified a priori, and there is no need to characterize variables as independent or dependent. It provides quantitative assessments of the occurrences of specific outcomes based on the status of all other variables, and it allows for the study of complex problems based on how the data capture them.
The confidence that these graphs represent identify a real underlying relationship between land use and transportation remains to be tested. The "lift over marginal" log score provides information on how well the model fits the data. Also, as in all appropriate modeling attempts, it is possible to test the model on a subset of data to verify that its relationship construct and conditional probabilities still hold true.
Finally, there is no standard approach on how to compare the graphical results of a BBN with the quantities obtained by using traditional inferential statistics. One procedure proposed here is to derive elasticities by calculating the means for all variables and their associated regression coefficients using Bayesian inferential statistics. Once the elasticity for each variable has been established, simple comparisons could be made between the results obtained by means of heurist inductive reasoning and those derived by means of traditional deductive model building. Another approach is to translate the resulting BBNs into a discrete structural equation model of the standard error of the mean (SEM); this technique is a linear cross-sectional statistical approach that uses path analysis as its input. Analysts usually create the causal path among variables ad hoc, but the output of inductive reasoning, such as the BBN presented in this study, could be used as an independently derived variable path for SEM. Once again, elasticities could be derived to compare the results with other deductive studies.
This analysis of land-use and transportation interactions by means of BBNs has highlighted a number of important factors. In our analysis of the NHTS travel diary data, each trip was considered unique and was characterized by the land-use conditions of the tract or zip from which it originated. This assumption implies that each trip was treated independently of all other trips, even if some were originally taken as a part of a trip chain. In practice, the algorithm used in this analysis treated trips as discrete separate events, which is not always the case, as when multiple trips are made by the same person. This type of analysis is not necessarily based on the best assumptions but, as mentioned above, future analysis can be undertaken with the trip chains being explicitly considered as such. Furthermore, the aim in this research was to focus on the land-use conditions underlying the decision to use a particular trip mode, even as we recognize that interdependencies exist between sequential trips and their modal choices.
One issue with NHTS data was also related to the spatial limitation of the sample taken at the national and local level. Clearly such an analysis would have not been possible without the add-on data and the availability of records for about 25,000 trips in the Baltimore region. However, some issues were identified that relate to the spatial distribution of the respondents. Some tracts show as having no, or a low number of, trips originating from them, and repeating the analysis at a smaller geographic scale, such as the block level, will exacerbate this problem. This is not an issue when using journey-to-work data from the U.S. Census at the tract level, due to the more extensive household sampling of one in six households per tract (for the SF3 data).
A final issue relates to the scale of aggregation used in the analysis. The analysis at two different geographic scales, tract and zip code levels, is important to detect the sensitivity of dependencies between variables as a result of aggregations. These results are interesting, and, in the future, to investigate the effects from the Modifiable Aerial Unit Effect, the analysis will be carried out at four different geographic scales: traffic analysis zones, zip codes, census tracts, and block groups. Work is also underway to recreate the analysis with better measures of transit accessibility and to use the various administrative units, not trips, as the base records for the input database. The authors believe this to be a more geographical approach to the analysis of data, which would complement any analysis of survey data based on trips or personal information.
Finally, data mining applications using Bayesian approaches are in fact just one application area. Bayesian inferential approaches may also be used as modeling tools to create parameter estimates and develop forecasts. A worthwhile study would be to find the future transportation mode split, in light of infrastructure development—for example, to assess the impact of new transit lines or new bus routes. A network of relationships can be derived heuristically and directly from data. The second step is to collect sample data from the area in which the investments are to take place, to source the actual data with which to instantiate the Bayesian model. Inference is then the simple exercise of finding the posterior probability of each mode as a function of both the local data and the probabilities for the transportation choice parameters. This approach provides a simple and immediate local forecast of transportation mode split and the likelihoods for each mode; however, more accurate estimates can be obtained by slightly varying the instantiation values so that a number of equivalent posterior probability distributions can be sampled and a more robust simulation produced. This more complex method provides not only the probability of each mode split but also the probability distribution for such modes as other variables change.
