Amazon Web Services ブログ
コストアロケーションタグがAmazon DynamoDBに対応しました
Amazon DynamoDBのテーブルにタグを設定可能になりました。タグは多くのAWSサービスでサポートしている、シンプルでユーザがカスタマイズ可能なキー・バリューのペアです。DynamoDBのタグ対応は DynamoDBの利用料金の可視化に有効です。テーブル毎にタグを設定でき、タグ毎に料金を参照出来ます。
様々な環境(development/staging/production)で複数のDynamoDBテーブルを持っているシナリオを例に上げてご説明します。DynamoDBテーブルにタグを設定出来ます。例として、keyにEnvironment、valueにDevelopment, Staging, Productionとそれぞれ設定します。
DynamoDBコンソールでどのように設定するか見ていきましょう。設定を行う前にListTagsOfResourceとTagResourceのAPI操作を行う適切な権限を持っているか確認をして下さい。
- AWS Management Consoleにサインインをし、https://console.aws.amazon.com/dynamodb/からDynamoDBコンソールを開きます
- Tablesを選択し、設定を行ないたいテーブルを選択します
- Settingsタブで、Tagsをナビゲーションメニューから選択します
- Add Tagsセクションで、KeyにEnvironment、ValueにDevelopmentを入力し、Apply Changesをクリックします

標準の動作では、新しく追加されたキーはbillingでは無効化されています。以下の手順でBilling Consoleよりアクティベートを行えます:
- AWS Management Consoleにサインインをし、https://console.aws.amazon.com/billing/からBilling consoleを開きます
- ナビゲーションメニューからCost Allocation Tagsを選択します
- User-Defined Cost Allocation Tagsセクションから、タグキー内の Environmentタグ横のチェックボックスを選択し、Activateをクリックします

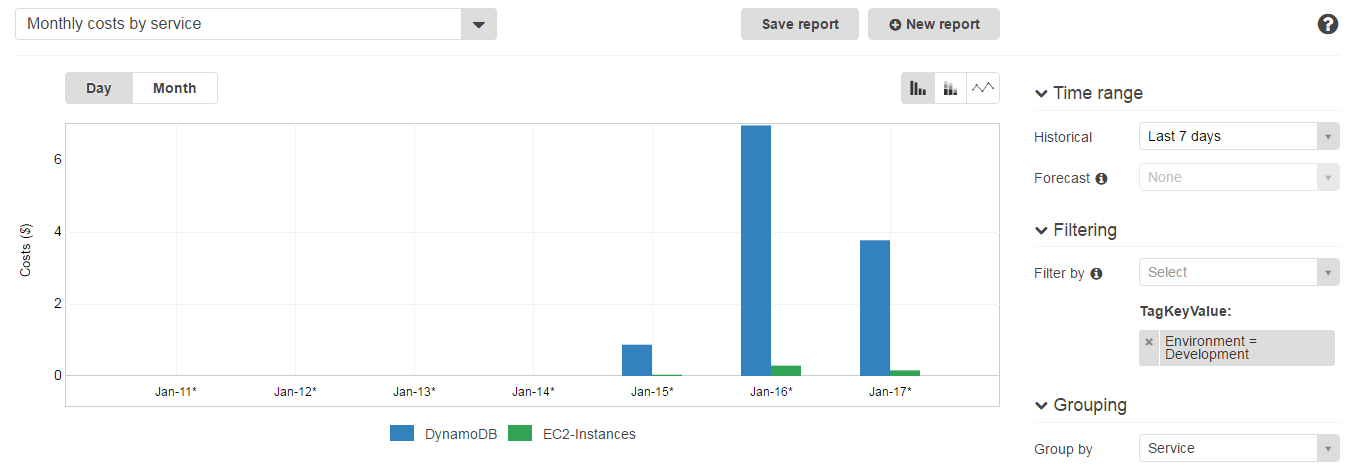
アクティベート済みのコストアロケーションタグがある場合、AWS Cost Explorerからタグ付けされたAWSリソースのコストを簡単にブレークダウンして閲覧出来ます:
- AWS Management Consoleにサインインをし、https://console.aws.amazon.com/billing/からBilling consoleを開きます
- ナビゲーションメニューからCost Explorerを選択し、Launch Cost Explorerを選択します
- 左上のメニューからMonthly costs by serviceを選択し、右のメニュー内の Time rangeから閲覧したいタイムレンジを指定します
- Filteringセクション内のFilter byからTagを選択します
- タグキーのオートコンプリートフィールドから Environmentを選択、Developmentをタグバリューのオートコンプリートセクションから選択し、Applyをクリックします

指定したタグ(Environment=Development)でコストがフィルタリングされます。コストはタグをAWSリソースに指定した時点から表示されます
DynamoDB Management Console, AWS CLIやAWS SDKからDynamoDBテーブルに50個までタグを設定出来ます。DynamoDBテーブルに設定されている、Global secondary indexes (GSIs) と local secondary indexes (LSIs)にもDynamoDBテーブルで設定したタグが自動的に設定されます。DynamoDBのタグサポートは全てのAWSリージョンで利用可能です。
更に詳細な、AWSリソースでのタグの活用はこちらをご覧下さい。
— Nitin Sagar(product manager for DynamoDB) (翻訳は星野が担当しました。原文はこちら)
RDS MySQL DBインスタンスからAmazon Aurora Read Replicaを作成可能になりました
24時間365日稼働しているアプリケーションが利用しているデータベースエンジンを他のデータベースエンジンに移行するにはいくつかの方法を使う必要があると思います。データベースをオフラインにせずに移行する良い方法として、レプリケーションを利用する方法があります。
本日、Amazon RDS DB for MySQLインスタンスを Amazon AuroraにAurora Read Replicaを作成して移行する機能をリリースしました。マイグレーションは、まず既存のDBスナップショットを作成し、そこからAurora Read Replicaを作成します。レプリカのセットアップが完了後、ソースデータベースとのレプリケーションの設定を行い最新のデータをキャッチアップします。レプリケーションラグが0になればレプリケーションが完了した状態です。この状態になった後に、 Aurora Read Replicaを独立したAurora DB clusterとして利用可能で、アプリケーションの設定を変更しAurora DB clusterに接続します。
マイグレーションはテラバイトあたり数時間かかります。また、6TBまでのMySQL DBインスタンスに対応しています。InnoDBテーブルのレプリケーションはMyISAMテーブルのレプリケーションよりもやや高速で、圧縮されていないテーブルの利点も受けられます。
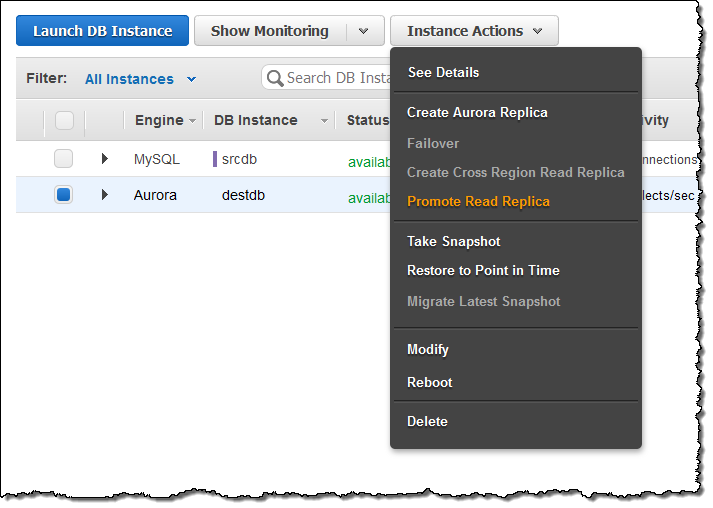
RDS DBインスタンスをマイグレーションするためには、 AWS Management ConsoleからRDSのコンソールを選択し、Instance Actionsを選択します。その後、Create Aurora Read Replicaを選択するだけです:

そして、データベースインスタンスの情報やオプションを入力し、Create Read Replicaをクリックします:

コンソール上でマイグレーションの進捗状況を閲覧出来ます:

マイグレーション完了後、Aurora Read Replicaでレプリカラグが0になるのを待ちます(SHOW SLAVE STATUSコマンドをレプリカで実行し、“Seconds behind master”を監視します)。その後、ソースのMySQL DBインスタンスへの新しいトランザクションを停止し、Aurora Read ReplicaをDBクラスタに昇格させます:
新しいクラスタが利用可能になるまで待機します(通常は1分程度):

最後に、アプリケーションの設定をクラスタのread/writeエンドポイントを利用するように設定し完了です!
すぐに使用できるソリューション: AWS Marketplace のオープンソースソフトウェア
AWS Marketplace では、すばらしいことがたくさん起きています。こちらで、マーケットプレイスのオープンソースソフトウェアについての詳細を、Matthew Freeman および Luis Daniel Soto が説明します。
– Ana
業界の調査によると、企業が使用するオープンソースソフトウェア (OSS) は増加しています。ますます多くの企業の開発者は、現在進行中の開発作業の一環として、利用可能な OSS ライブラリを使用するように求めています。これらの開発者は、自分のプロジェクト (夜間および週末など) で OSS を使用していることがあり、その場合自然に別の場所でもそのツールおよびテクニックを使用したいと考えます。そのため、すべての部門の開発組織は、販売するソフトウェアだけでなく、自社の IT インフラストラクチャ内のアプリケーションにオープンソースソフトウェアを使用するケースを検討しています。この概要では、AWS を通したオープンソースソフトウェアの入手が開発および財務の観点から理にかなっている理由について説明します。
オープンソース開発プロセス
オープンソースソフトウェアは、一般的に参加者の独立したコミュニティで開発されるため、ソフトウェアのバージョンの取得および管理は、通常オンラインコードリポジトリを通して行われます。異なるソースからのコードを使用すると、コードライブラリおよび開発ツールを取得して共に機能させることが困難となる場合があります。しかし、AWS Marketplace は、このプロセスをスキップして、必要な OSS で EC2 インスタンスを直接起動できます。AWS Marketplace には、OSS ソリューションの基盤として使用できる Linux のディストリビューションもあります。
構成済みのスタックが与えるメリット
市販のソフトウェアでこの 1-Click 起動機能は当然のことと考えるかもしれませんが、OSS にとって構成済みの AMI を実装していることには大きなメリットがあります。AWS Marketplace は、最も一般的なオープンソースソフトウェアの組み合わせ、または「スタック」を作成するソフトウェア会社に、これらのスタックを AWS クラウドに起動できる場所を提供します。TurnKey および Bitnami のような企業は、OSS のエキスパートを使って、ソフトウェアが共にうまく機能するようにこれらのコードスタックを設定および最適化します。これらの企業は、OSS のリリースを最新の状態に保ち、新しいバージョンが利用可能になるとすぐにスタックを更新します。これらの企業の中には、クラウドベースのサーバーの起動および管理をさらに容易にするために、クラウドホスティングインフラストラクチャを有料サービスとして提供しているものもあります。たとえば、オープンソースソフトウェアの最も一般的な組み合わせの 1 つは、LAMP スタックで、Linux ディストリビューション、Apache ウェブサーバー、MySQL データベース、および PHP プログラミングライブラリで構成されています。希望する Linux ディストリビューションに基づいて一般的な LAMP スタックを選択し、お好みの開発ツールとライブラリをインストールすることができます。

