 |
Roadway Traffic Crash Mapping: A Space-Time
Modeling Approach
Shaw-Pin Miaou*
Texas Transportation Institute
Joon Jin Song*
Bani K. Mallick*
Texas A&M University
ABSTRACT
Mapping transforms spatial data into a visual form, enhancing the ability of users to observe, conceptualize, validate, and communicate information. Research efforts in the visualization of traffic safety data, which are usually stored in large and complex databases, are quite limited at this time. This paper shows how hierarchical Bayes models, which are being vigorously researched for use in disease mapping, can also be used to build model-based risk maps for area-based traffic crashes. County-level vehicle crash records and roadway data from Texas are used to illustrate the method. A potential extension that uses hierarchical models to develop network-based risk maps is also discussed.
INTRODUCTION
Transportation-related deaths and injuries constitute a major public health problem in the United States. Injuries and fatalities occur in all transportation modes, but crashes involving motor vehicles account for almost 95% of all transportation fatalities and most injuries. Despite the progress made in roadway safety in the past several decades, tens of thousands of people are still killed and millions of people are injured in motor vehicle crashes each year. For example, in 1999 nearly 42,000 people were killed in traffic crashes and over 3.2 million more were injured.
Motor vehicle fatalities are the leading cause of unintentional injury deaths, followed by falls, poisonings, and drownings (about 16,000, 10,000, and 4,400 deaths per year, respectively) (NSC 2002). They are also responsible for as many pre-retirement years of life lost as cancer and heart disease, about 1.2 million years annually. In fact, motor vehicle crashes are the leading cause of death for people aged 1 to 33. Societal economic losses from these crashes are huge, estimated by the National Highway Traffic Safety Administration to exceed $230 billion in 2000. Thus, much work remains to be done to develop a better understanding of the causes of vehicle crashes—their chains of events and operating environments—and to develop countermeasures to reduce the frequency and severity of these crashes (USDOT 1996–1999).
Safety is one of the U.S. Department of Transportation's (USDOT's) five current strategic goals, and Rodney Slater, a former Transportation Secretary stated: "Safety is a promise we keep together." Indeed, roadway safety intersects with all five core functional areas within conventional highway engineering (planning, design, construction, operation, and maintenance) and crosscuts the boundaries of other engineering (vehicle and material) and nonengineering areas (human factors, public health, law enforcement, education, and other social sciences). Thus, research in roadway safety requires interdisciplinary skills and essential cooperation from various engineering and social science fields.
In 2002, a series of conferences was hosted by the Bureau of Transportation Statistics under the general title of "Safety in Numbers: Using Statistics to Make the Transportation System Safer." These conferences supported the top strategic safety goal of promoting public health and safety "by working toward the elimination of transportation-related deaths, injuries, and property damage" (USDOT 2002).
Contributing Factors, Countermeasures, and Resources
Motor vehicle crashes are complex events involving the interactions of five major factors: drivers, traffic, roads, vehicles, and the environment (e.g., weather and lighting conditions) (e.g., Miaou 1996). Among these factors, driver error has been identified as the main contributing factor to a great percentage of vehicle crashes, and many research efforts are being undertaken to better understand human and other synergistic factors that cause or facilitate crashes. These factors include operator impairment due to the use of alcohol and drugs, medical conditions, or human fatigue and the operator's interaction with new technologies used on the vehicle.
Countermeasures to reduce the number and severity of vehicle crashes are being sought vigorously through various types of community, education, and law enforcement programs and improved roadway design and vehicle safety technology. However, many of these programs have limited resources and need better tools for risk assessment, prioritization, and resource scheduling and allocation.
Recognizing that "to err is human" and that driver behavior is affected by virtually all elements of the roadway environment, highway engineers are constantly redesigning and rebuilding roadways to meet higher safety standards. This includes designing and building roadways and roadsides that are more "forgiving" when an error is made, more conforming to the physical and operational demands of the vehicle, and that better meet drivers' perceptions and expectations in order to reduce the frequency of human errors (TRB 1987). The relatively low fatality rate on the Interstate Highway System (about half the fatality rate of the remainder of the nation's highways) is evidence of the impact of good design on highway safety (Evans 1991).
Many impediments keep highway engineers from achieving their design and operational goals, including a lack of resources and a vast highway system that needs to be built, operated, maintained, audited, and improved. They must make incremental improvements over time and make difficult decisions on the tradeoffs among cost, safety, and other operational objectives. Consequently, knowing where to improve and how to prioritize and schedule improvements is as important as knowing which roadway and roadside features and elements to add or improve. Tools for identifying, auditing, ranking, and clinically evaluating problem sites; developing countermeasures; and allocating resources are essential for highway engineers who make these decisions.
Disease Mapping and Methods
In recent years, considerable progress has been made in developing methodology for disease mapping and ecological analysis, particularly in the application of hierarchical Bayes models with spatial-temporal effects. This model-based development has led to a dramatic gain in the number and scope of applications in public health policy studies of risks from diseases such as leukemia, pediatric asthma, and lung cancer (Carlin and Louis 1996; Knorr-Held and Besag 1997; Xia et al. 1997; Ghosh et al. 1999; Lawson et al. 1999; Zhu and Carlin 1999; Dey et al. 2000; Sun et al. 2000; Lawson 2001; Green and Richardson 2001). A special issue of Statistics in Medicine
entitled "Disease Mapping with a Focus on Evaluation" was also recently published to report this development (vol. 19, Issues 17–18, 2000).
Among other applications, disease maps have been used to
-
describe the spatial variation in disease incidence for the formulation and validation of etiological hypotheses;
-
identify and rank areas with potentially elevated risk and time trends so that action may be taken; and
-
provide a quantitatively informative map of disease risk in a region to allow better risk assessment, prioritization, and resource allocation in public health.
Clearly, roadway traffic safety planning has similar requirements and can potentially benefit from these kinds of maps.
