
LC Labs is thrilled to welcome Kathleen O’Neill and Chad Conrady aboard our team for the next four months as the 2020 Staff Innovators. Their project, Born Digital Access Now!, will explore methods for providing access to born digital materials in the Manuscript Division and prototype select tools on a digital workstation. They’re working on this project as part of an internal rotational pilot program called the Staff Innovator detail, which gives staff a chance to channel their creativity into carrying out a project of their own design and work towards the Digital Strategy goal of cultivating an innovation culture at the Library of Congress.
This interview with Kathleen and Chad also kicks off a Signal summer series featuring behind-the-scenes interviews with current Library staff, those moving into new positions, and new arrivals such as Junior Fellows, interns, and permanent staff who recently joined the Library. Stay tuned for more stories about the background, experience, and interests of the people that support the Library of Congress in providing enduring access to digital collections and stewarding its digital transformation.
Eileen: Hi, Chad and Kathleen, thanks so much for joining us. Could you begin by introducing yourselves and your past work at the Library?
Kathleen: I’m Kathleen O’Neill, senior archives specialist with the Manuscript Division. Shortly after getting my MLIS from CUNY Queens College, I started at the Library in 2009 as a digital conversion technician. I was with the Digital Conversion team for almost a year when the processing archivist position in the Manuscript Division was posted. My dream job! Though I started out processing paper collections, for the past eight years my primary focus has been building the workflows for the division’s born digital collection material and acting as the born digital workflow coordinator, shepherding these materials through our workflow from accessioning to access.
Chad: I’m Chad Conrady, an archives specialist with the Manuscript Division. I started in the Manuscript Division as a processing archivist in November 2016 and was mentored through my first year by one of the division’s best archivists, Connie Cartledge. In my first year I became familiar with the policies and practices in the Manuscript Division by processing large collections alongside Connie. My first solo processing collection was the Nina V. Fedoroff papers, which was a hybrid (paper/digital) collection. Fedoroff was a molecular biologist who studied transposable elements and stress responses in plants. The collection included all sorts of interesting elements that I was not expecting to see, such as corn kernels given to her from Barbara McClintock, various types of paper and gel electrophoresis, and Macintosh digital files from the late 1980s to the late 2000s.
-

- Kathleen O’Neill, Senior Archives Specialist
-

- Chad Conrady, Archives Specialist
Eileen: You both clearly have immense amounts of experience processing both paper and digital collections. What was the inspiration behind your 2020 Staff Innovator project?
Kathleen: The Manuscript Division has been receiving born digital materials since the late 1990s. The term “born digital” refers to content created and managed in digital form. It’s distinct from “digitized” material, which refers to physical materials that are converted from print or other analog form to digital, for example, VHS tapes that are digitized or photographs that are scanned.
Born digital collection material has inherent, unique challenges related to preservation, appraisal, and access that we will delve into in later blog posts. These challenges required the Manuscript Division build a new workflow to acquire, process, and preserve these materials. Around 2010, the early days of building this workflow, the collections we processed contained simple text and image files that were generally easy to access with file viewers or current software. In addition, the born digital materials themselves were often duplicated in paper or only incidental to the paper portion of the collection. Around 2016, we started to see a shift in the collections from paper based to born digital materials. And with this shift, the born digital materials were arguably of equal, if not greater, research value than the paper materials.
The Manuscript Division’s current focus on processing backlogged materials has led the division to focus on larger, modern collections. These collections naturally contained more, and more complex born digital file formats. We’ve encountered databases, email, and, particularly in the science collections, files created with specialized and obsolete software. These materials are challenging to access on multiple levels and often require specialized tools and operating systems to open and render properly.
So our project, Born Digital Access Now!, is built around a holistic review of the collections in terms of their file formats, restrictions, and the modes of access available at the Library. Our plan is to research and report on each of these areas, and then use that information to characterize the collections, map them to appropriate access pathways, and recommend a standard set of tools that would improve access to, interaction with, and analysis of the born digital collection material. The final project is to create a prototype digital workstation suitable for both researchers and processing archivists.