その後、必要に応じて、または期待どおりにアプリケーションを実行するために基礎となるソフトウェアに調整を加えます。たとえば、アプリケーションのメモリ割り当てを変更したり、PHP 設定で最大ファイルアップロードのサイズを変更できます。LAMP 要素に加え、WordPress、Moodle、または Joomla!® などの単一のアプリケーションを含む OSS のアプリケーションスタックを選択できます。これらのスタックは、アプリケーション要件に基づく十分なメモリおよびディスクの割り当てで円滑に動作するように、個々のアプリケーションの最適な設定を使用してベンダーによって設定されます。この点で、スタックベンダーは、基本的なソフトウェアプロビジョニングに付加価値を提供できるので優れていると言えます。 共通のコンポーネントを使用する単一サーバー上の複数のアプリケーションを結合する必要がある場合、代わりに汎用の LAMP スタックを選択することもできます。たとえば、WordPress には、直接 Moodle と相互運用するためのプラグインがあります。両方のアプリケーションは、Apache ウェブサーバー、PHP、および MySQL を使用します。LAMP スタックを基にして、WordPress と Moodle が共にうまく機能するために必要に応じてコンポーネントを個別に設定することで、時間を節約できます。
共通のコンポーネントを使用する単一サーバー上の複数のアプリケーションを結合する必要がある場合、代わりに汎用の LAMP スタックを選択することもできます。たとえば、WordPress には、直接 Moodle と相互運用するためのプラグインがあります。両方のアプリケーションは、Apache ウェブサーバー、PHP、および MySQL を使用します。LAMP スタックを基にして、WordPress と Moodle が共にうまく機能するために必要に応じてコンポーネントを個別に設定することで、時間を節約できます。 これらは、AWS Marketplace から構成済みのソリューションをどのように使用して自身のニーズに合わせるかという、2 つの実際の例です。
これらは、AWS Marketplace から構成済みのソリューションをどのように使用して自身のニーズに合わせるかという、2 つの実際の例です。
AWS Marketplace の OSS
AWS Marketplace は、OSS のツール、アプリケーション、およびサーバーを入手してデプロイするための最大のサイトの 1 つです。OSS が利用可能な他のカテゴリは以下の通りです。
- アプリケーションの開発およびテストツール Zend、ColdFusion、Ruby on Rails、Node.js などのアプリケーションフレームワークで設定された EC2 サーバー用の AWS Marketplace ソリューションおよび CloudFormation テンプレートで見つけることができます。また、テスト自動化のための Jenkins、問題追跡のための Bugzilla、ソースコード管理のための Subversion、設定管理ツールなどの主要な製品を使用してアジャイルソフトウェア開発をサポートする、開発およびテストツールのための人気のある OSS を選択することができます。詳細 »
- インフラストラクチャソフトウェア ビジネスの成功には、ネットワークの正常なメンテナンスおよび保護が重要です。OpenLDAP および OpenVPN などの OSS ライブラリは、クラウドインフラストラクチャを起動して、オンプレミスネットワークに付随させるか、または完全に置き換えることを可能にします。ネットワーキングおよびセキュリティの処理に特化したサービスからセキュリティが強化された個々のサーバーまで、AWS Marketplace には、様々なワークロードのセキュリティ要件を満たすのに役立つ多数のセキュリティソリューションがあります。詳細 »
- データベースおよびビジネスインテリジェンス OSS データベース、データ管理、およびオープンデータカタログソリューションを含む。ビジネスインテリジェンスおよび高度な分析ソフトウェアは、トランザクションシステム、センサー、携帯電話、およびインターネットに接続されたあらゆるデバイスからのデータを理解するのに役立ちます。詳細 »
- ビジネスソフトウェア 可用性、俊敏性、柔軟性は、クラウド上でビジネスアプリケーションを実行するのに重要です。あらゆる規模の企業は、インフラストラクチャ管理の簡素化、より迅速なデプロイ、コストの削減、収益の増加を望んでいます。Linux で動作するビジネスソフトウエアは、これらの主要メトリックスを提供します。詳細 »
- オペレーティングシステム AWS Marketplace には、FreeBSD、最小限およびセキュリティが強化された Linux インストールからセキュリティおよび科学的作業のための特別なディストリビューションまで、様々なオペレーティングシステムがあります。詳細 »
AWS Marketplace で OSS の使用を開始する方法
まず、必要なソフトウェアの組み合わせを特定し、AWS Marketplace のホーム画面の上部にある検索ボックスにキーワードを入力して、適切なサービスを見つけます。

または、カテゴリ別にブラウズする場合は、[Shop All Categories] をクリックしてリストから選択します。

最初に検索または選択を行うと、最適な候補が残るまで結果をフィルタリングする 10 を超える方法があります。たとえば、希望の Linux ディストリビューションを選択するために、すべての Linux フィルタを展開して、そのディストリビューションで実行されるソリューションを見つけることができます。無料試用版、ソフトウェアの料金プラン、EC2 のインスタンスタイプ、AWS リージョン、評価の平均などをフィルタリングすることもできます。

リストのタイトルをクリックすると、料金表、リージョン、製品サポート、販売者の Web サイトへのリンクを含むそのサービスの詳細が表示されます。選択し、インスタンスを起動する準備をしたら、[Continue] をクリックして、アカウントにログインします。

ログインすると、AWS Marketplace は、既存のセキュリティグループ、キーペア、および VPC 設定の存在を検出できます。[Launch on EC2] ページで調整し、[Accept Software Terms & Launch with 1-Click] をクリックすると、インスタンスがすぐに起動します。

必要に応じて、選択した AWS コンソールを使用して Manual Launch を実行するか、API または コマンドラインインターフェイス (CLI) 使用してインスタンスを開始できます。どちらの場合でも、数分で EC2 インスタンスが起動して実行されます。
従量料金制の柔軟性
Amazon EC2 の使用料に 1 時間 (または月または年) あたりで算出した額を加算した料金、および該当する場合、商用オープンソースソフトウェア使用料を AWS アカウントを通して直接支払います。そのため、AWS Marketplace の使用は、OSS ソフトウェアを起動して実行する最も速く簡単な方法の 1 つと言えます。
AWS Marketplace のオープンソースソフトウェアの詳細については、「http://aws.amazon.com/mp/oss」を参照してください。
- Matthew Freeman、開発部門主任、AWS Marketplace Luis Daniel Soto、シニア GTM 部門主任、AWS Marketplace
AWS Lambda – 2016 年を振り返って
2016 年は AWS Lambda、Amazon API Gateway、そして、サーバーレスコンピューティングテクノロジーにとって、控えめに言ってもすばらしい年となりました。もしかすると、AWS Lambda および Amazon API Gateway でのサーバーレスコンピューティングについて耳にしたことがない方がいらっしゃるかもしれませんので、これらのすばらしいサービスについてご紹介したいと思います。AWS Lambda を使用すると、サーバーをプロビジョニングまたは管理しなくてもコードを実行できます。このイベント駆動型のサーバーレスコンピューティングサービスにより、開発者は、ほぼすべての種類のアプリケーションまたはバックエンドで機能を簡単にクラウドへ移行できます。Amazon API Gateway は非常にスケーラブルで、信頼性が高く、堅牢な API を大規模にすばやく構築するのに役立ち、作成した API の維持およびモニタリングの機能も提供します。2016 年のサーバーレスの勢いの締めくくりとして、AWS チームは re:Invent でサーバーレスソリューションの構築をさらに簡単にする強力なサービス機能を発表しました。その機能には次のものがあります。
- AWS Greengrass: Lambda および AWS IoT を使用して、接続された IoT デバイスのローカルでのコンピューティング、メッセージング、データのキャッシングを実行します。https://aws.amazon.com/blogs/aws/aws-greengrass-ubiquitous-real-world-computing/
- Lambda@Edge Preview: グローバル AWS エッジロケーションでコードを実行でき、Amazon CloudFront のリクエストに応じてトリガーされることで、エンドユーザーのネットワークレイテンシーを削減できる Lambda の新しい機能です。https://aws.amazon.com/blogs/aws/coming-soon-lambda-at-the-edge/
- AWS Batch Preview: 今後予定されているバッチジョブとしての Lambda 統合を含む AWS コンピューティングサービスにおけるワークロードの計画、スケジューリング、実行のコンピューティング用バッチです。https://aws.amazon.com/blogs/aws/aws-batch-run-batch-computing-jobs-on-aws/
- AWS X-Ray: マイクロサービスアーキテクチャを使用してビルドされたもの、Java、Node.js、.NET で記述されたもの、EC2、ECS、AWS Elastic Beanstalk にデプロイされたものなど、分散アプリケーションの分析とデバッグを実行します。今後予定されている AWS Lambda をサポートします。https://aws.amazon.com/blogs/aws/aws-x-ray-see-inside-of-your-distributed-application/
- Continuous Deployment for Serverless: サーバーレスアプリケーションのための継続的デプロイパイプラインを作成する AWS のサービスです。https://aws.amazon.com/blogs/compute/continuous-deployment-for-serverless-applications/
- Step Functions: 視覚的なワークフローを使用して、分散アプリケーションとマイクロサービスのコンポーネントを調整する信頼性の高い方法です。https://aws.amazon.com/blogs/aws/new-aws-step-functions-build-distributed-applications-using-visual-workflows/
- Dead Letter Queues: キューまたは他の通知システムへの Lambda 関数の失敗の通知をサポートします。
- C# Support: C# コード は AWS Lambda でサポートされる言語です。
- API Gateway Monetization: API Gateway と AWS Marketplace の統合
- API Gateway Developer Portal: 独自の開発者ポータルの作成を始めることができるオープンソースのサーバーレスウェブアプリケーションです。
Jeff が Step Functions などの分散アプリケーションやマイクロサービスを構築するための前述の新しいサービス機能についてほとんど紹介したので、一般的なサーバーレスユースケースの例であるリアルタイムのストリーム処理を使って、まだ説明されていない最後の 4 つの新しい機能について紹介しましょう。ストリーム処理のユースケースについてのこの説明では、データのストリームを処理する Lambda 関数から送られることのあるエラー通知のために、デッドレターキューを実装します。ストリームの処理には Node.js で記述された既存の Lambda 関数を用い、C# 言語を使って書き換えます。その後、API Gateway と AWS Marketplace の統合を利用して Lambda が支援する API の収益化の例を構築します。これは楽しみです。それでは、始めましょう。サンフランシスコとオースティンでの AWS 開発者デーの期間中、私はリアルタイムのストリーム処理で AWS Lambda を活用する例を、Twitter ストリーミング API を使ったストリーミングソリューションを見せるデモを作成して紹介しました。この例の方法に沿って、デッドレターキュー (DLQ)、C# サポート、API Gateway 収益化の特徴、API Gateway Developer Portal のオープンソースのテンプレートを紹介していきます。デモでは、「awscloud」または「serverless」 (またはその両方) のキーワードを含むコンソールまたはウェブアプリケーションのストリームのツイートを Twitter ストリーミング API から集めました。それらのツイートはリアルタイムで Amazon Kinesis Streams に送信され、Lambda が新しいレコードを検出し、NoSQL データベースである Amazon DynamoDB にツイートを書き込むことでストリーミングのバッチを処理します。これで、リアルタイムのストリーミング処理のデモのワークフローを理解できたので、Kinesis からのバッチレコードを処理する Lambda 関数についてより詳しく見てみましょう。まず、以下のとおり、Lambda 関数 DevDayStreamProcessor には、バッチサイズが 100 で DevDay2016Stream という名前の Kinesis ストリームであるイベントソース、またはトリガーがあります。Lambda 関数は新しいレコードのために定期的にストリームをポーリングし、レコードのバッチ、このケースではストリームで検出されたツイートを自動的に読み取って処理します。

