
This the text of my talk from the Collections as Data: IMPACT. Once the videos of the individual talks are processed and available, we’ll share those with you here — in the meanwhile, you can watch starting at minute 6:45 in the video of the entire event.

Welcome. Published by Currier & Ives. <//www.loc.gov/item/2002698194/>.
Welcome to Collections as Data! When we hosted our first Collections as Data meeting, last year, we explored issues around the computationally processing, analyzing, presenting digital collections. The response overwhelmed us. The topic seemed to strike a chord with many of our colleagues and intersected with other efforts in the field in a fun way. But, still to this day, after a year of talking about this — we’re still struggling to explain it in a way that is tangible to friends and colleagues without direct experience. We’re calling this second iteration “Collections as Data: IMPACT” because we want to get to the heart of why this type of work matters. We’ve invited speakers to tell stories about using data to better their communities and the world.
And in this spirit, I’m going to kick things off with a short story about computation applied to library collections when computers were people doing the calculating, not machines in our pockets. I hope that this will connect the work we’ll discuss today to a longer history to illustrate the power of computation when it’s applied to library collections.

Charles Willson Peale’s portrait of James Madison //www.loc.gov/item/95522332/

Portrait of Alexander Hamilton. The Knapp Co. //www.loc.gov/item/2003667031/
The Federalist Papers, are a collection of essays written by John Jay, Alexander Hamilton, and James Madison. They were published under a pseudonym, Publius, to persuade colonial citizens to ratify the constitution. When changing public opinion converted this documents from anonymous trolling to foundational to our democracy, we started to get a sense of the authorship of the papers.
After the dust settled, 12 remained in dispute between Hamilton and Madison. Hamilton pretty much said they were joint papers, Madison said he didn’t have much to do with them, and lots of people thought Madison actually wrote them. Why so much finger pointing? These were propaganda pieces, and sometimes the authors held public positions that were different from the ones they presented in the papers.
Historical opinion about who wrote what swung back and forth, depending on new evidence that came forward or on the popularity of the given historical figure at the time. As always there is a really interesting story about the sources of historical evidence for authorship. If you’re curious about that, I encourage you to talk to your local librarian.
In 1944, Douglass Adair, an American academic, determined that it was most likely Madison wrote the disputed papers. But the historical evidence was modest, so he sought another way of making an analysis.