Chad: When I was working on the Nina Fedoroff papers I used common programs to access text, spreadsheets, and some image files in the collection. However, there were thousands of other files, some of which included Hypercard stacks. These are a virtual collection of interactive cards which users can navigate through, but that I could not access due to how Macintosh programs used embedded metadata. I was only able to access these files by using the SheepShaver emulating program to emulate an OS 9 computer.
The other collection that I’m working on which also requires the use of Macintosh emulation is the Elizabeth Blackburn papers. The born digital media in the Blackburn collection included 412 pieces of media, which is one of the largest groups of born digital media outside the Seth MacFarlane Collection of the Carl Sagan and Ann Druyan Archive. The Blackburn papers cover the subject of the human chromosome structure, specifically the telomere, which she and her staff researched. Blackburn and her staff primarily used Macintosh computers and long-obsolete, specialized genetic programs to record and document their research. All of these file types require either emulation of an OS 9 Macintosh or use of specialized software to access. After working on the Fedoroff and Blackburn papers, I began to wonder how the Library was going to provide researcher access to collections needing specialized programs or emulation.
While processing the Nina Fedoroff and Elizabeth Blackburn papers I realized what an important role computer technology played not only in their day-to-day lives but also in their research to advance the world’s understanding of genetics. These collections require many different obsolete Apple programs to access, so I am curious on what is the best way to sustainably provide access to the born digital media in these collection and those which require similar efforts. I’m hoping our project’s research about file formats and possible tools for various levels of access will make some progress towards answering that question.
Eileen: Wow, your project is tackling lots of multi-layered questions of access and preservation. What kinds of information will you be sharing with readers of the Signal as your project progresses?
Chad: We really want to use the Signal as a way of communicating with the Library’s users and other archiving professionals. The blogs we plan to write will discuss our survey of file formats within processed collections in the Manuscript Division. The second blog post will build on this research and explore various access challenges involving the digital files in the Manuscript Division Reading Room because of file format issues. In our third and final planned blog post, we will explore possible emulation programs and other tools used to provide access to born digital collection materials.
Eileen: Is there anything that the Signal audience can help you with?
Kathleen: We’d love to hear your questions about any aspect of born digital preservation and access. But mostly we’d love to hear what interests you about accessing and using born digital materials or born digital description in finding aids. How do you imagine yourself using these materials for research, art, writing, etc.? What are your expectations about accessing and using born digital content?
Chad: We would also enjoy hearing about how you would like to access born digital collections. Are you simply interested in accessing the content in files through programs that display the information, or are you interested in using emulation to access the files in the original environment and programs used to create them? In the finding aids that describe born digital files, what other metadata is important for you to see displayed? Would you like to see checksums? If you are working in an archive that processes and describes born digital materials, how is your institution thinking about providing researcher access to these materials?
Eileen: Lastly, would you like to share any entertaining anecdotes or details from the born digital materials in these collections that make them particularly interesting?
Chad: Absolutely! The images below show the importance and benefits of using emulation to access born digital files. The first image (Fedoroff image 1) shows a side-by-side comparison of a MacDraw image from the Nina V. Fedoroff papers with and without emulation. You can clearly see the loss of data when files are extracted from the forensic disk image as opposed to the full rendering of the information using emulation.