次に、Node.js 4.3. で記述された Lambda 関数のコードを調べます。以下に示す Lambda 関数のセクションは、Kinesis ストリームからのツイートレコードのバッチをループし、各レコードを解析し、一連の JSON データに必要なツイート情報を書き込みます。一連の JSON のツイート項目は Lambda ハンドラーの外部にある ddbItemsWrite 関数に渡されます。
'use strict';
console.log('Loading function');
var timestamp;
var twitterID;
var tweetData;
var ddbParams;
var itemNum = 0;
var dataItemsBatch = [];
var dbBatch = [];
var AWS = require('aws-sdk');
var ddbTable = 'TwitterStream';
var dynamoDBClient = new AWS.DynamoDB.DocumentClient();
exports.handler = (event, context, callback) => {
var counter = 0;
event.Records.forEach((record) => {
// Kinesis data is base64 encoded so decode here
console.log("Base 64 record: " + JSON.stringify(record, null, 2));
const payload = new Buffer(record.kinesis.data, 'base64').toString('ascii');
console.log('Decoded payload:', payload);
var data = payload.replace(/[\u0000-\u0019]+/g," ");
try
{ tweetData = JSON.parse(data); }
catch(err)
{ callback(err, err.stack); }
timestamp = "" + new Date().getTime();
twitterID = tweetData.id.toString();
itemNum = itemNum+1;
var ddbItem = {
PutRequest: {
Item: {
TwitterID: twitterID,
TwitterUser: tweetData.username.toString(),
TwitterUserPic: tweetData.pic,
TwitterTime: new Date(tweetData.time.replace(/( \+)/, ' UTC$1')).toLocaleString(),
Tweet: tweetData.text,
TweetTopic: tweetData.topic,
Tags: (tweetData.hashtags) ? tweetData.hashtags : " ",
Location: (tweetData.loc) ? tweetData.loc : " ",
Country: (tweetData.country) ? tweetData.country : " ",
TimeStamp: timestamp,
RecordNum: itemNum
}
}
};
dataItemsBatch.push(ddbItem);
counter++;
});
var twitterItems = {};
twitterItems[ddbTable] = dataItemsBatch;
ddbItemsWrite(twitterItems, 0, context, callback);
};
以下に示す ddbItemsWrite 関数は、Kinesis ストリームから処理された一連の JSON のツイートレコードを取り出し、バッチオペレーションを使用してレコードの複数の項目を同時に DynamoDB テーブルに書き込みます。この関数は、個々のテーブルのスロットリングによる書き込みリクエストの失敗を避けるため、エクスポネンシャルバックオフアルゴリズムを実装することにより、未処理の項目を再試行する DynamoDB のベストプラクティスを活用します。
function ddbItemsWrite(items, retries, ddbContext, ddbCallback)
{
dynamoDBClient.batchWrite({ RequestItems: items }, function(err, data)
{
if (err)
{
console.log('DDB call failed: ' + err, err.stack);
ddbCallback(err, err.stack);
}
else
{
if(Object.keys(data.UnprocessedItems).length)
{
console.log('Unprocessed items remain, retrying.');
var delay = Math.min(Math.pow(2, retries) * 100, ddbContext.getRemainingTimeInMillis() - 200);
setTimeout(function() {ddbItemsWrite(data.UnprocessedItems, retries + 1, ddbContext, ddbCallback)}, delay);
}
else
{
ddbCallback(null, "Success");
console.log("Completed Successfully");
}
}
}
);
}現在、この Lambda 関数は期待通りに動作しており、Twitter ストリーミング API から Kinesis に取得されたツイートを問題なく処理します。しかし、この関数には、DynamoDB テーブルへのバッチ書き込みリクエストを処理するときにエラーが発生するという欠陥があります。Lambda 関数で、現在のコードでは、DynamoDB batchWrite 関数が 単一呼び出しにつき最大 25 の書き込み (PUT) リクエストで最大 16 MB のデータで構成されている必要があることが考慮されていません。そのため、ddbItemsWrite 関数を送信する前に、コードを適切に変更して ddbItemsWrite 関数を 25 のバッチに対応させるか、または、ハンドラー組み込み関数で項目を 25 リクエストの一連のグループにします。25 以上のツイート項目のバッチが送信されると検証の例外が発生します。これは、小規模なテストシナリオでは検出されにくくても、本稼働ワークロードでは失敗となるバグのよい例です。 デッドレターキュー これで、ddbItemsWrite Lambda 関数に例外をスローさせるイベント、または、レコードを処理する際に失敗となるイベントを認識できたので、デッドレターキュー (DLQ) を活用するのに最適なシナリオとなります。AWS Lambda DLQ 機能は Amazon S3、Amazon SNS、AWS IoT のような非同期イベント、または直接の非同期呼び出しでのみ使用可能で、Amazon Kinesis または Amazon DynamoDB ストリームのようなストリーミングイベントのソース向けではないので、最初のステップはこの Lambda 関数を 2 つの関数に分けることです。最初の Lambda 関数は Kinesis ストリームの処理に対応し、2 つめの関数は最初の関数で処理されたデータを取り出し DynamoDB にツイート情報を書き込みます。その後、上記のとおり DynamoDB へのツイートのバッチを書き込む際に生じるエラーのために、2 つめの Lambda 関数で DLQ をセットアップします。ターゲットを DLQ にセットアップするときに 2 つのオプションがあります。Amazon SNS トピック、または Amazon SQS キューです。この説明の中では、Amazon SQS キューの使用を選択します。そのため、DLQ を使用する際の最初のステップは、SQS 標準キューの作成です。標準キュータイプは高トランザクションスループットのあるキューです。メッセージが最低 1 回配信され、メッセージの別のコピーも配信されます。メッセージが、送信された順序とは異なる順序で配信されることがあります。SQS キューとキュータイプの詳細については、「Amazon SQS ドキュメント」をご覧ください。私のキュー、StreamDemoDLQ が作成されたら、この選択したキューの詳細タブから ARN をつかみます。コンソールを使用してこの関数に DLQ リソースを指定しない場合は、この SQS キューをエラーとイベント失敗通知のための DLQ ターゲットとして識別するため、Lambda 関数のためにキューの ARN が必要です。また、この SQS キューにアクセスする目的で Lambda 実行ロールポリシーにアクセス許可を追加するために ARN を使用します。

Lambda 関数に戻り、[Configuration] タブを選択して [Advanced settings] セクションを開きます。[DLQ Resource] フィールドで SQS を選択し、[SQS Queue] フィールドのドロップダウンから 私の [StreamDemoDLQ] キューを選択します。

SQS DLQ へ正常にメッセージを送信するには、Lambda 関数の実行ロールは明示的に sqs:SendMessage のアクセスを許可する必要があります。そのため、私の Lambda ロール lambda_kinesis_role に以下の SQS アクセス権限のための IAM ポリシーがあることを確認しました。

これで、Amazon SQS を使用して Lambda 関数のためのデッドレターキューを正常に設定できました。Lambda のデッドレターキューの詳細については、「AWS Lambda 開発者ガイド」の「トラブルシューティングとモニタリング」セクションをお読みください。また、デッドレターキューに関する「AWS コンピューティングブログの投稿」をご確認ください。
C# Support
前述のとおり、AWS re:Invent で Lambda に追加された別のすばらしい特徴は、オープンソース .NET Core 1.0 プラットフォームによる C# 言語のサポートです。Lambda コンソールはまだコンパイル済み言語の編集を提供していないので、C# Lambda 関数を記述するには、AWS Toolkit、Yeoman、または .NET CLI で Visual Studio のツールを使用できます。C# で記述された Lambda 関数をデプロイするには、AWS ToolKit for Visual Studio の Lambda プラグインを使用するか、または .NET Core コマンドラインでデプロイパッケージを作成します。C# Lambda 関数ハンドラーをクラスのインスタンスまたは静的メソッドとして定義する必要があります。2 つの関数パラメーターがあります。1 つめは、イベントデータである入力型で、もう 1 つは、タイプ ILambdaContext の Lambda コンテキストオブジェクトです。AWS のサービスのイベントデータ入力オブジェクトタイプには以下のものがあります。
- Amazon.Lambda.APIGatewayEvents
- Amazon.Lambda.CognitoEvents
- Amazon.Lambda.ConfigEvents
- Amazon.Lambda.DynamoDBEvents
- Amazon.Lambda.KinesisEvents
- Amazon.Lambda.S3Events
- Amazon.Lambda.SNSEvents
Lambda の C# サポートの詳細について説明したので、DevDayStreamProcessor Lambda 関数を C# 言語で書き換えましょう。この例では、Lambda 関数を記述するのに Visual Studio IDE を使用します。また、関数をデプロイするのに、AWS Lambda Visual Studio プラグインを活用します。Lambda で AWS Toolkit for Visual Studio を使用するには、Visual Studio 2015 Update 3 バージョンと NET Core ツールが必要なことに留意してください。Visual Studio 2015 Update 3 と .NET Core のインストールの詳細については、こちらをお読みください。Visual Studio を使用して C# 関数を作成するには、新しいプロジェクトを開始し、[AWS Lambda Project (.NET Core)] を選択して ServerlessStreamProcessor という名前を付けます。

