
Featured Article
NCBI is phasing out sequence GIs - use Accession.Version instead!

As of September 2016, the integer sequence identifiers known as "GIs" will no longer be included in the GenBank, GenPept, and FASTA formats supported by NCBI for sequence records. The FASTA header will be further simplified to report only the sequence accession.version and record title for accessions managed by the International Sequence Database Collaboration (INSDC) and NCBI’s Reference Sequence (RefSeq) project. As NCBI makes this transition, we encourage any users who have workflows that depend on GI's to begin planning to use accession.version identifiers instead. After September 2016, any processes solely dependent on GIs will no longer function as expected.
Read more...All Articles
January 31st NCBI Minute: New version of E-utilities supports accession.version

Next Tuesday, January 31, 2017, NCBI will present a short webinar that describes and demonstrates new functionality recently introduced to the E-utilities that supports sequence data retrieval.
RefSeq release 80 now available; GI identifiers to be removed in next release (March 2017)

RefSeq release 80 is now accessible online, via FTP and through NCBI's programming utilities. This full release incorporates genomic, transcript, and protein data available as of January 9, 2017 and contains 118,059,547 records, including 78,028,152 proteins, 17,862,608 RNAs, and sequences from 66,224 organisms. The release is provided in several directories as a complete dataset and also as divided by logical groupings.
New videos on YouTube: Clone DB and clone placements
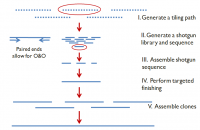
Two new videos on the NCBI YouTube channel demonstrate how to use Clone DB and clone placements to assess and improve genome assemblies.
GenBank release 217.0 is available via FTP

GenBank release 217.0 (12/15/2016) has 198,565,475 traditional records containing 224,973,060,433 base pairs of sequence data. In addition, there are 395,301,176 WGS records containing 1,817,189,565,845 base pairs of sequence data, 142,094,337 TSA records containing 125,328,824,508 base pairs of sequence data, as well as 1,268,690 TLS records containing 584,697,919 base pairs of sequence data.
Genome Workbench 2.11.7 now available

The latest version of Genome Workbench includes a number of new features, fixes and improvements like a critical improvement in HTTPS protocol communication with NCBI, improved rendering for translation discrepancies, and improved handling of tracks.