Studies have shown that risk estimation using hierarchical Bayes models has several advantages over estimation using classical methods. One important point that has been stressed by almost all of these studies is that individual incidences of diseases of concern are relatively rare for a typical analysis unit such as census tract or county. As a result, estimates based on simple aggregation techniques may be unreliable because of large variability from one analysis unit to another. This variability makes it difficult to distinguish chance variability from genuine differences in the estimates and is sometimes misleading for analysis units with a small population size. Hierarchical Bayes models, however, especially those Poisson-based generalized linear models with spatial random effects, have been shown to have the ability to account for the high variance of estimates in low population areas and at the same time clarify overall geographic trends and patterns (Ghosh et al. 1999; Sun et al. 2000).
Note that in the context of sample surveys the type of problem described above is commonly referred to as a small area, local area, or small domain estimation problem. Ghosh and Rao (1994) conducted a comprehensive review of hierarchical Bayes estimations and found them favorable for dealing with small area estimation problems when compared with other statistical methods. Hierarchical models are also gaining enormous popularity in fields such as education and sociology, in which data are often gathered in a nested or hierarchical fashion: for example, as students within classrooms within schools (Goldstein 1999). In these fields, hierarchical models are often called multilevel models, variance component models, or random coefficients models.
The overall strength of the Bayesian approach is its ability to structure complicated models, inferential goals, and analyses. Among the hierarchical Bayes methods, three are most popular in disease mapping studies: empirical Bayes (EB), linear Bayes (LB), and full Bayes methods. These methods offer different levels of flexibility in specifying model structures and complexity in computations. As suggested by Lawson (2001): "While EB and LB methods can be implemented more easily, the use of full Bayesian methods has many advantages, not least of which is the ability to specify a variety of components and prior distributions in the model set-up."
To many statistical practitioners, it is fair to say that the challenges they face dealing with real-world problems come more often from the difficulties of handling nonsampling errors and unobserved heterogeneity (because of the multitude of factors that can produce them) than from handling sampling errors and heterogeneity due to observed covariates. One potential advantage of using the full Bayes model is the flexibility that it can provide in dealing with and adjusting for the unobserved heterogeneity in space and time, whether it is structured or unstructured.
Objectives and Significance of Work
Mapping transforms spatial data into a visual form, enhancing the ability of users to observe, conceptualize, validate, and communicate information. Research efforts in the visualization of traffic safety data, which are usually stored in large and complex databases, are quite limited at this time because of data and methodological constraints (Smith et al. 2001). As a result, it is common for engineers and other traffic safety officials to analyze roadway safety data and make recommendations without actually "seeing" the spatial distribution of the data. This is not an optimal situation.
To the best of our knowledge, unlike the public health community, which has developed models for disease mapping, the roadway safety research community has not done much to develop model-based maps for traffic crash data. One of the objectives of the study presented here was to initiate development of model-based mapping for roadway traffic crashes. Vehicle crash records and roadway inventory data from Texas were used to illustrate the nature of the data, the structure of models, and results from the modeling.
Overall, TxDOT maintains nearly 80,000 centerline-miles of paved roadways, serving about 400 million vehicle-miles per day. Over 63% of the centerline-miles are rural two-lane roads that, on average, carry fewer than 2,000 vehicles per day. These low volume rural roadways carry only about 8% of the total vehicle-miles on state-maintained (or on-system) highways and have less than 7% of the total reported on-system vehicle crashes. Due to the low volume and relatively low crash frequency on these roads, it is often not deemed cost-effective to upgrade these roads to the preferred design standards. However, vehicles on these roadways generally travel at high speeds and thus tend to have relatively more severe injuries when vehicle crashes occur. For example, in 1999, about 26% of the Texas on-system crashes were fatal (K), incapacitating injury (A), and nonincapacitating injury (B) (or KAB) crashes, compared with over 40% of the crashes on rural, two-lane, low volume on-system roads (Fitzpatrick et al. 2001). As a result, we have chosen to focus this study on crashes occurring on rural, two-lane, low-volume, on-system roads.
This paper is organized as follows: the next section briefly describes the sources and nature of the data analyzed in this study, followed by a quick review of modeling and computational techniques and a discussion of Poisson-based hierarchical Bayes model with space-time effects and possible variants. Results from models of various levels of complexities are then presented and compared, and we conclude with a discussion of future work.
DATA
The Texas Department of Transportation (TxDOT) currently has 25 geographic districts that are responsible for highway development. The state's 254 counties are divided among the districts
(figure 1). Each district includes 6 to 17 counties. District offices divide their work into area offices and area offices into local maintenance offices. The variety of climates and soil conditions in Texas places differing demands on its highways, so design and maintenance, right-of-way acquisition, construction oversight, and transportation planning are primarily administered and accomplished locally.
Annual KAB crash frequencies for rural, two-lane, low volume on-system roads at the county
level from 1992 to 1999 were used for modeling in this study.
Figure 2 shows the number of reported KAB crashes by county in 1999, while
figure 3 shows total vehicle-miles incurred for the same year (in millions of
vehicle-miles traveled, or MVMT). In a bubble plot, figure 4 shows the highest, lowest,
and average of the "raw" annual KAB crash rates by county (in number of crashes
per MVMT). Note that two of the urban counties and one rural county were removed from the
analysis for having no (or almost no) rural two-lane roads with the level of traffic volume
of interest, i.e., fewer than 2,000 vehicles per day on average.
As shown in
figure 4, crash rates in most counties were stable over the
eight-year period, while several counties exhibited marked differences between the high and
the low. There is a clear east-west divide in terms of the KAB crash rates, with eastern
counties on average showing considerably higher rates. Rural roadways in the eastern
counties are limited by the rolling terrain and tend to have less driver-friendly
characteristics, with more horizontal and vertical curves
(figures 5 and
6), restricted sight distance, and less forgiving roadside development (e.g., trees closer to the travelway and steeper side slopes). In addition, with more and larger urbanized areas in the east, rural roads tend to have higher roadside development scores, higher access density, and narrower lanes and/or shoulders (Fitzpatrick et al. 2001). In general, northern and eastern counties have higher proportions of wet-weather-related crashes
(figure 7). Also, on average, rural roads in eastern counties were found to have more crashes at intersections than western
counties (figure 8).