この関数を記述するのに AWS Toolkit for Visual Studio を活用することの大きな利点は、Lambda コンソールを使用するのと同様の方法で Visual Studio の中で Lambda 設計図を使用できることです。それで、DevDayStreamProcessor を C# でレプリケートするために、Simple Kinesis Function 設計図を選択します。

Lambda 関数を C# で記述する場合、クラスの宣言やターゲットのハンドラー関数を Lambda 関数としてマークする必要はありません。また、CloudWatch ログを記述する場合は、標準 C# の Console クラスの WriteLine 関数を使用するか、ILambdaContext インターフェイスの一部である ILambdaContext の LogLine 関数を使用することができます。所定の Kinesis ストリームにアクセスするためのテンプレートでは、C# Lambda 関数の ServerlessStreamProcessor を記述するために Node.js コードの DevDayStreamProcessor と同じ変数名を使用します。以下の C# Lambda ハンドラー関数をご覧ください。
using System.Collections.Generic;
using Amazon.Lambda.Core;
using Amazon.Lambda.KinesisEvents;
using Amazon.DynamoDBv2;
using Amazon.DynamoDBv2.DataModel;
using Newtonsoft.Json.Linq;
// Assembly attribute to enable the Lambda function's JSON input to be converted into a .NET class.
[assembly: LambdaSerializerAttribute(typeof(Amazon.Lambda.Serialization.Json.JsonSerializer))]
namespace ServerlessStreamProcessor
{
public class LambdaTwitterStream
{
string twitterID, timeStamp;
int itemNum = 0;
private static AmazonDynamoDBClient dynamoDBClient = new AmazonDynamoDBClient();
List<TwitterItem> dataItemsBatch = new List<TwitterItem>();
public void FunctionHandler(KinesisEvent kinesisEvent, ILambdaContext context)
{
DynamoDBContext dbContext = new DynamoDBContext(dynamoDBClient);
context.Logger.LogLine($"Beginning to process {kinesisEvent.Records.Count} records...");
foreach (var record in kinesisEvent.Records)
{
context.Logger.LogLine($"Event ID: {record.EventId}");
context.Logger.LogLine($"Event Name: {record.EventName}");
// Kinesis data is base64 encoded so decode here
string tweetData = GetRecordContents(record.Kinesis);
context.Logger.LogLine($"Decoded Payload: {tweetData}");
tweetData = @"" + tweetData;
JObject twitterObj = JObject.Parse(tweetData);
twitterID = twitterObj["id"].ToString();
timeStamp = DateTime.Now.Millisecond.ToString();
itemNum++;
context.Logger.LogLine(timeStamp);
context.Logger.LogLine($"Twitter ID is: {twitterID}");
context.Logger.LogLine(itemNum.ToString());
TwitterItem ddbItem = new TwitterItem()
{
TwitterID = twitterID,
TwitterUser = twitterObj["username"].ToString(),
TwitterUserPic = twitterObj["pic"].ToString(),
TwitterTime = DateTime.Parse(twitterObj["time"].ToString()).ToUniversalTime().ToString(),
Tweet = twitterObj["text"].ToString(),
TweetTopic = twitterObj["topic"].ToString(),
Tags = twitterObj["hashtags"] != null ? twitterObj["hashtags"].ToString() : String.Empty,
Location = twitterObj["loc"] != null ? twitterObj["loc"].ToString() : String.Empty,
Country = twitterObj["country"] != null ? twitterObj["country"].ToString() : String.Empty,
TimeStamp = timeStamp,
RecordNum = itemNum
};
dataItemsBatch.Add(ddbItem);
}
context.Logger.LogLine(JObject.FromObject(dataItemsBatch).ToString());
ddbItemsWrite(dataItemsBatch, 0, dbContext, context);
context.Logger.LogLine("Success - Completed Successfully");
context.Logger.LogLine("Stream processing complete.");
}C# で記述された Kinesis ストリームプロセッサと当初の Node.js コード間の注意すべき差異はわずかです。C# Lambda 関数でデフォルトでサポートされている入力パラメータータイプは System.IO.Stream タイプであるため、Kinesis base64 文字列は、設計図で提供されている GetRecordContents 関数で StreamReader (エンコーディングは ASCII) を使用してデコードされます。
private string GetRecordContents(KinesisEvent.Record streamRecord)
{
using (var reader = new StreamReader(streamRecord.Data, Encoding.ASCII))
{
return reader.ReadToEnd();
}
}ツイートのデータを DynamoDB テーブルに書き込むために、Visual Studio 内で NuGet パッケージマネージャーを経由して DynamoDB; AWSSDK.DynamoDBv2 の AWS .NET SDK NuGet パッケージを Lambda 関数プロジェクトに追加しました。また、DynamoDB テーブルに保存されるデータにマッピングするために .NET データオブジェクトとして TwitterItem も作成しました。DynamoDB 用の AWS .NET SDK 高レベルプログラミングインターフェイス、オブジェクト永続性モデルを使用して、ddbItemsWrite C# 関数の BatchWrite オブジェクトクラスを介して書き込む TwitterItem オブジェクトのコレクションを作成しました。
private async void ddbItemsWrite(List<TwitterItem> items, int retries, DynamoDBContext ddbContext, ILambdaContext context)
{
BatchWrite<TwitterItem> twitterStreamBatchWrite = ddbContext.CreateBatchWrite<TwitterItem>();
try
{
twitterStreamBatchWrite.AddPutItems(items);
await twitterStreamBatchWrite.ExecuteAsync();
}
catch (Exception ex)
{
context.Logger.LogLine($"DDB call failed: {ex.Source} ");
context.Logger.LogLine($"Exception: {ex.Message}");
context.Logger.LogLine($"Exception Stacktrace: {ex.StackTrace}");
}
}
AWS Toolkit for Visual Studio を使用して、C# Lambda 関数を作成する別のメリットは、1 回クリックするだけで Lambda 関数を直接 AWS にデプロイできることです。ソリューションエクスプローラーでプロジェクト名を選択し、右クリックすると、メニューオプションに Publish to AWS Lambda が出て、AWS へのデプロイ用の Lambda 関数について含めるべき情報のメニューが表示されます。
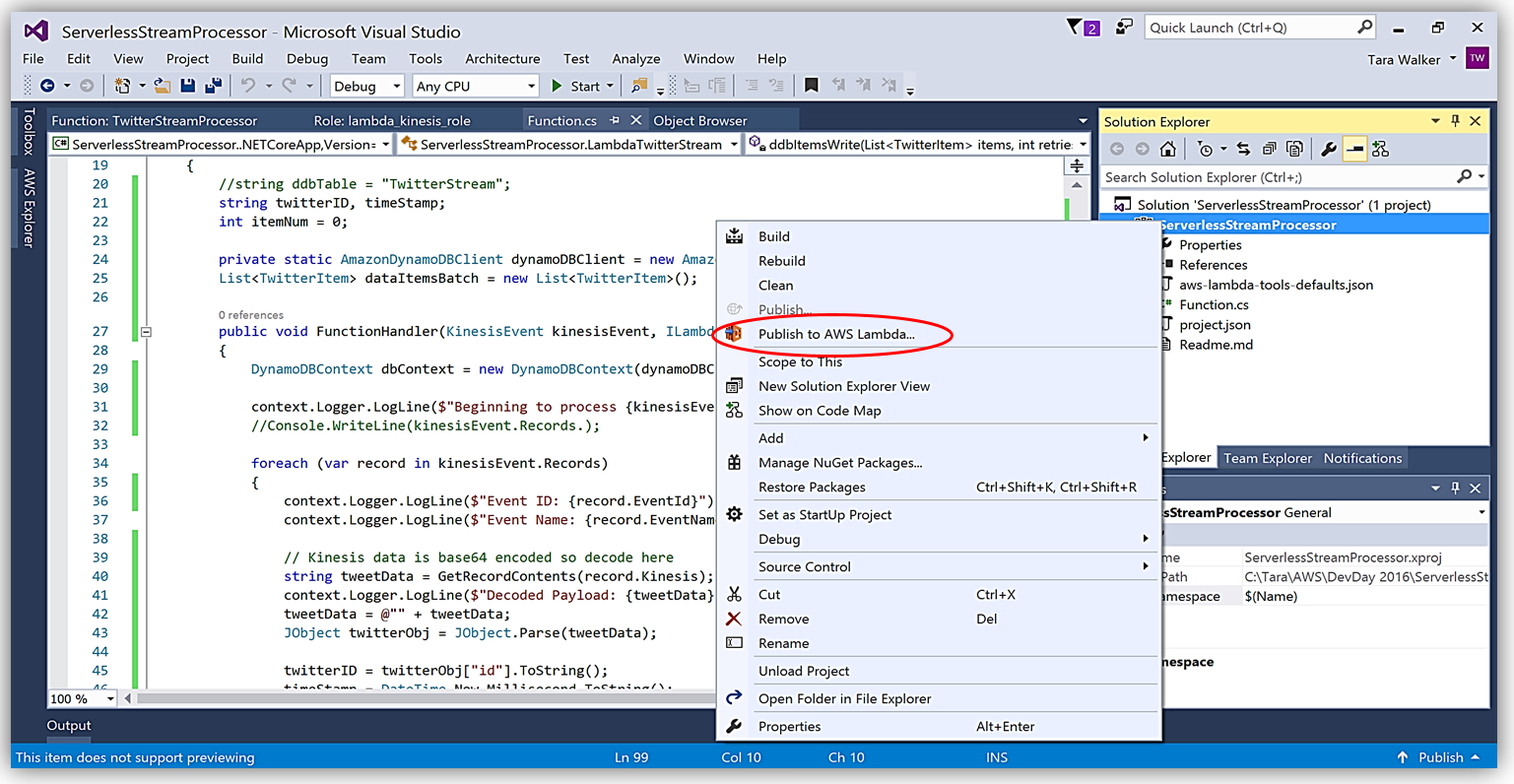
ハンドラー関数の署名は Assembly :: Namespace :: ClassName :: Method の命名法に従います。したがって、ここに示される C# Lambda 関数の署名は ServerlessStreamProcessor :: ServerlessStreamProcessor.LambdaTwitterStream :: FunctionHandler であることに注意してください。この情報は [Upload to AWS Lambda] ダイアログボックスに提供され、[Next] を選択して、関数にロールを割り当てます。