It must be noted that unless data-collection efforts and surveys such as the NHTS continue to be carried out, the availability of large datasets required for the use of meta-heuristic algorithms will be limited, and thus the full potential of such a method in the field of planning might not be fully realized. This would be unfortunate, because there is a promising future for the application of Bayesian statistics and BBNs. Microsoft is already implementing these methodologies for data-mining functions in their flagship product, SQL. Academics in computer science are trying to implement algorithms that will specifically model feedback processes, and dynamic BBNs can be used to model changing relationships over time. For planners and transportation practitioners, the hope is that this method will provide us with the ability to gain more in-depth knowledge for the solution of complex issues.
REFERENCES
Aliferis, C., I. Tsamardinos, A. Statnikov, and L.E. Brown. 2003. Causal Explorer: A Probabilistic Network Learning Toolkit for Biomedical Discovery, in Proceedings of the 2003 International Conference on Mathematics and Engineering Techniques in Medicine and Biological Sciences (METMBS), Las Vegas, Nevada, USA, June 23–26, 2003.
Badoe, D.A. and E.J. Miller 2000. Transportation Land-Use Interaction: Empirical Findings in North America, and Their Implications for Modelling. Transportation Research Part D: Transport and Environment5(4):235–263.
Chickering, D.M., D. Heckerman, and C. Meek. 1997. A Bayesian Approach to Learning Bayesian Networks with Local Structure. Microsoft Technical Report, MSR-TR-97-07. Available at http://research.microsoft.com/research/pubs/.
Crane, R. 2000. The Influence of Urban Form on Travel: An Interpretive Review. Journal of Planning Literature15(1):3–24, August.
Ewing, R. and R. Cervero. 2001. Travel and the Built Environment: A Synthesis. Transportation Research Record1780: 87–122.
Friedman, N. and D. Koller. 2000. Being Bayesian About Network Structure. Uncertainty in Artificial Intelligence. Edited by C. Boutilier and M. Godszmidt. San Francisco, CA: Morgan Kaufmann Publishers, pp. 201–210.
Glymour, C. and G.F. Cooper (eds). 1999. Computation, Causation, and Discovery. Menlo Park, CA: AAAI Press/The MIT Press.
Heckerman, D., D.M. Chickering, C. Meek, R. Rounthwaite, and C. Kadie. 2000. Dependency Networks for Inference, Collaborative Filtering, and Data Visualization. Journal of Machine Learning Research1:49–75
Heckerman, D., D. Geiger, and D.M. Chickering. 1995. Learning Baysian Networks: The Combination of Knowledge and Statistical Data. Machine Learning20: 197–243.
Jensen, F. 1996. An Introduction to Bayesian Networks. New York, NY: Springer.
_____. 2001. Bayesian Networks and Decision Graphs. New York, NY: Springer.
Neapolitan, R.E. 1990. Probabilistic Reasoning in Expert Systems. New York, NY: John Wiley and Sons.
Torres, F.J. and M. Huber. 2003. Learning a Causal Model from Household Survey Data Using a Bayesian Belief Network, presented at the Annual Meetings of the Transportation Research Board, Washington, DC.
Waddell, P. 2001. Towards a Behavioral Integration of Land Use and Transportation Modeling, presented at the 9th International Association for Travel Behavior Research Conference, Queensland, Australia.
ADDRESSES FOR CORRESPONDENCE
M. Scuderi, Urban Studies and Planning, 0109 Caroline Hall, University of Maryland, College Park, MD 20742. E-mail: scudhome@yahoo.com
Corresponding author: K. Clifton, Urban Studies and Planning, National Center for Smart Growth Research and Education, Preinkert Field House, Suite 1112, University of Maryland, College Park, MD 20742. E-mail: kclifton@umd.edu
|
|