The National Highway System Designation Act of 1995 repealed the national maximum speed limit and returned authority to set speed limits to the states. In early 1996, speed limits on many Texas highways during daylight hours were raised from 55 mph to 70 mph for passenger vehicles and 60 mph for trucks. In a study using monthly time series data from January 1991 to March 1997, it was shown that for those roads on which speed limits were raised, the number of KAB crashes increased in five out of the six highway categories studied during the post-intervention periods (Griffin et al. 1998). The speed limit increase also coincided with a 14% jump in speed-related fatalities, from 1,230 in 1995 to 1,403 in 1996. The number of speed-related injuries increased during that period as well: 3.3% for incapacitating injuries and 7.0% for nonincapacitating injuries. Thus, for the low volume roads considered by this study, we expected to see a change in KAB crash rates in 1996.
MODEL
As part of our modeling efforts, we developed a Poisson hierarchical Bayes model for traffic crash risk mapping at the county level for state-maintained rural, two-lane, low volume roads (fewer than 2,000 vehicles per day) in Texas. In general, the model consists of six components:
- an offset term (i.e., a covariate with a fixed regression coefficient equal to 1), representing the amount of travel
occurring on these roads;
- a fixed TxDOT district effect;
- a fixed or random covariate effect component modeling the spatial variation in crash risk due to spatial differences in number of wet days, number of sharp horizontal curves, and
degrees of roadside hazards;
- one random spatial effect component using the inverse of the Great Circle distance between the centroid of counties as the weights for
determining spatial correlations;
- a fixed or random time effect component representing year-to-year
changes; and
- an exchangeable random effect term, which, for the purpose of this study, can be deemed as a pure independent random local space-time variation that is independent of all
other components in the model.
In this paper, we consider a fixed effect as an effect that is subject only to the
uncertainty associated with an unstructured noninformative prior distribution with no
unknown parameters and the sampling
variation.1 A fixed effect can, however, vary by individual districts, counties, and time periods (see the discussion of model hierarchy). Note also that unlike the traditional traffic crash prediction models (Maher and Summersgill 1996; Miaou 1996; and Hauer 1997), which were concerned principally with modeling the fixed effects for individual sites (e.g., road segments or intersections), this study focuses more on exploring the structure of the random component of the model for area-based data.
The rediscovery by statisticians in the last 15+ years of the Markov chain Monte Carlo (MCMC) methods and new developments, including convergence diagnostic statistics, are revolutionizing the entire statistical field (Besag et al. 1995; Gilks et al. 1996; Carlin and Louis 1996; Roberts and Rosenthal 1998; Robert and Casella 1999). At the same time, improved computer processing speed and lower data-collection and storage costs are allowing more complex statistical models to be put into practice. These complex models are often hierarchical and high dimensional in their probabilistic and functional structures. Furthermore, many models also need to include dynamics of unobserved and unobservable (or latent) variables; deal with data distributions that are heavily tailed, highly overdispersed, or multimodal; and work with datasets with missing data points. MCMC provides a unified framework within which model identification and specification, parameter estimation, performance evaluation, inference, prediction, and communication of complex models can be conducted in a consistent and coherent manner.
With today's desktop computing power, it is relatively easy to sample the posterior distributions using MCMC methods that are needed in full Bayes methods. The advantage of full Bayesian treatment is that it takes into account the uncertainty associated with the estimates of the random-effect parameters and can provide exact measures of uncertainty. Maximum likelihood methods, on the other hand, tend to overestimate precision, because they ignore this uncertainty. This advantage is especially important when the sample size is small. Other estimation methods for hierarchical models are also available, e.g., iterative generalized least squares (IGLS), expected generalized least squares (EGLS), and generalized estimating equations (GEE). These estimation procedures tend to focus on obtaining a consistent estimate of the fixed effect rather than exploring the structure of the random component of the model (Goldstein 1999).
For some problems, existing software packages such as WinBUGS (Spiegelhalter et al. 2000) and MLwiN (Yang et al. 1999) can provide Gibbs and other MCMC sampling for a variety of hierarchical Bayes models. For the models presented in this paper, we relied solely on the WinBUGS codes. At present, however, the type of spatial and temporal models available in WinBUGS is somewhat limited and will be discussed later.
Notations
We let the indices i, j,
and t
represent county, TxDOT district, and time period, respectively,
where i
= 1,2,...,I; j
= 1,2,...,J;
and t
= 1,2,...,T.
For the data analyzed, we have 251 counties, divided among 25 districts, and 8 years of annual data (i.e., I
= 251, J
= 25, and T
= 8). As indicated earlier, each district may include 6 to 17 counties, which will be represented by county
set D
j, where j
= 1,2,...,25. That is, D
j
is a set of indices representing counties administered by TxDOT district j.
We define variable Y
it
as the total number of reported KAB crashes on the rural road of interest in county i
and year t.
We also define v
it
as the observed total vehicle-miles traveled (VMT) in county i
and year t
for the roads in discussion, representing the size of the population at risk. In addition, we define x
itk
as the k
th covariate associated with county i
and year t.
Three covariates were considered.
Covariates
The first covariate x
it1
is a surrogate variable intended to represent the percentage of time that the road surface is wet due to rain, snow, etc. Not having detailed weather data, we chose to use the proportion of KAB crashes that occurred under wet pavement conditions as a surrogate variable. In addition, we do not expect general weather characteristics to vary much between neighboring counties. Therefore, the proportion for each county is computed as the average of this and six other neighboring counties that are close to the county in terms of their Great Circle distances. We do, however, expect weather conditions to vary significantly from year to year. Thus, for each county i,
we have x
it1
change with t.
The second covariate x
it2
is intended to represent spatial differences in the number of sharp horizontal curves in different counties. The actual inventory of horizontal curves on the highway network is not currently available. However, when a traffic crash occurs, site characteristics including the horizontal curvature are coded in the traffic crash database. We chose to use the proportion of KAB crashes that occurred on sharp horizontal curves in each county as a surrogate variable, and we define a sharp horizontal curve as any road segment having a horizontal curvature of 4 or higher degrees per 100-foot arc. Given that this roadway characteristic is mainly driven by terrain variations, we do not expect this characteristic to vary much between neighboring counties. Therefore, as in the first covariate, the proportion for each county is computed as the average of this and six other neighboring counties that are close to the county in terms of their Great Circle distances. Furthermore, for this type of road, we did not expect the proportion to vary in any significant way over the eight-year period in consideration. Thus, the average proportion from 1992 to 1999 was actually used for all t.