完了すると、AWS toolkit が提供するプラグイン (以下に示す) を使用して Lambda コンソールまたは Visual Studio で、Lambda 関数開発の反復アプローチのためにトリガーするイベントソースのサンプルデータを使用してテストできます。

C# 言語を使用した AWS Lambda 関数の作成に関しての詳細については、「AWS Lambda 開発者ガイド」、またはコンピューティングブログの C# のサポートを発表した投稿をご覧ください。
API Gateway 収益化および開発者ポータル
マイクロサービスモーメンタムに従ってきたのなら、マイクロサービスのソリューションを構成する個別のサービスへのアクセスと公開を管理するためにスマートエンドポイントの使用または REST API 経由での API gateway の使用 (またはその両方) が必要なアーキテクチャーパターンを認識している場合があります。Amazon API Gateway により RESTful API の作成と管理をして AWS Lambda 関数、外部 HTTP エンドポイント、他の AWS のサービスを公開できるようになります。加えて、Amazon API Gateway により、クライアントおよび外部開発者が、HTTP プロトコル、または、プラットフォーム/言語対象の SDK を介してデプロイされた API にアクセスできるようになります。AWS Marketplace の SaaS サブスクリプションの導入と API Gateway と AWS Marketplace との統合により、AWS Marketplace の API Gateway を使用して、作成した API を顧客が直接利用できるようにすることで、API の収益化が可能になりました。AWS のお客様は、既存の AWS アカウントを使用して、マーケットプレイスで公開されている API をサブスクライブして支払うことができます。API Gateway と AWS Marketplace との統合により、AWS Marketplace で開始するプロセスは簡単です。開始するには、Amazon API Gateway で、使用プラン機能を有効にしていることを確認する必要があります。

有効化した後、使用プランを作成します。目標のレートおよびバーストリクエストのしきい値を使用して、スロットリングを有効にし (必要に応じて)、最後に、一定のタイムフレームあたりの目標リクエストのクォータを指定して、クォータを有効にします (選択した場合)。

次に、使用プランと関連付ける API と関連するステージを選択します。特定の API を使用プランに関連付けることを選択できないため、これはオプションの手順であることに注意してください。

あとは、API キーを使用プランに追加または作成するだけです。使用プランの作成において、この手順もまたオプションであることにご注意ください。

使用プラン StreamingPlan ができたので、マーケットプレイスで API を販売する準備のための次のステップに進むことができます。さまざまな API とその制限を使用して、複数の使用プランを作成し、これらのプランを AWS Marketplace で、差別化された API 製品として販売するオプションがあります。

ただし、顧客が新しい API 製品を購入できるようにするため、AWS Marketplace では、各 API 製品にサブスクリプションリクエストを処理する外部開発者ポータルがあり、API の詳細情報および使用管理機能を提供する必要があります。このようなマーケットプレイスでの外部開発者ポータルに対する顧客のニーズにより、新しいオープンソース API Gateway 開発者ポータルサーバーレスウェブアプリケーションの実装が誕生しました。API Gateway 開発者ポータルプロジェクトの目標は、開発者のサインアップを許可しつつ、顧客が数ステップの簡単な手順に従って、API Gateway で構築した API のカタログをリスト表示するサーバーレスウェブアプリケーションを作成することです。API Gateway 開発者ポータルは AWS Serverless Express に構築されており、AWS により発行されたオープンソースライブラリーで、Node.js Express フレームワークを使用して、ウェブアプリケーション/サービスを構築するために AWS Lambda および Amazon API Gateway を利用する際に役立ちます。加えて、API Gateway 開発者ポータルアプリケーションは AWS SAM (サーバーレスアプリケーションモデル) テンプレートを使用して、そのサーバーレスリソースをデプロイします。AWS SAM は簡略化された CloudFormation テンプレートおよび仕様で、AWS でのサーバーレスアプリケーションの管理とデプロイを簡単にします。API Gateway ポータルを使用して開発者ポータルを構築するには、GitHub から aws-api-gateway-developer-portal プロジェクトをクローン作成することから始めます。

AWS CLI および Node.js の最新版をインストール済みであれば、Mac および Linux OS ユーザー用のコマンドラインで、“npm run setup” を実行して、開発者ポータルを設定します。Windows ユーザーは、コマンドラインで “npm run win-setup” を実行して、開発者ポータルを設定します。


結果として、S3 で実行する機能的なサンプル開発者ポータルウェブサイトができ、これをカスタマイズして独自の API 用の開発者ポータルを作成できます。

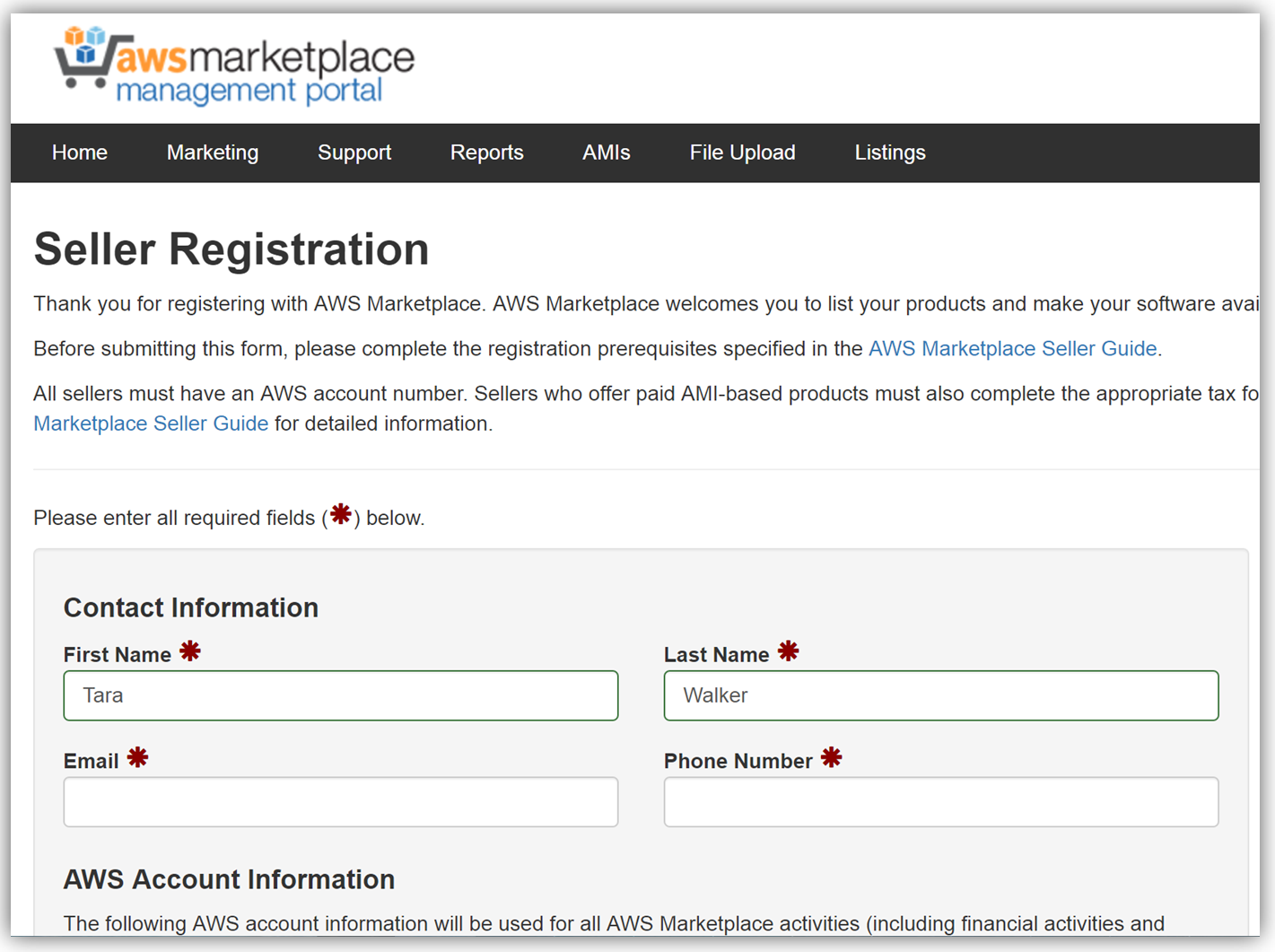
サンプルの開発者ポータルウェブサイトのフロントエンドは、React JavaScript ライブラリを使用して構築されており、バックエンドは aws-serverless-express ライブラリを使用して、AWS Lambda 関数が実行されています。加えて、SNS イベントソースを使用した Lambda 関数は、顧客が AWS Marketplace コンソールを介して API をサブスクライブまたはサブスクライブ解除する際の通知のためのリスナーとして作成されています。このリファレンスプロジェクトを使用した API Gateway 開発者ポータルウェブアプリケーションの構築、カスタマイズ、デプロイの手順についての詳細は、アーキテクチャと実装について詳細に説明している「AWS コンピューティングブログの投稿」を参照してください。 API を収益化する次の主なステップは、AWS Marketplace でアカウントを作成することです。アカウントをまだ作成していない場合、登録は「AWS Marketplace Seller Guide」で説明されている必要な前提条件を満たしていることを確認し、AWS Marketplace 管理ポータルのセラー登録フォームに入力するだけです。以下で、セラー登録フォームの冒頭のスナップショットを確認できます。
API を一覧表示するには、API を説明する製品ロードフォームに入力し、API の価格を設定して、API サブスクリプションプロセスをテストする AWS アカウントの ID を指定します。このフォームを入力する場合、API 開発者ポータル用の URL も送信する必要があります。販売者登録が完了したら、AWS Marketplace 製品コードが指定されます。Marketplace 製品コードを API 使用プランと関連付ける必要があります。この手順を完了するために、API Gateway コンソールにログインし、API 使用プランに移動します。[Marketplace] タブに移動し、製品コードを入力します。これにより、API Gateway は、API が使用されると測定データを AWS Marketplace に送信します。

