


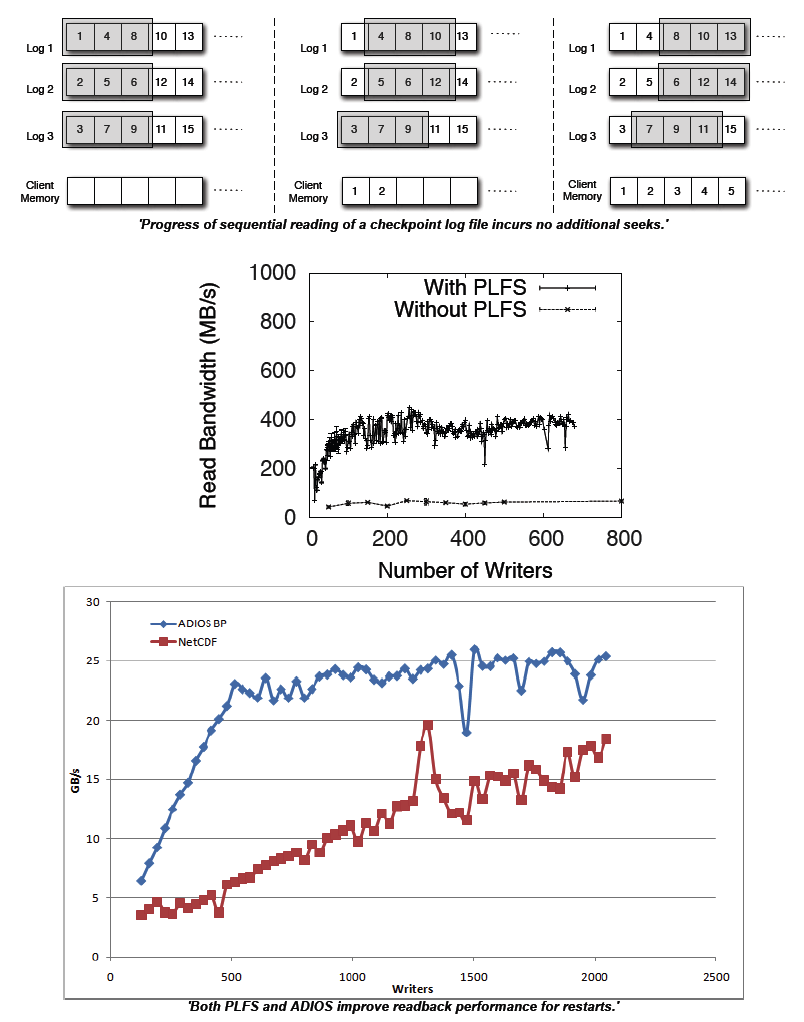
As HPC applications run on increasingly high process counts on larger and larger machines, both the frequency of checkpoints needed for fault tolerance and the resolution and size of Data Analysis Dumps are expected to increase proportionally. In order to maintain an acceptable ratio of time spent performing useful computation work to time spent performing I/O, write bandwidth to the underlying storage system must increase proportionally to this increase in the checkpoint and computation size. Unfortunately, popular scientific self-describing file formats such as netCDF and HDF5 are designed with a focus on portability and exibility. Extra care and careful crafting of the output structure and API calls is required to optimize for write performance using these APIs. To provide sufficient write bandwidth to continue to support the demands of scientific applications, the HPC community has developed a number of I/O middleware layers, that structure output into write-optimized file formats. However, the obvious concern with any write optimized file format would be a corresponding penalty on reads. In the log-structured filesystem, for example, a file generated by random writes could be written efficiently, but reading the file back sequentially later would result in very poor performance. Simulation results require efficient read-back for visualization and analytics, and though most checkpoint files are never used, the efficiency of a restart is very important in the face of inevitable failures. The utility of write speed improving middleware would be greatly diminished if it sacrificed acceptable read performance. In this paper we examine the read performance of two write-optimized middleware layers on large parallel machines and compare it to reading data natively in popular file formats.

Milo Polte
CMU Student

Garth Gibson
CMU Instructor

James Nunez
Mentor

John Bent
Mentor

Meghan McClelland
Mentor
Ben McClelland
Mentor
Direct storage of simulation output into data intensive subsystems

Grant Mackey
UCF Student

Jun Wang
UCF Instructor

Gary Grider
Mentor
John Bent
Mentor

This project explores how well suited data intensive computing programming/run time paradigms like map reduce and other graphs apply to scientific applications.

Julio Lopez
CMU Instructor
Gary Grider
Mentor
James Nunez
Mentor
John Bent
Mentor

Salman Habib
Mentor
Thomas Brettin
Mentor
Pavel Senin
Mentor
Tony Heaton
Mentor

Michael Fisk
Mentor
Laura Monroe
Mentor

The concept is to head HPC file system storage towards file formats in the file system. It is quite possible that many file types like N processes to 1 file with small strided writes might be served well by special handling at the file system level. Decades ago, file types and access methods were used and were supported within a single file system. The IBM MVS storage systems allowed for many different file types, partitioned data sets, indexed sequential, virtual sequential, and sequential to name a few. Storage for modern HPC systems may benefit from a new parallel/scalable version of file types. There is much research to be done in this area to determine the usefulness of this concept and how such a thing would work with modern supercomputers and future HPC languages and operating environments.
Milo Polte
CMU Student
Garth Gibson
CMU Instructor
Gary Grider
Mentor
James Nunez
Mentor
John Bent
Mentor