In other words, for each county i, x
it2
are the same for all t.
The third covariate x
it3
is a surrogate variable intended to represent degrees of roadside hazards. As in the second covariate, the actual inventory of hazards (ditches, trees, and utility poles), available clear zones, and geometry and surface type of roadsides are not available. Similar to the first covariate, a surrogate variable was devised to indicate the proportion of KAB crashes that ran off roads and hit fixed objects on the roadside. We also do not expect this characteristic to vary much between neighboring counties over the eight-year period in consideration. Again, the average proportion from 1992 to 1999 was used for all t,
i.e., for each county i, x
it3
are the same for all t.
Figure 9 shows the spatial distribution of this variable.
The use of these surrogate variables is purely data driven (as opposed to theory driven) and empirical in nature. We use the proportion of wet
crashes (x
it1) as an example to explain the use and limitation of such surrogate measures in practice. First, variables such as "percentage of wet crashes" and "wet crashes to dry crashes ratio" are commonly used in wet-weather accident studies. Examples in the literature include Coster (1987), Ivey and Griffin (1990), and Henry (2000). These authors reviewed various wet-weather accident studies, and the relationships between 1) skid numbers (or friction values) of pavement and percentage of wet weather accidents, and 2) skid numbers and wet/dry pavement surfaces were quite well documented. Although they were conducted with limited data, these wet weather accident studies also suggest that crash rates are higher during wet surface conditions than under dry surface conditions, and some indicate that traffic volumes are reduced by about 10% to 20% during wet weather in rural areas (no significant reduction was found in urban areas).
Second, the use of percentage of wet crashes as a surrogate variable in this study to explain the variation of crash rates by county mixes several possible relationships and has limited explanatory power. A positive correlation of percentage of wet crashes and crash rate mixes has at least two possible relationships: 1) the effect of wet surface conditions on crash rates, and 2) the effect of rainfall (or other precipitation) on traffic volumes. Everything else being equal, if the wet surface crash rate is the same as the dry surface crash rate, then we do not expect this positive correlation to be statistically significant in the model regardless of the relative traffic volumes during wet or dry surface conditions. We interpret a positive correlation as an indication that a higher crash rate is indeed experienced during wet surface conditions than during dry conditions. However, because of the lack of data on traffic volumes by wet and dry surface conditions, we are not able to quantify the difference in crash rates under the two surface conditions. This is the main limitation in using such a surrogate measure.
Probabilistic and Functional Structures
The space-time models considered in this study are similar to the hierarchical Bayes generalized linear model used in several disease mapping studies cited earlier. At the first level of hierarchy, conditional on
mean μit,
Yit values are assumed to be mutually independent and Poisson distributed as
 (1)
(1)
The mean of the Poisson is modeled as
μit = νitλit (2)
where total VMT v
it
is treated as an offset and λit
is the KAB crash rate. The rate, which has to be non-negative, is further structured as

 (3)
(3)
where log is the natural logarithm, I(S)
is the indicator function of the set S defined as
 (4)
(4)
This makes the first term on the right hand side of equation 3 the intercept representing district effects at
different years; xitk
are covariates discussed earlier and their interactions; δt
represents year-to-year time effects due, e.g., to speed limit, weather, and socioeconomic
changes; φi
is a random spatial effect; eit
is an exchangeable, unstructured, space-time random effect;
and αjt
and βk
are regression parameters to be estimated from the data. As defined earlier, Dj
is a set of indices representing counties administered by TxDOT district j.
Many possible variations of equation 3 were and could potentially be considered in this study. For each component that was assumed to have a fixed effect, the second level of hierarchy was chosen to be an appropriate noninformative prior. On the other hand, for each component that was assumed to have a random effect, the second level of hierarchy was a prior with certain probabilistic structure that contained unknown parameters. The priors for these unknown parameters (called hyperpriors) constitute the third level of the hierarchy. What follows are discussions of the variation of models considered by this study, some limitations of the WinBUGS software, and possible extensions of the models considered.
The intercept term, which represents the district effect over time, was assumed to have fixed effects with noninformative normal priors. For the covariates
xitk, we considered both fixed and random effects. That
is, βk
was assumed to be either a fixed value or random variable. The three covariates discussed earlier and three of their interactive
terms, xit4
= xit1xit2,
xit5
= xit1xit3, and
xit6
= xit2xit3, were included in the model. It
is important to note that the values of these covariates were centered for better numerical performance. Noninformative normal priors were also assumed for fixed-effect models. For the random-effect
model, βk, k
= 1,2,...,6, are assumed to be independent and normally distributed with
mean  and variance
and variance  , expressed as N
(
, expressed as N
( ,
,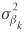 ). Noninformative normal and inverse gamma priors (or more precisely hyperpriors) were assumed
for
). Noninformative normal and inverse gamma priors (or more precisely hyperpriors) were assumed
for 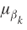 and
and  , respectively.
, respectively.
With 251 counties and 8 years of data, the data are considered to be quite rich spatially but rather limited temporally, as are data in many disease mapping studies. Because of this limitation, we only considered two simple temporal effects
for δt
: fixed effects varying by t
(or a year-wise fixed-effect model) and an order-one autoregressive model (AR(1)) with the same coefficient for all t.
Again, noninformative priors were used for both models. For the model to be identifiable, in the fixed-effect
model, δ1
was set to zero, and in the AR(1) model, δ1
was set to be an unknown fixed constant. From the fixed effect, we expected to see a change
in δt
at t
= 5 (1996), due in part to the speed limit increase in that year.
Recent disease mapping research has focused on developing more flexible,
yet parsimonious, spatial models that have attractive statistical properties. Based on the Markov random field (MRF) theory, Besag's conditional autoregressive (CAR) model (Besag 1974 and 1975) and its variants are by far the most popular ones adopted in disease mapping. We considered several Gaussian CAR models, all of which have
the following general form
 (5)
(5)
where  is the conditional probability
of φi
given φ-i;
is the conditional probability
of φi
given φ-i;
φ-i
represents all φ
except φi,
 stands for "proportional to,"
stands for "proportional to,"
Ci
is a set of counties representing "neighbors" of county i,
η
is a fixed-effect parameter across all i,
and
ωii*
is a positive weighting factor associated with the county
pair (i, i*).