Amazon API Gateway が管理する API が使用プランにパッケージ化され、付随する API 開発者ポータルが作成され、販売者アカウント登録が完了し、製品コードが API プランと関連付けられたので、AWS Marketplace で API を収益化する準備ができました。API Gateway で作成された API の収益化に関する詳細については、関連するブログの投稿と API Gateway 開発者ガイドドキュメントを確認してください。
要約
ご覧いただいたとおり、AWS チームは 2016 年中、サーバーレスアーキテクチャの作成およびデプロイにおける顧客エクスペリエンスを向上させるため、また、API Gateway が管理する API を生成し、収益をあげるためのメカニズムを提供するため努力してきました。AWS Lambda および Amazon API Gateway の製品のドキュメントをご覧になり、これらのサービス、およびすべての新しくリリースされた機能の詳細を確認してください。
– Tara
Amazon Aurora Clusterに監査機能を追加
re:InventでMySQLデータベースと互換性があり、コマーシャルデータベースの性能と可用性、オープンソースデータベースのコストパーフォーマンスの両面をそなえた、Amazon Auroraの新機能を発表しました。
今日、advanced auditing機能が全てのお客様にご利用頂けるようになったことを発表致します。
advanced auditingとは
Auditingとは特定のイベントを収集して手動もしくは他のアプリケーションで分析出来るように提供する機能を指します。これらのログはコンプライアンス規定やガバナンスのベースになる情報として利用可能です。advanced auditingの例には、ログ分析、ユーザーアクションの監査(過去のイベントおよび、ニアリアルタイムの脅威検出など)、セキュリティ関連のイベントに設定されたアラームのが含まれます。 Auroraのadvanced auditing機能は、データベースのパフォーマンスに与える影響を最小限に抑えながら、これらの機能を提供するように設計されています。
advanced auditingを利用するには
まずはじめに、advanced auditingを有効にし、audit logを参照します。
advanced auditingの有効化
DBクラスタパラメータグループにあるパラメータを設定することでadvanced auditingの有効化や設定を行うことができます。これらのパラメータの変更がDBクラスタの再起動は必要ありません。また、動作は Aurora DB instance parametersと同様です。
機能を有効/無効化するために server_audit_loggingパラメータを利用します。server_audit_eventsパラメータでどのイベントをログに記録するか設定します。
server_audit_excl_usersとserver_audit_incl_usersパラメータでどのユーザを監査対象にするか設定可能です:
- server_audit_excl_usersとserver_audit_incl_usersが未指定の場合(デフォルト値)は全てのユーザが記録されます
- server_audit_incl_usersにユーザを設定し、server_audit_excl_usersを指定しない場合、server_audit_incl_usersに指定したユーザのみ記録されます
- server_audit_excl_usersにユーザを設定し、server_audit_incl_usersを指定しない場合、server_audit_excl_usersに指定したユーザ以外が記録の対象になります
- server_audit_excl_usersとserver_audit_incl_usersに同一のユーザを設定した場合は、server_audit_incl_usersの優先度が高いため記録の対象になります
advanced auditingのパラメータの詳細を以下でご説明します
server_audit_logging 監査ログの有効/無効化を指定します。標準ではOFFになっているので、ONに指定することで有効になります
- Scope: Global
- Dynamic: Yes
- Data type: Boolean
- Default value: OFF (disabled)
server_audit_events イベントのリストをカンマで区切って指定します。リスト中のエレメント間にスペースは入れなように気をつけて下さい
- Scope: Global
- Dynamic: Yes
- Data type: String
- Default value: Empty string
- 有効な値: 以下のイベントの好きな組み合わせを指定可能
- CONNECT – ユーザ情報を含む、接続の成功・失敗・切断を記録
- QUERY – シンタックスや権限不足で失敗したクエリを含む、全てのクエリ文字列とクエリの結果をplane textで記録
- QUERY_DCL – DCLクエリのみを記録 (GRANT, REVOKEなど)
- QUERY_DDL – DDLクエリのみを記録 (CREATE, ALTERなど)
- QUERY_DML – DMLクエリのみを記録 (NSERT, UPDATEなど)
- TABLE – クエリの実行で利用されたテーブルを記録
server_audit_excl_users ログに記録しないユーザをカンマ区切りで指定します。エレメント間にスペースは入れないよう気をつけて下さい。接続・切断のイベントはこの設定に影響を受けないため記録されます。server_audit_excl_usersに指定されていたとしてもserver_audit_incl_usersにも指定されていた場合は、server_audit_incl_usersの優先度が高いため記録の対象になります
- Scope: Global
- Dynamic: Yes
- Data type: String
- Default value: Empty string
server_audit_incl_users ログに記録するユーザをカンマ区切りで指定します。エレメント間にスペースは入れないよう気をつけて下さい。接続・切断のイベントはこの設定に影響を受けません。ユーザがserver_audit_excl_usersに指定されていたとしても、server_audit_incl_usersの優先度が高いため記録の対象になります
- Scope: Global
- Dynamic: Yes
- Data type: String
- Default value: Empty string
audit logを参照する
AWS Management Consoleからaudit logを参照可能です。Instancesページから、DBクラスタを選択し、Logを選択します。

MariaDB Audit Pluginの事をご存知であれば、auditingについてAuroraが取っているアプローチとの幾つかの違いに気づくかと思います。
- Aurora advanced auditingのタイムスタンプはUnix timeフォーマットで記録されます
- イベントは複数のログファイルに記録され、ログはシーケンシャルには並んでいません。必要に応じてファイルの結合やタイムスタンプやquery_idを使用してソートを行えます。Unixをお使いの場合は以下のコマンドで実現出来ます。 cat audit.log.* | sort -t”,” -k1,1 –k6,6
- ファイル数はDBインスタンスサイズに応じて変化します
- ファイルのローテーションは100MB毎に行われ、閾値の変更は行なえません
MySQLからマイグレーションした後のAurora advanced auditingの有効化は方法が異なります。 Audit logの設定はDBクラスタ向けのパラメータグループで行ないます。
Auroraがどのようにadvanced auditingを実装したか
監査機能はコマーシャルデータベスでもオープンソースデータベース一般的に利用出来る機能です。この機能は一般的にパフォーマンスへ大きな影響を与えます。特にデータベースの利用率が高い場合は顕著です。Auroraでの実装の1つのゴールは様々な情報をパフォーマンスの犠牲なくユーザに提供することです。
パフォーマンスを維持するために
パフォーマンスの課題をどの様に解決したか理解するために、私達のadvanced auditingの実装とMariaDB Audit Pluginの実装を比較してみます。MySQL Community Editionではnative audit logを提供していないため、私たちは比較のためにこちらを利用します。そして、 MariaDB Audit Pluginはオープンソースコミュニティの中で、これらの制約を埋める一般的なオプションとしてあげられます。
MariaDB Audit Pluginは、シングルスレッドでシングルミューテックスを処理と各イベントの書き出しに利用します。このデザインは、ログの書き出しのボトルネックに起因するパフォ=マンスの低下を起こしますが、イベントの順序を厳密に保存することが出来ます。もし、このアプローチをAuroraに利用すると、データベースエンジンの期待するスループットや高いスケーラビリティにより、パフォーマンスへのインパクトが更に大きくなってしまいます。
高いパフォーマンスを維持するために、イベント処理とイベントの書き出しロジックを再設計しました。入力面では、ラッチフリーキューを他のスレッドをロックすること無くaudit logを保存するために利用しました。出力面では、ラッチフリーキューから複数のファイルへイベントを書き出すためにマルチスレッドモデルを利用しています。このファイルを処理することで、イベント順に並んだ1つの監査ログとして生成出来ます。
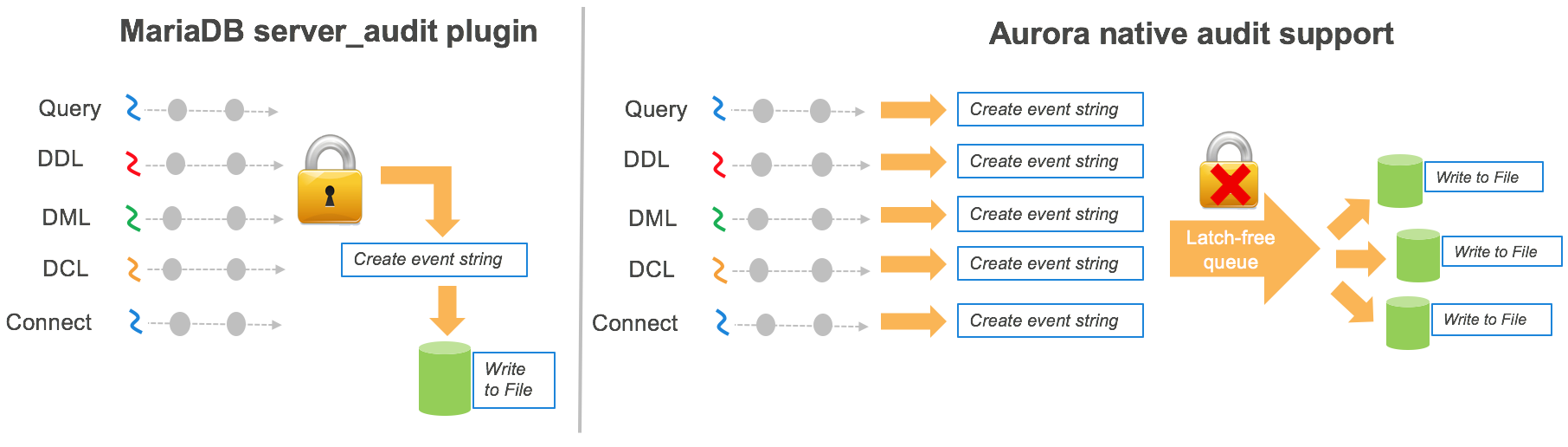
ログフォーマット
audit logは各インスタンスのローカル(エフェメラル)ディスクに保存されます。各Auroraインスタンスは4つのログファイルに書き込みます。
- Encoding: UTF-8
- ファイル名パターン: audit.log.0-3.%Y-%m-%d-%H-%M-rotation
- 保存場所: /rdsdbdata/log/audit/ (各ホスト毎)
- ローテーション: 各ログファイル毎に100MBで、現在は変更不可。4つのログファイルの内、もっとも大きなファイルサイズが100MBになった場合、システムは新しいログファイルのセットへローテーションを行ないます
- クリーンアップ: ディスクスペースを解放するために、ディスク消費量やファイルの世代に応じて古くなったaudit logを削除します
- ログフォーマット: timestamp,serverhost,username,host,connectionid,queryid,operation,database,object,retcode
| パラメータ | 説明 |
| timestamp | 秒精度のログが記録された時点のUnixタイムスタンプ |
| serverhost | ログが記録されたホスト名 |
| username | 接続ユーザ |
| host | ユーザの接続元ホスト |
| connectionid | ログを記録するためのコネクションID |
| queryid | 関連するテーブルやクエリを特定するために利用するクエリID。TABLEイベントでは複数行記録される |
| operation | 記録されたactionタイプ (CONNECT, QUERY, READ, WRITE, CREATE, ALTER, RENAME, DROP) |
| database | USEコマンドで指定されたデータベース名 |
| object | QUERYイベントでは、実行されたクエリ。TABLEイベントではテーブル名 |
| retcode | ログを記録するためのリターンコード |
他の方法と比較を行った場合
前述のように、多くのデータベースでは監査ログ機能が提供されていますが、監査機能が有効になっているとパフォーマンスが低下します。参照のみのワークロードを用いて、8xlargeインスタンス使用し、MariaDB Audit Pluginを有効にしたMySQL 5.7とパフォーマンス比較を行ないました。以下の結果のとおり、MySQLではAudit log機能が有効になっていると性能の大幅な低下が起こっています。Auroraでの性能低下は抑えられています。Auroraでは、15%の低下で抑えられていますが、MySQL5.7では65%の低下となっています。結果として、audit機能が有効になっている場合、AuroraのパフォーマンスはMySQL 5.7と比較して倍以上に向上しました。

