
The following is a guest post by Chris Adams from the Repository Development Center at the Library of Congress, the technical lead for the World Digital Library.
Preservation is usually about maintaining as much information as possible for the future but access requires us to balance factors like image quality against file size and design requirements. These decisions often require revisiting as technology improves and what previously seemed like a reasonable compromise now feels constricting.
I recently ran into an example of this while working on the next version of the World Digital Library website, which still has substantially the same look and feel as it did when the site launched in April of 2009. The web has changed considerably since then with a huge increase in users on mobile phones or tablets and so the new site uses responsive design techniques to adjust the display for a wide range of screen sizes. Because high-resolution displays are becoming common, this has also involved serving images at larger sizes than in the past — perfectly in keeping with our goal of keeping the focus on the wonderful content provided by WDL partners.
When viewing the actual scanned items, this is a simple technical change to serve larger versions of each but one area posed a significant challenge: the thumbnail or reference image used on the main item page. These images are cropped from a hand-selected master image to provide consistently sized, interesting images which represent the nature of the item – a goal which could not easily be met by an automatic process. Unfortunately the content guidelines used in the past specified a thumbnail size of only 308 by 255 pixels, which increasingly feels cramped as popular web sites feature much larger images and modern operating systems display icons as large as 256×256 or even 512×512 pixels. A “Retina” icon is significantly larger than the thumbnail below:
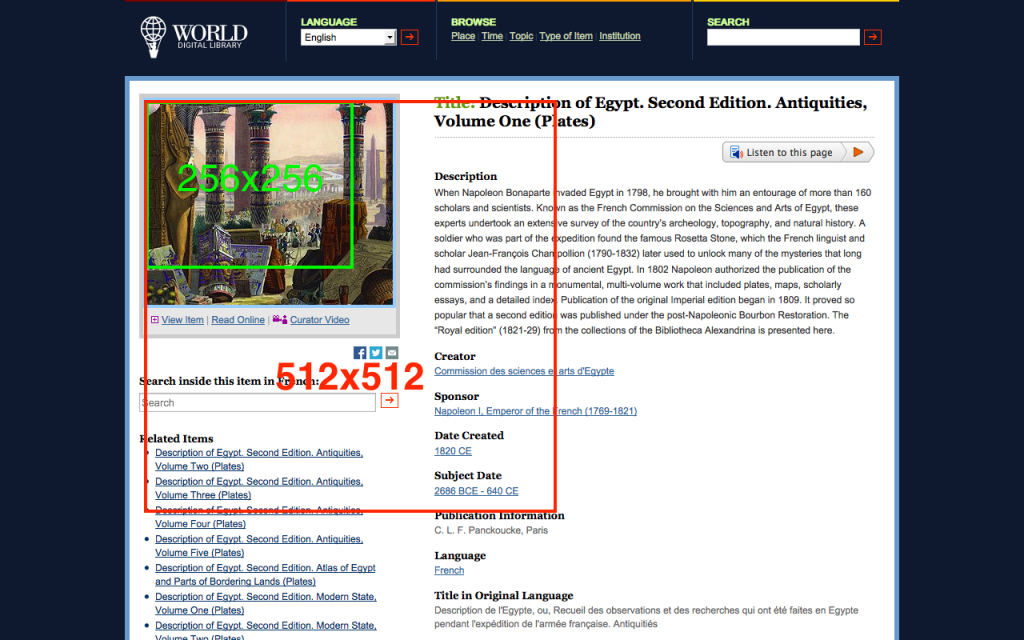 Going back to the source
Going back to the source
All new items being processed for WDL now include a reference image at the maximum possible resolution, which the web servers can resize as necessary. This left around 10,000 images which had been processed before the policy changed and nobody wanted to take time away from expanding the collection to reprocess old items. The new site design allows flexible image sizes but we wanted to find an automated solution to avoid a second-class presentation for the older items.
Our original master images are much higher resolution and we had a record of the source image for each thumbnail but not the crop or rotation settings which had been used to create the original thumbnail. Researching the options for reconstructing those settings lead me to OpenCV, a popular open-source computer vision toolkit.
At first glance, the OpenCV template matching tutorial appears to be perfect for the job: give it a source image and a template image and it will attempt to locate the latter in the former. Unfortunately, the way it works is by sliding the template image around the source image one pixel at a time until it finds a close match, a common approach but one which fails when the images differ in size or have been rotated or enhanced.
Fortunately, there are far more advanced techniques available for what is known as scale and rotation invariant feature detection and OpenCV has an extensive feature detection suite. Encouragingly, the first example in the documentation shows a much harder variant of our problem: locating a significantly distorted image within a photograph – fortunately we don’t have to worry about matching the 3D distortion of a printed image!
Finding the image
The locate-thumbnail program works in three steps:
- Locate distinctive features in each image, where features are simply mathematically interesting points which will hopefully be relatively consistent across different versions of the image – resizing, rotation, lighting changes, etc.
- Compare the features found in each image and attempt to identify the points in common
- If a significant number of matches were found, replicate any rotation which was applied to the original image
- Generate a new thumbnail at full resolution and save the matched coordinates and rotation as a separate data file in case future reprocessing is required
You can see this process in the sample visualizations below which have lines connecting each matched point in the thumbnail and full-sized master image:

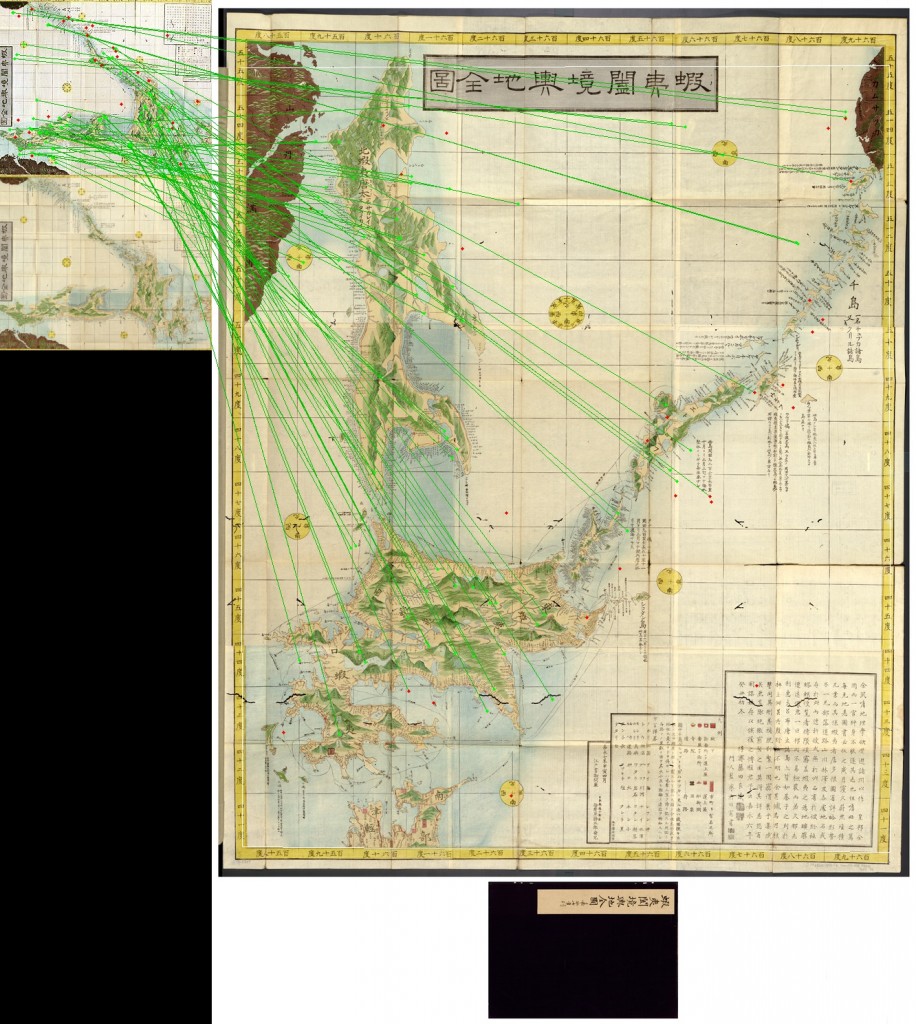
Maps of Ezo, Sakhalin, and Kuril Islands – note the rotation.
The technique even works surprisingly well with relatively low-contrast images such as this 1862 photograph from the Thereza Christina Maria Collection courtesy of the National Library of Brazil where the original thumbnail crop included a great deal of relatively uniform sky or water with few unique points:

Scaling up
After successful test runs on a small number of images, locate-thumbnail was ready to try against the entire collection. We added a thumbnail reconstruction job to our existing task queue system and over the next week each item was processed using idle time on our cloud servers. Based on the results, some items were reprocessed with different parameters to better handle some of the more unusual images in our collection, such as this example where the algorithm matched only a few points in the drawing, producing an interesting but rather different result:

Reviewing the results
Automated comparison
For the first pass of review, we wanted a fast way to compare images which should be very close to identical. For this work, we turned to libphash which attempts to calculate the perceptual difference between two images so we could find gross failures rather than cases where the original thumbnail had been slightly adjusted or was shifted by an insignificant amount. This approach is commonly used to detect copyright violations but it also works well as a way to quickly and automatically compare images or even cluster a large number of images based similarity.
A simple Python program was created and run across all of the reconstructed images, reporting the similarity of each pair for human review. The gross failures were used to correct bugs in the reconstruction routine and a few interesting cases where the thumbnail had been significantly altered, such as this cover page where a stamp added by a previous owner had been digitally removed:


http://www.wdl.org/en/item/7778/ now shows that this was corrected to follow the policy of fidelity to the physical item.
Human review
The entire process until this point has been automated but human review was essential before we could use the results. A simple webpage was created which offered fast keyboard navigation and the ability to view sets of images at either the original or larger sizes:
 This was used to review items which had been flagged by phash as less than matching below a particular threshold and to randomly sample items to confirm that the phash algorithm wasn’t masking differences which a human would notice.
This was used to review items which had been flagged by phash as less than matching below a particular threshold and to randomly sample items to confirm that the phash algorithm wasn’t masking differences which a human would notice.
In some cases where the source image had interacted poorly with the older down-sampling, the results are dramatic – the reviewers reported numerous eye-catching improvements such as this example of an illustration in an Argentinian newspaper:

Illustration from “El Mosquito, March 2, 1879” (original).

Illustration from “El Mosquito, March 2, 1879” (reconstructed).
Conclusion
This project completed towards the end of this spring and I hope you will enjoy the results when the new version of WDL.org launches soon. On a wider scale, I also look forward to finding other ways to use computer-vision technology to process large image collections – many groups are used to sophisticated bulk text processing but many of the same approaches are now feasible for image-based collections and there are a number of interesting possibilities such as suggesting items which are visually similar to the one currently being viewed or using clustering or face detection to review incoming archival batches.
Most of the tools referenced above have been released as open-source and are freely available:
- The Image Mining project includes the latest version of the locate-thumbnail program: https://github.com/acdha/image-mining/
- The Python wrapper for pHash and the command-line interface used to compare the results: https://pypi.python.org/pypi/phash