This equation is shown to be equivalent to

where 
 , and , and
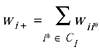 . .
In our study, we had  , ,
where dii*
is the Great Circle distance between the centroid of county i
and i*, and c
is a constant parameter equal to 1 or 2 (note
that dii*
ranges roughly from 30 to 700 miles.)
With regard to the number of neighbors, we adopted a more generous definition by allowing every other
county i* (≠i) to be a neighbor of county i.
In theory, we could treat the constant c
as an unknown parameter and estimate it from the data. However, in the current version of WinBUGS, the weights of the built-in CAR spatial model do not allow unknown parameters (Spiegelhalter et al. 2000), which we found to be a limitation for our application. In a separate attempt to find a good range of the decay constant for the inverse distance weight in the CAR model, we adopted a simpler model that included only the offset, the yearwise time effect, and the Gaussian CAR components. We estimated the same model with different c
values between 0 and 4 and found that model performance was best achieved when the decay constant was set between 1 and 2 (based on the deviance information criterion to be discussed shortly). Weights with an exponential
form ωii* = exp(-cdii*)
were also examined but are not reported in this paper.
We also explored the L-1 CAR models of the following form:
 (6)
(6)
where η is a fixed-effect parameter the same for all i.
Weights with the same c
as in the Gaussian CAR models were considered. WinBUGS constrains the sum
of φi
to zero to make both the Gaussian CAR and L-1 CAR spatial models identifiable. A non-informative gamma distribution was used as hyperpriors
for η
in equations 5 and 6.
The spatial correlation structure represented by equations 5 and 6 is considered global in the sense that the distribution functions and associated parameters
(c and η) do not change by i.
More sophisticated models allowing spatial correlation structure to be adaptive or location specific are being actively researched (e.g., Lawson 2000; Green and Richardson 2001). Still, computational challenges seem to be keeping researchers from exploring more flexible, yet parsimonious, space-time interactive effects, and more research in this area needs to be encouraged (Sun et al. 2000).
For the exchangeable random effects, we considered two commonly used distributions. One distribution assumed
eit
to be independent and identically distributed (iid) as
 (7)
(7)
Another distribution assumed an iid
one-parameter gamma distribution as
 (8)
(8)
which has a mean equal to 1 and a variance 1/ψ.
The use of a one-parameter gamma distribution (instead of a two-parameter gamma) ensures that all model parameters are identifiable. Again, non-informative inverse gamma and gamma distributions were used as hyperpriors
for  and ψ, respectively.
and ψ, respectively.
Deviance Information Criterion
and Variants
The deviance information criterion (DIC) has been proposed to compare the fit and complexity (measured by the effective number of parameters) of hierarchical models in which the number of parameters is not clearly defined (Spiegelhalter et al. 1998; Spiegelhalter et al. 2002). DIC is a generalization of the well-known Akaike Information Criterion (AIC) and is based on the posterior distribution of the deviance statistic
![uppercase d (lowercase theta) = negative 2 lowercase log [lowercase rho (lowercase y vertical bar lowercase theta)] + 2 lowercase log [lowercase f (lowercase y)]](https://webarchive.library.unt.edu/eot2008/20081021034341im_/http://www.bts.gov/publications/journal_of_transportation_and_statistics/volume_06_number_01/images/Miaou-66.gif)
where  is the likelihood function for the observed data vector y given the parameter
vector θ, and
is the likelihood function for the observed data vector y given the parameter
vector θ, and
f(y) is some standardizing function of the data alone. For the Poisson
model, f(y) is usually set as the saturated likelihood,
i.e., 
where μ
is a vector of the statistical means of vector y.
DIC is defined as a classical estimate of fit plus twice the effective number of parameters, which gives
 (9)
(9)
where 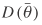 is the deviance evaluated at
is the deviance evaluated at  , the posterior means of the parameters of interest; , the posterior means of the parameters of interest;
p
D is the effective number of parameters for the model;
and
 is the posterior mean of the deviance
statistic
is the posterior mean of the deviance
statistic 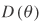 . .
As with AIC, models with lower DIC values are preferred. From equation 9, we
can see that the effective number of
parameters pD
is defined as the difference between the posterior mean of the
deviance  and the deviance at the posterior means of the parameters of
interest
and the deviance at the posterior means of the parameters of
interest  .
It was shown that in nonhierarchical models (or models with negligible prior information)
DIC is approximately equivalent to AIC. It has also been emphasized that the quantity
of pD
can be trivially obtained from an MCMC analysis by monitoring
both θ and D(θ)
during the simulation. For the random-effect model considered in equations 1 through 3, the parameter
vector θ
should include αjt, βk,
δt, φi
and eit
for all i, j, k,
and t. .
It was shown that in nonhierarchical models (or models with negligible prior information)
DIC is approximately equivalent to AIC. It has also been emphasized that the quantity
of pD
can be trivially obtained from an MCMC analysis by monitoring
both θ and D(θ)
during the simulation. For the random-effect model considered in equations 1 through 3, the parameter
vector θ
should include αjt, βk,
δt, φi
and eit
for all i, j, k,
and t.
In addition to DIC values and associated
quantities  , ,
 ,
and pD, we also used some goodness-of-fit measures
that attempted to standardize DIC in some fashion. This includes DIC divided by sample size n
and ,
and pD, we also used some goodness-of-fit measures
that attempted to standardize DIC in some fashion. This includes DIC divided by sample size n
and 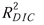 ,
which is defined as ,
which is defined as
 (10)
(10)
where DICmodel
is the DIC value for the model under evaluation;
DICmax
is the maximum DIC value under a fixed one-parameter model; and
DICref
is a DIC value from a reference model that, ideally, represents some expected lower bound of the Poisson hierarchical model for a given dataset.