Advanced auditingは本日からご利用頂けます!機能の詳細はドキュメントをご覧ください。
注: こちらの機能はAurora version 1.10.1からご利用頂けます (https://forums.aws.amazon.com/ann.jspa?annID=4349)
— Sirish Chandrasekaran (product manager at Amazon Web Services) (翻訳は星野が担当しました。原文はこちら)
Amazon ECS Task Placement Policyのご紹介
本日、Amazon ECSはクラスタ上にどのようにしてタスクを配置するかを汎用的に制御することのできる機能を発表しました。以前は、特定のリソースの要求(例えば、特定のインスタンスタイプ)を満たすコンテナインスタンス上にタスクを配置する必要がある時は、カスタムスケジューラを作成してリソースをフィルタし、発見し、グループ化する必要がありました。
次の図は、新しいタスク配置処理の概要を示しています:

これによって、コードを一切書かずともタスクがどのように配置されるかをカスタマイズすることができます。ECSは、インスタンスタイプやアベイラビリティゾーンの様な組み込み済の属性を付与していますし、加えてカスタムの属性もサポートしています。例えば、environment=productionといった属性でコンテナインスタンスをラベル付することができ、これらのリソースを見つけるためにList APIで操作することや、RunTaskとCreateService API操作でこれらのリソース上にタスクを配置することができます。
また、bin packやspreadといったplacement strategy (配置戦略)を使って、タスクがさらにどこに配置されるかを定義することもできます。ポリシーを連鎖させて洗練された配置を達成することもできます。例えば、g2.*のインスタンス上にのみタスクを配置し、アベイラビリティゾーンに渡って幅広く(spread)配置し、そして各ゾーンではメモリを基準にタスクをなるべく詰め込む(bin pack)というポリシーを作成できます。
はじめに、attribute (属性)を見てましょう。インスタンスタイプ等の組み込み済の属性を使って、コンテナインスタンスを見つけ、その上にタスクを配置することができます。以下の例では、クラスタ上の全てのt2インスタンスを見ることができます:
aws ecs list-container-instances --filter "attribute:ecs.instance-type matches t2.*"
{
"containerInstanceArns": [
"arn:aws:ecs:us-east-1:123456789000:container-instance/40f0e62c-38cc-4cd2-a28e-770fa9796ca1",
"arn:aws:ecs:us-east-1:123456789000:container-instance/eb6680ac-407e-42a6-abd3-1bbf57d7401f",
"arn:aws:ecs:us-east-1:123456789000:container-instance/ecc03e17-6cbd-4291-bf24-870fa9796bf2",
"arn:aws:ecs:us-east-1:123456789000:container-instance/fbc03e17-acbd-2291-df24-4324ab342a24",
"arn:aws:ecs:us-east-1:123456789000:container-instance/f9a69f54-9ce7-4f1d-bc62-b8a9cfe8e8e5"
]
}
続いて、us-east-1aのアベイラビリティゾーンにあるt2インスタンスのみをリストしています:
aws ecs list-container-instances --filter "attribute:ecs.instance-type matches t2.* and attribute:ecs.availability-zone == us-east-1a"
{
"containerInstanceArns": [
"arn:aws:ecs:us-east-1:123456789000:container-instance/40f0e62c-38cc-4cd2-a28e-770fa9796ca1",
"arn:aws:ecs:us-east-1:123456789000:container-instance/eb6680ac-407e-42a6-abd3-1bbf57d7401f",
"arn:aws:ecs:us-east-1:123456789000:container-instance/ecc03e17-6cbd-4291-bf24-870fa9796bf2"
]
}カスタム属性はECSのデータモデルを自身のカスタムメタデータ用にキーバリューのペアを使って拡張します。以下の例では、stack=prodという属性を特定のコンテナインスタンスに追加しています:
aws ecs put-attributes --attributes name=stack,value=prod,targetId=40f0e62c-38cc-4cd2-a28e-770fa9796ca1,targetType=container-instanceこれで、stack=prodという属性が付いていないコンテナインスタンスを見ることができます:
aws ecs list-container-instances --filter "attribute:stack != prod"
{
"containerInstanceArns": [
"arn:aws:ecs:us-east-1:123456789000:container-instance/eb6680ac-407e-42a6-abd3-1bbf57d7401f",
"arn:aws:ecs:us-east-1:123456789000:container-instance/ecc03e17-6cbd-4291-bf24-870fa9796bf2",
"arn:aws:ecs:us-east-1:123456789000:container-instance/fbc03e17-acbd-2291-df24-4324ab342a24",
"arn:aws:ecs:us-east-1:123456789000:container-instance/f9a69f54-9ce7-4f1d-bc62-b8a9cfe8e8e5"
]
}それでは、これらの属性をタスクのスケジューリングで使ってみましょう。constraint (制約)は、ECSがスケジューリングを決める時に評価される属性を基準としたルールのことです。constraint (制約)はMemberOfかDistinctInstanceを使ってタスクを配置するためにクラスタ内でインスタンスのサブセットを作成します。以下の例では、5つのタスクを、t2.smallかt2.mediumでus-east-1dのアベイラビリティゾーンではないインスタンスに起動しています:
aws ecs run-task --task-definition myapp --count 5 --placement-constraints type="memberOf",expression="(attribute:ecs.instance-type == t2.small or attribute:ecs.instance-type == t2.medium) and attribute:ecs.availability-zone != us-east-1d"
constraint (制約)に加えて、RunTask API操作する時やCreateService APIを使って新しいサービスを作成する時にはplacement strategy (配置戦略)も利用可能です。戦略のタイプは定義されていますが、カスタマイズしたり組み合わせることができます。サポートされる戦略タイプはRandom (ランダム)、Binpack (詰め込み)、そしてSpread (幅広く)です。以下の例では、アベイラビリティゾーンに渡って幅広く配置しながら、各ゾーンではメモリを基準に詰め込みをしています。
aws ecs run-task --task-definition myapp --count 9 --placement-strategy type="spread",field="attribute:ecs.availability-zone" type="binpack",field="memory"
広く配置して各ゾーンではメモリを基準に詰め込むが、g2.*のインスタンスタイプのみにタスクを配置したいと思ったとします。
placement policy (配置ポリシー)をECSコンソールで定義するために、Create serviceを選択します。Task placementセクションの中で、AZ Balanced BinPackというplacement template (配置テンプレート)を選び、Editを選択します。
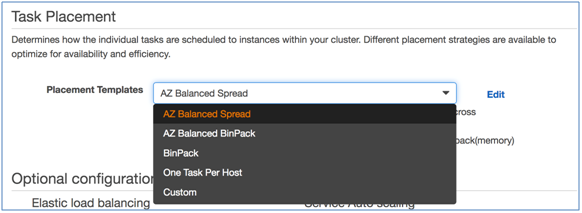
これでテンプレートをベースにしてカスタムポリシーを作成できます。テンプレートのConstraintセクションに、以下を追加します:
attribute:ecs.instance-type=~g2.*
これで、G2インスタンス上のみにタスクを配置し、タスクはアベイラビリティゾーンに渡って幅広く、そして各ゾーンではメモリが最も残り少ないインスタンスに配置するサービスを作ることができました。
まとめ
本日より、新しい属性をECSオブジェクトに追加し、より細かくECSリソースにクエリし、そして直接タスクを配置することができます。
ECS上のタスク配置についてより詳しく知りたい方は、Amazon ECS開発者ガイドのトピックか、re:Inventのセッションをご覧下さい。
ご質問やコメントがありましたら、以下のコメント欄をご利用下さい。
原文: Introducing Amazon ECS Task Placement Policies (翻訳: SA岩永)
Amazon Route 53 および AWS Shield を使用した DDoS リスクの軽減
2016 年 10 月後半に、著名な DNS プロバイダーが、複数のサービス妨害攻撃で構成された大規模なサイバー攻撃の標的となりました。数千万の IP アドレスからの大量の DNS 参照で構成された攻撃により、多くのインターネットサイトやサービスが北米および欧州のユーザーに対して利用できなくなりました。プリンター、カメラ、家庭用ネットワークゲートウェイ、さらにはベビーモニターといったさまざまなインターネッツ接続デバイスで構成されたボットネットを使用して、この分散サービス妨害 (DDoS) 攻撃が実行されたと考えられます。これらのデバイスは Mirai マルウェアに感染し、1 秒あたり数百ギガバイトのトラフィックを生成しました。多くの企業ネットワークや教育ネットワークは、このような規模のボリューメトリック攻撃を吸収するだけのキャパシティーを持っていません。この攻撃や、それ以前のその他の攻撃を受けて、さまざまなタイプの DDoS 攻撃に対してより弾力性の高いシステムを構築できるようにするための推奨事項やベストプラクティスについてお客様から当社に問い合わせがありました。簡単な回答としては、スケール、耐障害性、および緩和を組み合わせ (詳細については「AWS Best Practices for DDoS Resiliency」ホワイトペーパーを参照)、Amazon Route 53 および AWS Shield を利用することです (詳細については、「AWS Shield – Protect Your Applications from DDoS Attacks」を参照)。
スケール – Route 53 は数多くの AWS エッジロケーションでホストされ、大量の DNS トラフィックを吸収することができるグローバルな対象領域を作成します。Amazon CloudFront と AWS WAF を含むその他のエッジベースのサービスにもグローバルな対象領域があり、大量のトラフィックを処理することができます。
耐障害性 – 各エッジロケーションには、インターネットへの数多くの接続があります。これにより、多様なパスが可能になり、障害の分離と阻止に役立ちます。また、Route 53 はシャッフルシャーディングとエニーキャストストライピングを使って可用性を高めます。シャッフルシャーディングでは、委託セットの各ネームサーバーがエッジロケーションの一意のセットに対応します。この配置によって耐障害性が向上し、AWS のお客様間の重複が最小化されます。委託セットの 1 つのネームサーバーが利用できない場合、クライアントシステムまたはアプリケーションは別のエッジロケーションのネームサーバーを再試行し、レスポンスを受け取ります。エニーキャストストライピングは、最適な場所に DNS リクエストをダイレクトするために使用されます。これは、負荷を分散して DNS レイテンシーを減らす効果があります。
緩和 – AWS Shield Standard は、現在の最も一般的な攻撃の 96% からお客様を保護します。これには、SYN/ACK フラッド、反射攻撃、および HTTP スローリードが含まれます。私の投稿で前に述べたように、この保護は自動的かつ透過的に Elastic Load Balancing、CloudFront ディストリビューション、および Route 53 リソースに無料で適用されます。保護 (決定的パケットフィルタリングと優先順位をベースとしたトラフィック形成を含む) はすべての AWS エッジロケーションにデプロイされ、わずか数秒のオーバーヘッドですべてのトラフィックを検査します。すべては完全に透過的な方法で実行されます。
AWS Shield Advanced には、追加の DDoS 緩和機能、DDoS Response Team への年中無休のアクセス、リアルタイムのメトリクスとレポート、および DDoS コスト保護が含まれます。詳細については、「DDoS Resiliency」ホワイトペーパーを参照し、Route 53 エニーキャストについてご覧ください。
— Jeff;
新機能 – AWS OpsWorks for Chef Automate
![]() AWS OpsWorks は、Chef を使用したアプリケーションの設定と実行に役立ちます。ドメイン固有言語 (DSL) を使って、アプリケーションのアーキテクチャと各コンポーネントの設定を定義するクックブックを記述します。Chef サーバーは、設定プロセスで不可欠な要素です。このサーバーはすべてのクックブックを保存し、各インスタンス (Chef の用語ではノード) の状態情報を追跡します。Chef サーバーは新しく起動されたインスタンスが設定されるときは重要なパスにあるため、信頼性が高い必要があります。多くの OpsWorks および Chef ユーザーは、この重要なアーキテクチャコンポーネントを自分でインストールして維持しています。本稼働スケールの環境では、これによりバックアップ、復元、バージョンのアップグレードなどをユーザーが処理する必要があります。
AWS OpsWorks は、Chef を使用したアプリケーションの設定と実行に役立ちます。ドメイン固有言語 (DSL) を使って、アプリケーションのアーキテクチャと各コンポーネントの設定を定義するクックブックを記述します。Chef サーバーは、設定プロセスで不可欠な要素です。このサーバーはすべてのクックブックを保存し、各インスタンス (Chef の用語ではノード) の状態情報を追跡します。Chef サーバーは新しく起動されたインスタンスが設定されるときは重要なパスにあるため、信頼性が高い必要があります。多くの OpsWorks および Chef ユーザーは、この重要なアーキテクチャコンポーネントを自分でインストールして維持しています。本稼働スケールの環境では、これによりバックアップ、復元、バージョンのアップグレードなどをユーザーが処理する必要があります。
新しい AWS OpsWorks for Chef Automate
今月初めに、AWS OpsWorks for Chef Automate が AWS re:Invent ステージから開始されました。Chef Automate サーバーは、わずか 3 回のクリックで起動し、数分以内に使用を開始することができます。Chef Supermarket をはじめ、Test Kitchen や Knife などのコミュニティツールからのコミュニティクックブックを使用できます。Chef Automate を使用すると、アプリケーションのインフラストラクチャのライフサイクルを通じてインフラストラクチャを管理できます。たとえば、新しく起動した EC2 インスタンスは自動的に Chef サーバーに接続し、自動関連付けスクリプトを使用して、指定されたレシピを実行できます (詳細については、「AWS OpsWorks for Chef Automate でのノードの自動的な追加」を参照)。登録スクリプトを使用して、Auto Scaling グループを通じて動的に作成された EC2 インスタンスを登録し、オンプレミスサーバーを登録できます。
詳しく見る
OpsWorks コンソールから Chef Automate サーバーを起動してみましょう。開始するには、[Go to OpsWorks for Chef Automate] をクリックします。