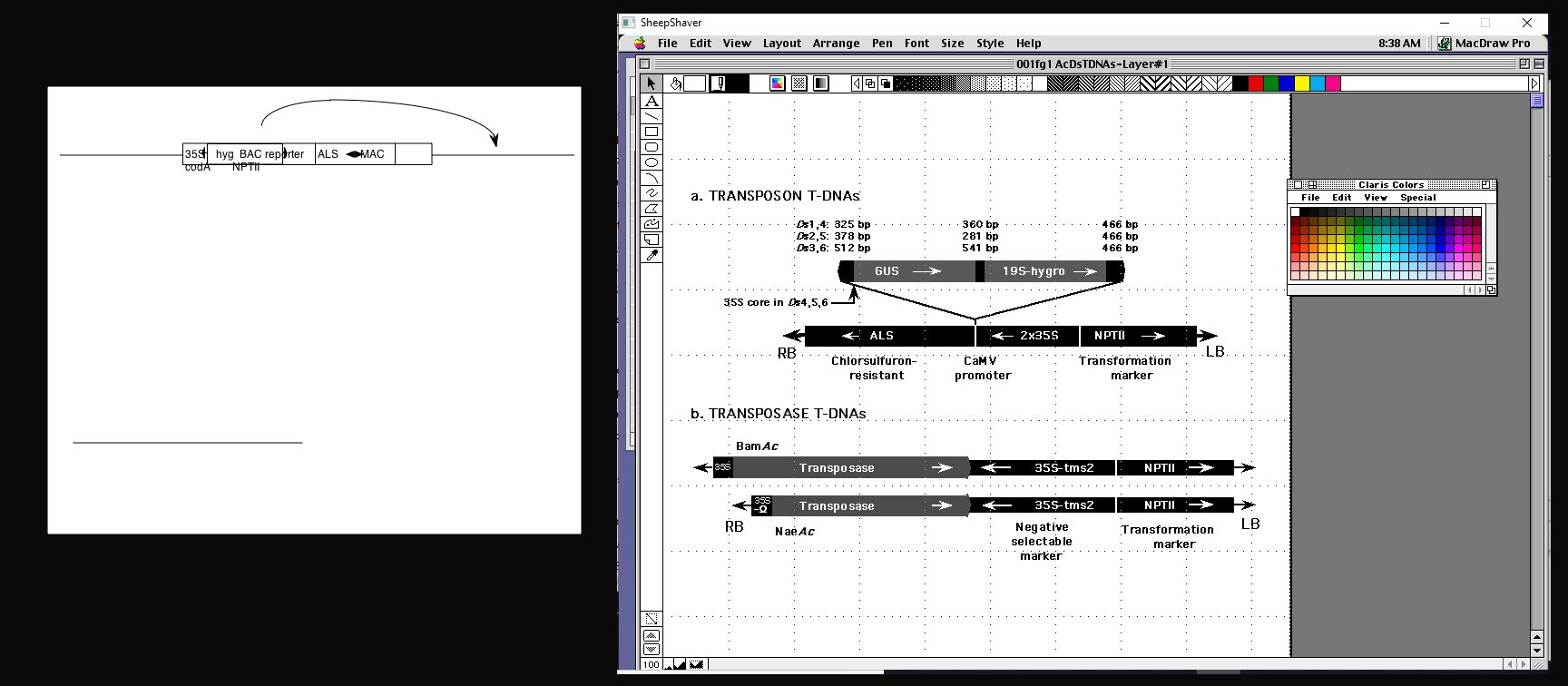
Fedoroff Image 1
The second image (Federoff image 2) is a screen capture of a Hypermaize card, which was created using the Hypercard program to record corn and other plants’ culture information. Without the use of an OS 9 Macintosh emulation with Hypercard installed, these types of files are not accessible.

Fedoroff Image 2
Kathleen: In addition to the science collections mentioned above, the division also holds the Rhoda Métraux papers and Edward N. Lorenz papers. There are journalism collections such as the Walter Sullivan papers which contain memoirs recounting his experience on expeditions to Antarctica. Those memoirs are probably the oldest files in our collection, most likely created in the early 1980s on a WaveMate Bullet computer. For lovers of baseball and musicals, the papers of pitcher Jim Bouton contain the lyrics to a never-produced musical adaptation of his book, Ball Four.
Eileen: Thank you! Is there anything else you’d like to share with readers before your next post?
Kathleen: We have over 150 collections with born digital materials, 85 of which are processed, described, and ready for researchers. With many of these materials, we can provide access to a bit level copy, but cannot provide full rendering or interaction with the materials in the Reading Room. During this Staff Innovator detail, we want to use whatever methods are currently available at the Library to provide and improve access to born digital collection materials “Now!” These are fantastic materials. We want people to use them!
If you have thoughts or questions in response to what you just read, you can get in touch with us at [email protected].