Clearly,  is devised in the spirit of the traditional R2
goodness-of-fit measure for regression models. Through simulations, Miaou (1996)
evaluated several similar measures using AIC for overdispersed Poisson models. Since DIC is
known to be noninvariant with respect to the scale of the data (Spiegelhalter et al. 1998;
Spiegelhalter et al. 2002), an analytical development
of DICref
is difficult. However, we know that for a model with a good
fit,
is devised in the spirit of the traditional R2
goodness-of-fit measure for regression models. Through simulations, Miaou (1996)
evaluated several similar measures using AIC for overdispersed Poisson models. Since DIC is
known to be noninvariant with respect to the scale of the data (Spiegelhalter et al. 1998;
Spiegelhalter et al. 2002), an analytical development
of DICref
is difficult. However, we know that for a model with a good
fit,  should be close to sample size n
(Spiegelhalter et al. 2002). We, therefore, chose DICref = n
as a conservative measure for
computing
should be close to sample size n
(Spiegelhalter et al. 2002). We, therefore, chose DICref = n
as a conservative measure for
computing 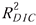 ; that is, the effective number of parameters was essentially ignored. ; that is, the effective number of parameters was essentially ignored.
Another goodness-of-fit indicator considered is 1 / ψ, which is the variance of
exp(eit) under the gamma model, indicating the extent of overdispersion
due to exchangeable random effects. In theory, this value could go to zero when such effects
vanish. Thus, similar
to 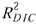 , we can devise the following measure: , we can devise the following measure:
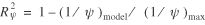
where (1/ψ)model
is the variance of exp(eit) for the model under consideration, and
(1/ψ)max
is the amount of overdispersion under the simplest model.
In essence, 1/ψ)ref, the expected lower bound, is set to zero.
RESULTS
Table 1 lists 42 models of various complexities examined by this study. These models include simplified versions of the general model presented in equations 2 and 3, as well as models for reference purposes, e.g., models 1 to 3. Model 1 is a saturated model, in which the estimates of the Poisson
means  are equal to yit. Model 2, expressed as Alpha0, is a one-parameter Poisson model without the offset, and model 3 is another one-parameter model with the offset. Essentially, model 2 focuses on traffic crash frequency and model 3 on traffic crash rate.
are equal to yit. Model 2, expressed as Alpha0, is a one-parameter Poisson model without the offset, and model 3 is another one-parameter model with the offset. Essentially, model 2 focuses on traffic crash frequency and model 3 on traffic crash rate.
In table 1, the following symbols are used:
-
Alpha(j) stands for fixed district effects.
-
Beta.Fix and Beta.N respectively represent fixed covariate effects and random covariate effects with independent normal priors.
-
Time.Fix and Time.AR1 respectively stand for fixed time and AR(1) time effects.
-
For the random spatial effects, Space.CAR.N1 and Space.CAR.L1, represent the Gaussian and L-1 CAR models shown in equations 5 and 6, respectively, and both have a decay constant c
equal to 1.
-
Space.CAR.N2 and Space.CAR.L2 represent similar spatial models with a decay constant c
equal to 2.
-
The components e.N and e.Gam represent exchangeable random effects as presented in equations 7 and 8, respectively.
We experienced some computational difficulties for the models that included the Beta.N component when we tried to include all six main and interactive effects. Therefore, for all models with the Beta.N component, we only included the three main effects.
In computing  ,
DICmax
is defined as the maximum DIC value under a fixed one-parameter model, which is model 2 in the table when crash frequency is the focus and model 3 when crash rate is the focus. Similarly, in
computing ,
DICmax
is defined as the maximum DIC value under a fixed one-parameter model, which is model 2 in the table when crash frequency is the focus and model 3 when crash rate is the focus. Similarly, in
computing  ,
(1/ψ)max
is set as the amount of overdispersion under the simplest model with an e.Gam error component, which is model 11 for models focusing on the
crash rate. ,
(1/ψ)max
is set as the amount of overdispersion under the simplest model with an e.Gam error component, which is model 11 for models focusing on the
crash rate.
As a rule, in our development we started with simpler models, and the posterior means of the estimated parameters of these simple models were then used to produce initial values for the MCMC runs of more complex models. In general, the models presented in the table are ordered by increasing complexity: intercepts only, intercepts + covariate effect, intercepts + covariate effect + exchangeable effect, intercepts + covariate effect + exchangeable effect + spatial/temporal effects, and so on. Models 7 to 9 and the last eight models include a more complex fixed-effect intercept term. The models are presented in the table in line
with the order in which they were estimated with the WinBUGS codes.
The MCMC simulations usually reached convergence quite quickly. Depending on the complexity of the models, for typical runs, we performed 10,000 to 20,000 iterations of simulations and removed the first 2,000 to 5,000 iterations as burn ins. As in other iterative parameter estimation approaches, good initial estimates are always the key to convergence. For some of the models, we have hundreds of parameters and MCMC monitoring plots based on the Gelman-Rubin statistics (which are part of the output from the WinBUGS codes). Because estimated parameters usually converge rather quickly, their convergence plots, which are not particularly interesting to show, are not presented here.
Table 2 shows some statistics of the estimated posterior density of a selected
number of parameters for model 27, which was one of the best models in terms of the DIC value and
other performance measures discussed above. Also,
figure 10 presents estimated posterior mean
crash rates, as well as their 2.5 and 97.5 percentiles, in a bubble plot for 1999 by county.
From table 2, one can see that the fixed-time
effect δt
jumps from about 0 in previous years to about 0.05 in t
= 4 (1995) and has another increase to about 0.09 at t
= 5 (1996). The value comes down somewhat (about 0.06) in 1998 (t
= 7) and 1999 (t
= 8) but is still significantly higher than those in the preintervention periods. It has been suggested that the jump in 1995 was perhaps due to higher driving speeds by drivers in anticipation of a speed limit increase, and higher crash rates in 1996 were due in part to the speed limit increase and less favorable winter weather (Griffin et al. 1998).
Lower δt
values in 1998 and 1999 may suggest that drivers had adjusted themselves
and become more adapted to driving at higher speeds.
From the same model (model 27), estimates of αj,
i.e., district effects, range from about –0.5 to –1.5, indicating significant district-level variations in crash risk. The covariate
effects βk
indicate that the horizontal curve variable is the most influential and statistically significant variable in explaining the crash rate variations over space. Wet pavement condition is the second-most significant variable. The ran-off-road fixed-object variable is not a statistically significant variable, which suggests that ran-off-road fixed-object crash risk is correlated with and perhaps exacerbated by the presence of sharp horizontal curves and wet pavement conditions.