[Create Chef Automate server] をクリックし、サーバーに名前を付けます。次にリージョンを選択し、適切な EC2 インスタンスタイプを選択します。

SSH キーペアの 1 つを選択するか、SSH からオプトアウトします。

最後に、ネットワーク (VPC)、IAM、メンテナンスウィンドウ、およびバックアップの設定を指定します。

[Next] をクリックし、設定を確認して、[Launch] をクリックします。起動プロセスにかかる時間は 20 分未満です。その時間中に、スターターキットとともに Chef Automate ダッシュボードのサインイン認証情報をダウンロードできます。

すべての Chef Automate サーバーを一目で表示できます。

サーバー名 (ここでは BorkBorkBork) をクリックし、[Open Chef Automate dashboard] をクリックします。次に、認証情報を入力してログインします。

ダッシュボードを次に示します。

ノードを表示して管理できます。

ワークフローを管理する

ほかにもさまざまな機能があります。バックグラウンドでは、起動プロセスによって AWS CloudFormation テンプレートが呼び出されます。このテンプレートにより、EC2 インスタンス、Elastic IP アドレス、およびセキュリティグループが作成されます。
今すぐご利用可能
AWS OpsWorks for Chef Automate は、US East (Northern Virginia)、US West (Oregon)、および Europe (Ireland) リージョンで今すぐご利用できます。料金はサーバーに接続されたノードの数と時間数に基づきます。詳細については、Chef Automate の料金表ページを参照してください。AWS Free Tier の一部として、12 か月当たり最大 10 ノードまでは無料で使用できます。
— Jeff;
毎日集計される料金表の通知 ~ AWS料金表API
昨年、AWS のお客様とパートナーから、AWS のサービスの料金を取得するためのシステム的な方法を求める要望が寄せられました。このニーズに対して、昨年 12 月に 13 の AWS のサービスの料金を対象とした AWS の料金表 API を発表しました。この API は、ダウンロード用に JSON および CSV 形式で料金表データを提供し、お客様は AWS のサービスの料金を問い合わせることができます。料金表 API では、Amazon SNS 通知を通じて料金変更の更新情報を受け取ることもできます。
AWS 料金表の API の拡張
過去 3 か月に、当社は AWS の料金表 API サービスを拡張し、すべての AWS のサービスについて料金表データを提供するようにしました。クラウドベースのソリューションの構築またはクラウドへのオンプレミスワークロードの移行に関するコスト分析を行っているお客様は、AWS のサービスの包括的な料金表にこれまでよりも簡単にアクセスできます。これにより、お客様とパートナーは、クラウドソリューションの予算、予測、および計画をより詳細に管理できます。AWS の料金表 API の拡張に加えて、お客様はサインアップして割引料金、新しいサービスやインスタンスタイプの通知を受け取ることができます。通知の受信のサブスクライブの際は、更新情報を受け取るタイミングをカスタマイズでき、1 日 1 回、または料金の更新が発生するたびに設定できます。1 日 1 回の通知を選択した場合、SNS 通知にはその日に適用されたすべての料金変更が含まれます。料金表 API にサブスクライブした場合に受け取る E メール通知のサンプルを次に示します。

料金表 API の使い方を簡単に見てみましょう。最初に、料金表 API を介して料金情報にアクセスし、オファーインデックスファイルとオファーファイルという 2 種類のファイルをダウンロードします。オファーインデックスファイルは JSON ファイルとして利用でき、サポートされている AWS のサービスと、関連するサービスオファーファイルの URL が記載されています。このオファーファイルでは、単一の AWS のサービスに関する製品や料金が一覧表示され、CSV または JSON ファイル形式として利用できます。両方とも単純なダウンロードリンクを介してアクセスでき、簡単な方法で料金表データファイルを入手できます。
今すぐ料金表 API の使用を開始し、いずれの AWS のサービスについても、料金表データを入手できます。AWS の料金表 API の拡張によりすべての AWS のサービスが対象になったことで、料金表 API へのサブスクライブにより、最新の AWS の割引料金の情報を受け取るとともに、新しいサービスの紹介を受けることができます。
AWS の料金表 API の詳細、および API 通知へのサブスクライブ方法の詳細については、サービスについて紹介している前の AWS ブログ投稿、および AWS の料金表 API の使用に関するドキュメントを参照してください。
– Tara
事前にご確認ください – AWSにおける2016年12月31日(日本時間2017年1月1日)のうるう秒
2016年末最後の数秒をカウントダウンする場合は、最後に1秒を追加するのを忘れないようにしてください!
次回のうるう秒(通算27回目)が、UTC(世界標準時)の2016年12月31日 23:59:60として挿入されます(訳注:日本標準時では2017年1月1日 8:59:60になります)。これは地球上での時刻(協定世界時)と太陽時(天文時)とのずれを小さくするために行われ、この結果、UTCでは今年最後の1分は61秒あることになります。
- 参考)「うるう秒」挿入のお知らせ(総務省)
前回のうるう秒の際に出した情報(事前にご確認ください – AWSでのうるう秒対応)は引き続き有効で、今回も同様に処理されますが、少しの違いと進展があります:
AWS調整時刻(AWS Adjusted Time) –うるう秒挿入前後の24時間の期間にわたって、うるう秒の1秒を少しずつ分散します(UTCで12月31日の11:59:59から、2017年1月1日12:00:00まで)。AWS調整時刻と協定世界時はこの期間が終了後に同期します。(訳注:この期間の1秒をごくわずかに遅くすることで、追加される1秒を長い時間のなかに分散する方法であり、これは前回うるう秒挿入時と同じ挙動です。詳しくは前回の情報をご確認ください。)
Microsoft Windows – Amazonによって提供されたMicrosoft WindowsのAMIを利用しているインスタンスは、AWS調整時刻に従います。
Amazon RDS – 大多数のAmazon RDS インスタンスは (UTCで設定されている場合)“23:59:59” を2回記録します。しかし、Oracle 11.2.0.2、11.2.0.3、12.1.0.1 はAWS調整時刻に従います。Oracle 11.2.0.4と12.1.0.2について詳細な情報が必要な場合はAWSサポートにお問い合わせください。
サポートが必要ですか?
このうるう秒挿入についてご質問がある場合は、AWSサポートにコンタクトいただくか、EC2フォーラムにポストしてください。
— Jeff;
翻訳:下佐粉 昭(@simosako)
原文:https://aws.amazon.com/blogs/aws/look-before-you-leap-december-31-2016-leap-second-on-aws/