He talked to two statisticians to see if there was a computational way to determine authorship.
Frederick Mosteller and David Wallace were intrigued by the idea, and decided to take on the challenge. They thought maybe average sentence length would be a possible indicator, so they laboriously counted sentence length for the known Hamilton and Madison papers, performed some analysis (for example, they had to determine whether quoted sentences counted toward the averages), and did the calculations.
They came up with an average length of 34.5 words for Hamilton and 34.6 words for Madison. So, that wasn’t going to work. Then they tried standard deviation. They thought, although the average length is the same, maybe, for example, one author writes mostly average length sentences and the other, for example lots of teeny tiny sentences and lots of long sentences. Unfortunately, that effort turned out to be a bust, as well. So they shelved the project.
After a few years later, Douglass Adair reached back out to say that he found a tool that could be useful. He found that Hamilton uses the word “while,” and Madison uses “whilst.” This fact, in itself is not enough to determine authorship. The word isn’t used enough in the papers for that to work, and it could have been introduced during the editing process. But it gave them somewhere to start.
The statisticians counted word usage in a screening set of known Madison and Hamilton papers, which I imagine as about as fun as watching paint dry. From that they created a frequency analysis of words used in each authors’ writing. They then determined which words were predictable discriminators and which were what they called “dangerously contextual,” because they were correlated with a certain subject favored by a particular author.
They ended up with 117 words to analyze.
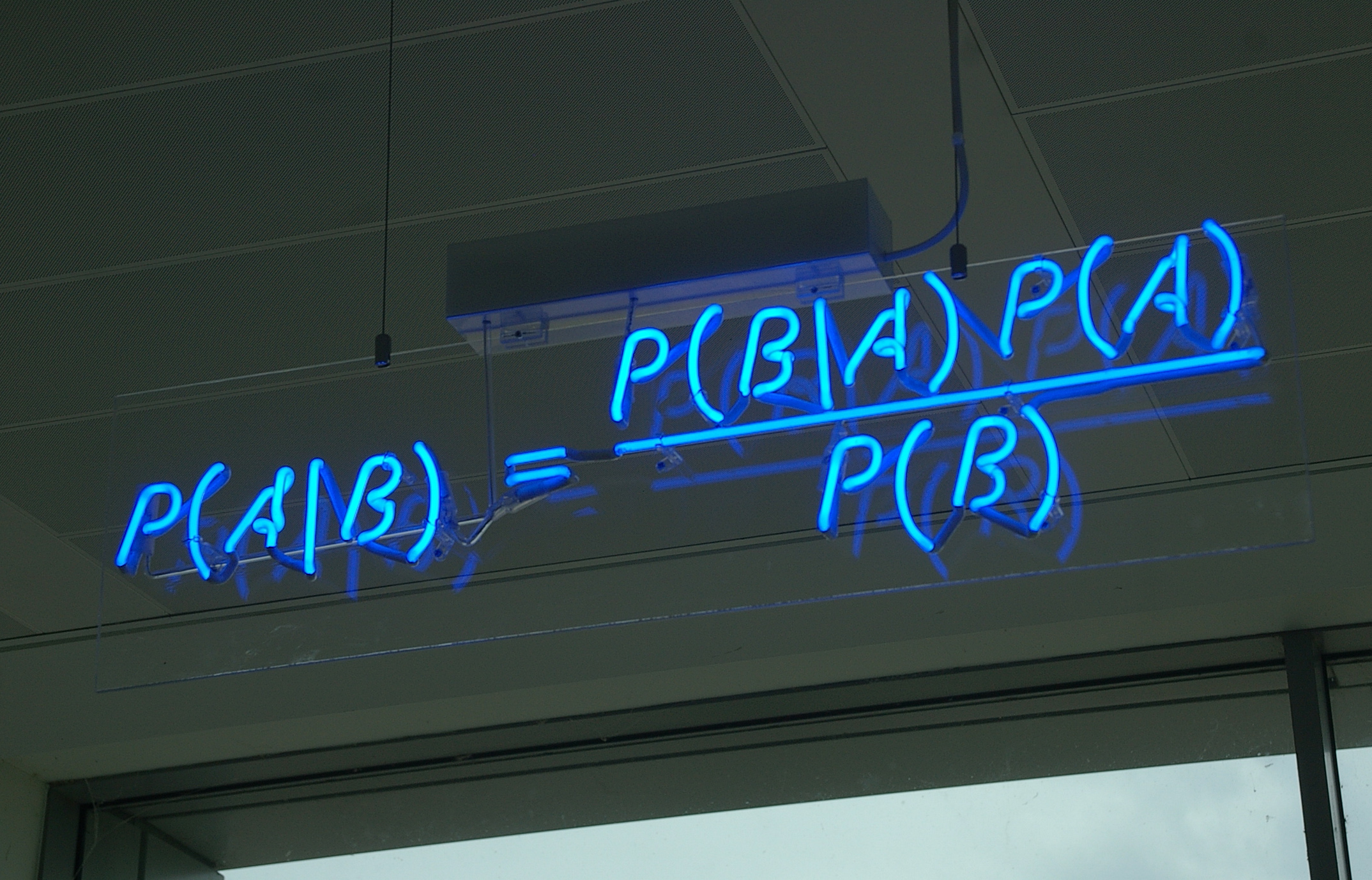
Buck, Matt. Maths in neon at Autonomy in Cambridge. 2009. Photograph. Retrieved from Flickr, https://www.flickr.com/photos/mattbuck007/3676624894/
Using Bayesian statistics, they determined probability of authorship based on the number of times the words appear. If you’re interested in any of this, I encourage you to read the book — it’s very readable and kind of fun.
They concluded that “Our data independently supplement those of the historian. On the basis of our data alone, Madison is extremely likely, in the sense of degree of belief to have written all the disputed Federalists.”
None of this was digital. This was all ink on paper, so it’s one of my favorite example of using collections as data.
What does digital do? It democratizes this kind of analysis, and makes being wrong much less expensive. Which is great! Because we know that being wrong is the cost of being right.
Our heros in this story spent years inventing this analysis, but much of that time was spent laboriously counting word frequencies and hand calculating. Their data set was limited by human scale. Imagine what we could do with lots of data and faster analysis.

Detroit Publishing Co,. City of Detroit III, Gothic room. Photograph. Retrieved from the Library of Congress, //www.loc.gov/item/det1994012547/PP/
This sort of linguistic analysis is now very common. A few years ago, a computer scientist, Patrick Juola, got a call from a reporter asking him if he could show that Robin Galbraith was really J.K, Rowling. He did. And his code is open-source for anyone to use.