From DIC and other performance measures in table 1, several observations can be made:
-
For the exchangeable random effect, models with a gamma assumption (equation 8) are preferred over those with a normal assumption (equation 7). This is observed by comparing the performance of, e.g., model 15 with model 14, model 18 with model 17, and model 27 with model 26.
-
Models with fixed covariate effects are favored over their random-effect counterparts. This is seen by comparing, e.g., model 25 with model 24 and model 33 with model 34.
-
Models with fixed time effects (e.g., model 23) performed better than those with AR(1) time effects (e.g., model 22).
-
Models with separate district and time effects (αj
and δt) are preferred over those with joint district time
effects (αjt). For example, we can compare the performance
of model 27 with model 42 and model 40 with model 24.
-
For comparable model structures, adding a spatial component decreases the DIC value quite significantly, which indicates the importance of the spatial component in the model. As an example, we can compare model 17 with model 20. Except for the spatial component, these two models have the same structures (in intercept terms, covariate effects, and the error component). Model 17 does not have any spatial component, while model 20 includes a normal CAR model. The DIC value drops from 3,287 for model 17 to 2,755 for model 20, a very significant reduction when compared with the differences in DIC values for various models presented in table 1. Other comparisons that would give the same conclusion include model 19 vs. model 22 or model 38 with models 40 and 42.
-
No particular spatial CAR models considered by this study, i.e., CAR.N1, CAR.L1, CAR.N2, or CAR.L2, were clearly favored over other CAR models.
-
Despite the empirical nature of the two goodness-of-fit measures
 and
and 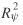 , seeing some of the better models that have values exceeding 0.9 provides some
comfort as to the general explanatory capability of these models. , seeing some of the better models that have values exceeding 0.9 provides some
comfort as to the general explanatory capability of these models.
DISCUSSION
Most of the methodologies developed in disease mapping were intended for area-based data, e.g., number of cancer cases in a county or census tract during a study period. While we demonstrate the use of some of these methodologies for roadway traffic crashes at the county level, we recognize that, fundamentally, traffic crashes are network-based data, whether they are intersection, intersection-related, driveway access-related, or nonintersection crashes.
Figure 11 gives an example of the locations
of KAB crashes on the state-maintained highway network of a Texas county in 1999.
Thus, an obvious extension of the current study is to develop risk maps for traffic crashes on road networks. The problem is essentially one of developing hierarchical models for Poisson events on a network (or a graph). We expect that, in different applications, these maps may need to be developed by roadway functional classes, vehicle configurations, types of crashes (e.g., those involving drunk drivers), and crash severity types (e.g., fatal, injury, and noninjury crashes). We also expect these network-based maps to be useful for roadway safety planners and engineers to 1) estimate the cost and benefit of improving or upgrading various design and operational features of the roadway, 2) identify and rank potential problem roadway locations (or hotspots) that require immediate inspection and remedial action, and 3) monitor and evaluate the safety performance of improvement projects after the construction is completed. Such maps need to be constructed from quality accident-, traffic-, and roadway-related databases and with scientifically grounded data visualization and modeling tools.
Modeling and mapping of traffic crash risk need to face all the challenges just as in the field of disease mapping, i.e., multilevel data and functional structures, small areas of occurrence of studied events at each analysis unit, and strong unobserved heterogeneity. The hierarchical nature of the data can be described as follows: In a typical roadway network, other than the fact that roadway networks are connected or configured in specific ways, individual road entities are classified by key geometric characteristics (e.g., segments, intersections, and ramps), nested within roadway functional or design classifications, further nested within operational and geographical units, and subsequently nested within various administrative and planning organizations. Strong unobserved heterogeneity is expected because of the unobserved driver behaviors at individual roadway entities that are responsible for a large percentage of crash events.
Every state maintains databases on vehicle crash records and roadway inventory data. We hope that the results of our study using Texas data will motivate the development of similar studies in other states. We also envision that the network-based hierarchical models we propose can potentially be utilized in other transportation modes and in computer and communication network studies to further the exploration and interpretation of incidence data. Furthermore, the hierarchical Bayes models with spatial random effects described in this paper can be used to develop more efficient sampling surveys in transportation that alleviate multilevel and small-area problems. Finally, the models have been shown to have the ability to account for the high variance of estimates in low-population areas and at the same time clarify overall geographic trends and patterns, which make them good tools for addressing some of the equity issues required by the Transportation Equity Act for the 21st Century.
ACKNOWLEDGMENTS
This research was supported in part by the Bureau of Transportation Statistics, U.S. Department of Transportation, via transportation statistics research grant number DTTS-00-G-B005-TX. The authors are, however, solely responsible for the contents and views expressed in this paper.
REFERENCES
Besag, J. 1974. Spatial Interaction and the Statistical Analysis of Lattice Systems (with Discussion). Journal of the Royal Statistical Society. Series B
36:192–236.
Besag, J. 1975. Statistical Analysis of Non-Lattice Data. Statistician
24(3):179–195.
Besag, J., P. Green, D. Higdon, and K. Mengersen. 1995. Bayesian Computation and Stochastic Systems (with Discussion). Statistical Science
10:3–66.
Carlin, B.P. and T.A. Louis. 1996. Bayes and Empirical Bayes Methods for Data Analysis.
London, England: Chapman and Hall/CRC.
Coster, J.A. 1987. Literature Survey of Investigations Performed to Determine the Skid Resistance/Accident Relationship, Technical Report RP/37. National Institute for Transport and Road Research, South Africa.
Dey, D., S. Ghosh, and B.K. Mallick. 2000. Bayesian Generalized Linear Model.
New York, NY: Marcel Dekker.
Evans, L. 1991. Traffic Safety and the Driver.
New York, NY: Van Nostrand Reinhold.
Fitzpatrick, K., A.H., Parham, M.A. Brewer, and S.P. Miaou. 2001. Characteristics of and Potential Treatments for Crashes on Low-Volume, Rural Two-Lane Highways in Texas, Report Number 4048-1. Texas Transportation Institute, College Station, TX.
Gelman, A., J.B. Carlin, H.S. Stern, and D.B. Rubin. 1995. Bayesian Data Analysis,
1st ed. Boca Raton, FL: CRC Press.
