
This is a guest post by Lauren Baker, a Librarian-in-Residence on the Library of Congress Web Archiving Team (a part of the Digital Collections Management & Services Division). The Librarians-in-Residence Program offers early career librarians an opportunity to contribute to Library projects while learning from professionals in the field.
In 2018, the Library of Congress Web Archiving Team embarked on a journey to streamline description of the Library’s voluminous web archives. As part of that continuing effort, the Library of Congress Digital Content Management Section is excited to announce the release of 4,258 new web archives across 97 event and thematic collections! With this release, some of our newer collections are coming out of embargo, and we are making records available for a number of older web archives and collections not previously available for use. This release marks the next significant milestone in the Library’s ability to serve web archives immediately upon exiting their one-year embargo period, garnering momentum for regular, monthly updates coming in 2020.
Discovering Web Archive Collections

Figure 1. The new collections page for the recently launched Women’s and Gender Studies Web Archive at the Library of Congress.
To create a better user experience and make it easier to browse the newly available web archives, we have been working to add collection pages, known as “framework” here at the Library. Framework is a page on the Library’s website that acts as an entry point to a digital collection. It provides researchers with a narrative description and some contextual information about the scope of a collection.
Creating framework is a collaboration between the Web Archiving Team and staff from across the Library of Congress. We collaborate with subject specialists from more than ten different divisions who curate the collections and with colleagues in IT Design & Development, who manage the Library’s web content and post the completed framework to loc.gov to make the collections publicly available. Along with the 4,258 records released, we have nearly doubled the number of web archive collections accessible to users. We created framework for web archives with records previously posted to the Library’s website and for new archives recently released from embargo. For the first time, there are collections on LGBTQ+ studies, veterans history, composers, authors, American business, economics, zines, and many more events and themes!
The creation of so many new collections offered an opportunity to consider how to better describe the web archives at the collection level. Taking cues from our colleagues within the library and in the larger web archiving community (see Peter Webster’s and Jessica Cebra’s work on web archive description), there are four areas where we’ve enriched the collection descriptions:
- frequency of collection
- languages
- acquisition information
- expert resources
We were able to harness information that we already had from the nomination process, crawl logs, and the archives themselves. Below, we’ll show how these four types of enhancements provide users with more information about the archives, make the information provided across the collections more consistent, and enable better search.
Understanding and Using the Collections
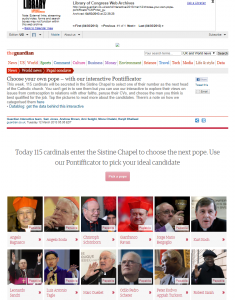
Figure 2. Detail of a one-time capture of The Guardian’s “Choose your own pope – with our interactive Pontifficator” in the Papal Transition 2013 Web Archive.
What can be gleaned from this additional descriptive information? The frequency of collection gives users information about how often the sites were crawled, which is often based on the frequency of updates on the live site by its owners and the depth of information available from those sites. Within a given collection, sites may be crawled at a variety of frequencies. For example, in the Papal Transition 2013 Web Archive, the majority of sites were targeted for capture weekly given that this was an event-based collection where information was changing quickly. Other sites within the collection, including selected Wikipedia pages, Twitter accounts, news sites, and organization websites, were crawled once, which allowed for a more in-depth capture to provide a snapshot in time of this historic announcement.
Languages is a new field added to the collection description that puts the web archive descriptions more in line with archival finding aids. While available at the item level, languages that the content is in may be a determining factor for a researcher to consider if they want to use a collection. Making this information available at the collection level allows this decision to be made earlier in the research process. Language information is crucial for the Afghanistan, Iran, Pakistan Government Web Archive, where sites in the collection contain information in multiple languages. We determined that the most frequently appearing language would appear first followed by additional languages.
Acquisition information can contribute to web archive provenance. We have started including a statement when collections are ongoing to indicate that sites are continuing to be identified and added. In the case of the East European Government Ministries Web Archive, sites for countries and ministries continue to be added incrementally, which means that there are earlier captures and, therefore, more information for some sites. This is an example of how knowing more about a web archive’s origins can help researchers understand what is and is not in the archive.
Expert resources is the final area where we have enhanced the collection descriptions. The more linking the better, in terms of search and discoverability, so we have placed greater emphasis on linking collections to related resources within and outside the Library, including the relevant reading rooms, Ask a Librarian service, LibGuides, related collections, and blog posts about the web archives.

Figure 3. Archives can be a part of more than one collection. The Human Rights Campaign archive shown here is part of five: LGBTQ+ Politics and Political Candidates Web Archive, United States Supreme Court Nominations Web Archive, Public Policy Topics Web Archive, Researcher and Reference Services Division, and Law Library of Congress.
The overlap among collections for specific items can be seen in the various “Part Ofs” listed on an item page in loc.gov. For example, the Human Rights Campaign can be found in no fewer than five collections: LGBTQ+ Politics and Political Candidates Web Archive, United States Supreme Court Nominations Web Archive, Public Policy Topics Web Archive, Researcher and Reference Services Division, and Law Library of Congress. However, with the addition of more precise expert resources, users can also recognize the interconnectedness earlier at the collection level before drilling down into the items. Two newly posted collections – American Music Creators Web Archive and American Music Industry Web Archive – link to one another. The Comics Literature and Criticism Web Archive references the previously posted Webcomics and Small Press Expo Comic and Comic Art Web Archives. As we continue to add to the Library’s web archive, many more links and discoveries will be possible!
Opening the Past & Moving to the Future
And finally, as a part of this release, in our general web archives, we have released a number of non-candidate web archives that were collected during the early United States Election Web Archiving projects. These had been collected off and on from 2000 through 2008 during United States election periods, but in 2010, a decision was made to simply focus our election archiving efforts on campaign websites. While many of the non-candidate sites archived with the election archives moved to the Public Policy Topics Web Archive for regular, ongoing collection, some did not, and we are pleased to finally make this content available for research use.
All of this sets the stage nicely as the Library begins to celebrate its twentieth year of web archiving in 2020. In early 2020, the Web Archiving Team plans to begin monthly, automated updates of content coming out of the one-year embargo and we will continue to release framework for additional collections as their records exit embargo.
In the meantime, and once rolling releases become standard practice at the Library, we will remain committed to improving description of the Library’s web archives to enable better access and ease of use. The exponential growth of the Library’s web archive shows no sign of halting and we are excited to embrace new modes and workflows of description that can help the Library serve the content earlier and more comprehensively.
What information would you like to know about the web archives? In what interesting ways are you able to use the newly released collections? Let us know in the comments and keep watching The Signal for more web archive updates!