Collections as Data graphic created by Natalie Buda Smith, User Experience Manager, Library of Congress //blogs.loc.gov/thesignal/2016/10/user-experience-ux-design-in-libraries-an-interview-with-natalie-buda-smith/
This brings us back to today. What excites me about the possibilities inherit in Collections as Data is that we can now make these kind of intellectual breakthroughs on our laptops. People have been doing this kind of analysis — computational analysis of collections — for a long time. But now, for the first time, we have huge data sets to train our algorithms. We can figure stuff out without having to hand count words in sentences.
And this means that discovery and pay with collections materials becomes even more available to what I consider a core constituency of the Library: the informed and curious.
We’ve invited some academic luminaries here today, and we’re so proud they could join us. We’re learning so much from the ground-breaking work of our colleagues in academic libraries, like our friends working on the IMLS-grant-funded “Always Already Computational: Library Collections as Data” project. But many of our speakers, and many of you out there, don’t have access to well-funded institutional libraries. We hope that you will consider us an intellectual home for exploration.

Canaries & jewels / Marston Ream 1874. //www.loc.gov/item/2003677675/.
We, in my group, National Digital Initiatives, are very inspired by our new boss, Dr. Carla Hayden. She is leading us strongly in a direction toward opening up the collection as much as possible. She talks about this place, lovingly, like the American people’s treasure chest that she is helping to crack open. We in NDI see our responsibility as helping make that happen for our digital and digitized collections. I’d like to tell you about a few things we’re working on.
The first is crowdsourcing.

Screenshot of a development version of Beyond Words, an application created by Tong Wang (with support from Repository Development/OCIO and SGP/LS) on the Scribe platform
We’re working to expand the library’s ability to learn from our users on to more digital platforms. Here’s screenshot of an application that’s still in development, built by Tong Wang, an engineer on the Repository Team at the Library of Congress, while he was a Innovator in Residence in NDI. It invites people to identify cartoons or photographs in historic newspapers and to update the captions. This will enhance findability and also gets us data sets of images that are useful for scholarship. For example, we could create a gallery of cartoons published during WWI.
We’re excited to announce this will be launching late this summer (in beta). This is not the only crowdsourcing project we’re working on (but I’ll save those details for another time). We hope that this work will supplement the other programs LC is using to crowdsourcing its collections, including our presence on Flickr, the American Archive of Public Broadcasting Fix It game, and efforts in Law Library and World Digital Library.

Zwaard, Kate. A view of the Capitol on my way home from work. 2016. Photograph
Our CIO, Bud Barton, announced at this year’s Legislative Data and Transparency Conference that LC will be hosting a competition for creative use of Legislative data. We’re still working on the details, and we should have more to share soon.

National Digital Initiatives hosts a “Hack To Learn” event, May 17, 2017. Photo by Shawn Miller.
I’m thrilled to let you all know that we’ll be launching labs.loc.gov in a few months. In additional to giving a platform to all Library staff for play and experimentation, Labs will be NDI’s home — where we’ll host things like results from our hackathons (like the one pictured here) and experiments by our Innovators in Residence (more on that in a bit).
And now, selfishly, since you’re trapped here, I’d like to share a things LC things that you might find useful.

Palmer, Alfred T, [Operating a hand drill at the North American Aviation, Inc.,]. Oct. Photograph. //www.loc.gov/item/fsa1992001189/PP/
There are a couple of interesting jobs posted right now, and I’d like to encourage you all to apply and share widely. Keep checking back! We need your good brains here, helping us.

Highsmith, Carol M. Great Hall, second floor, north. Library of Congress Thomas Jefferson Building, Washington, D.C. [Between 1980 and 2006] Photograph. //www.loc.gov/item/2011632164/.
Speaking of stuff to apply to, please consider coming here for a short period as a Kluge fellow in digital studies! It’s a paid fellowship for research using LC resources into the impact of the digital revolution on society, cultural, and international relations. Applications are due December 6th. More than one can be awarded each year, so share with your friends.

V. Donaghue. [WPA Art Project]. //www.loc.gov/item/98509756/.
Lastly, I want to mention a program NDI has been working on to bring exciting people to the Library of Congress for short-term, high-impact projects: we call it the Innovators in Residence program. We’re wrapping up some details on this year’s fellowship, and I’ll have more to announce soon. Our vision for the innovator in residence program is to bring bright minds and new blood to the library who can help create more access points to the collection.

Bendorf, Oliver, artist. What does it mean to assemble the whole? 2016. Mixed Media.
So thanks for coming! As I mentioned, we’re working to launch our website, which will make what we’re working on much more easy to follow. In the meanwhile, you can always keep up with the latest news on our blog.
Enjoy the program. And, if you’re using social media today, please use the hashtag #asData