Ghosh, M., and J.N.K. Rao. 1994. Small Area Estimation: An Appraisal. Statistical Science
9(1):55–76.
Ghosh, M., K. Natarajan, L.A. Waller, and D. Kim. 1999. Hierarchical Bayes for the Analysis of Spatial Data: An Application to Disease Mapping. Journal of Statistical Planning and Inference 75:305–318.
Gilks, W.R., S. Richardson, and D.J. Spiegelhalter. 1996. Markov Chain Monte Carlo in Practice.
London, England: Chapman and Hall.
Goldstein, H. 1999. Multilevel Statistical Models,
1st Internet edition. Available at
http://www.ioe.ac.uk/multilevel/.
Green, P.J. and S. Richardson. 2001. Hidden Markov Models and Disease Mapping, Working Paper. Department of Mathematics, University of Bristol, United Kingdom.
Griffin, L.I., O. Pendleton, and D.E. Morris. 1998. An Evaluation of the Safety Consequences of Raising the Speed Limit on Texas Highways to 70 Miles per Hour, Technical Report. Texas Transportation Institute, College Station, TX.
Hauer, E. 1997. Observational Before-After Studies in Road Safety.
New York, NY: Pergamon Press.
Henry, J.J. 2000. Design and Testing of Pavement Friction Characteristics,
NCHRP Project 20-5, Synthesis of Highway Practice, Topic 30-11. Washington, DC: Transportation Research Board.
Ivey, D.L. and L.I. Griffin, III. 1990. Proposed Program to Reduce Skid Initiated Accidents in Texas.
College Station, TX: Texas Transportation Institute.
Knorr-Held, L. and J. Besag. 1997. Modelling Risk from a Disease in Time and Space, Technical Report. Department of Statistics, University of Washington.
Lawson, A.B., A. Biggeri, D. Bohning, E. Lessafre, J.F. Viel, and R. Bertollini, eds. 1999. Disease Mapping and Risk Assessment for Public Health.
Chichester, UK: Wiley.
Lawson, A.B. 2000. Cluster Modelling of Disease Incidence via RJMCMC Methods: A Comparative Evaluation. Statistics in Medicine
19:2361–2375.
____. 2001. Tutorial in Biostatistics: Disease Map Reconstruction. Statistics in Medicine
20:2183–2204.
Maher, M.J. and L. Summersgill. 1996. A Comprehensive Methodology for the Fitting of Predictive Accident Models. Accident Analysis & Prevention
28(3):281–296.
Miaou, S.P. 1996. Measuring the Goodness-of-Fit of Accident Prediction Models, FHWA-RD-96-040. Prepared for the Federal Highway Administration, U.S. Department of Transportation.
National Safety Council (NSC). 2002. Report on Injuries in America, 2001.
Available at http://www.nsc.org/library/rept2000.htm, as of July 2003.
Robert, C.P. and G. Casella. 1999. Monte Carlo Statistical Methods.
New York, NY: Springer-Verlag.
Roberts, G.O. and J.S. Rosenthal. 1998. Markov Chain Monte Carlo: Some Practical Implications of Theoretical Results. Canadian Journal of Statistics
26:5–31.
Smith, R.C., D.L. Harkey, and B. Harris. 2001. Implementation of GIS-Based Highway Safety Analyses: Bridging the Gap, FHWA-RD-01-039. Prepared for the Federal Highway Administration, U.S. Department of Transportation.
Spiegelhalter, D.J., N. Best, and B.P. Carlin. 1998. Bayesian Deviance, the Effective Number of Parameters, and the Comparison of Arbitrarily Complex Models, Research Report 98-009. Division of Biostatistics, University of Minnesota.
Spiegelhalter, D.J., A. Thomas, and N.G. Best. 2000. WinBUGS Version 1.3 User Manual.
Cambridge, UK: MRC Biostatistics Unit. Available at
http://www.mrc-cam.ac.uk/bugs.
Spiegelhalter, D.J., N. Best, B.P. Carlin, and A. Linde. 2002. Bayesian Measure of Model Complexity and Fit. Journal of Royal Statistical Society
64(3):1–34.
Sun, D., R.K. Tsutakawa, H. Kim, and Z. He. 2000. Spatio-Temporal Interaction with Disease Mapping. Statistics in Medicine
19:2015–2035.
Transportation Research Board (TRB). 1987. Designing Safer Roads: Practices for Resurfacing, Restoration, and Rehabilitation,
Special Report 214. Washington, DC: National Research Council.
U.S. Department of Transportation (USDOT), Bureau of Transportation Statistics (BTS). 1996–1999. Transportation Statistics Annual Report.
Washington, DC.
____. 2002. Safety in Numbers Conferences. Available at
http://www.bts.gov/sdi/conferences, as of August 2003.
Xia, H., B.P. Carlin, and L.A. Waller. 1997. Hierarchical Models for Mapping Ohio Lung Cancer Rates. Environmetrics
8:107–120.
Yang, M., J. Rasbash, H. Goldstein, and M. Barbosa. 1999. MLwiN Macros for Advanced Multilevel Modelling, Version 2.0: Multilevel Models Project. Institute of Education, University of London. Available at
http://www.ioe.ac.uk/multilevel/, as of December 1999.
Zhu, L. and B.P. Carlin. 1999. Comparing Hierarchical Models for Spatio-Temporally Misaligned Data Using the DIC Criterion,
Research Report 99-006. Division of Biostatistics, University of Minnesota.
Address for Correspondence and End Notes
Author Addresses: Corresponding author: Shaw-Pin Miaou, Research Scientist, Texas Transportation
Institute, Texas A&M University System, 3135 TAMU, College Station, TX 77843-3135.
Email: s-miaou@tamu.edu.
Joon Jin Song, Research Assistant, Department of Statistics, Texas A&M University,
3143 TAMU, College Station, TX 77843-3143.
Email: j-song@ttimail.tamu.edu.
Bani K. Mallick, Professor, Department of Statistics, Texas A&M University, 3143 TAMU,
College Station, TX 77843-3143. Email: bmallick@stat.tamu.edu.
KEYWORDS: Bayes models, risk, space-time models,
traffic safety.
1.
Bayesian Data Analysis
(Gelman et al. 1995) provides a Bayesian interpretation of fixed and random effects.
|
|

