|
The NCICB Open Development Initiative (ODI) is an exciting opportunity for members of the
bioinformatics community to extend the work being done by NCICB staff and contractors.
Are you an innovator, a pioneer? Do you find yourself wondering "why not" versus "why",
"what if" versus "what" and "let’s do it" versus "when will they"?
Do you long to participate in the development and deployment of leading edge analytic and
knowledge tools, designed to help solve difficult and complex problems?
This is the place for you!
The NCICB ODI offers the opportunity to get involved in shaping the next frontier for
NCICB software development as we pursue our vision of rapidly expanding the suite of
applications and infrastructure. We can’t do it alone. We don’t want to do it alone.
We need your creative talents, your unrestrained enthusiasm and ideas to enhance and grow
the next generation of bioinformatics tools. Over the remainder of this year this initiative
will mature, now is the time to get in on the ground floor!

The NCI’s goals are lofty: to eliminating pain, suffering and death from cancer by the year 2015.
The NCICB’s goals are to provide the enabling bioinformatics technology to achieve these goals.
Don’t be left behind! Come join the new NCICB frontier! (yes, the NCICB is a federal agency, a not for
profit enterprise, and we want you!)
If you are interested in learning more about the NCICB Open Development Initiative, or would
like to begin contributing, please contact us at
NCICBOpenDevelopment@mail.nih.gov
and be sure to mention which project you are interested in.
The caCORE is made up of several modules. Currently this includes
caDSR,
CSM, and
EVS.
The caCORE Software Development Kit (SDK) is an enabling tool to build applications
adhering to the same principles as caCORE.
The development teams for individual modules have identified unique requirements for their
specific domains and the developers should take note of them before
embarking on development activity.
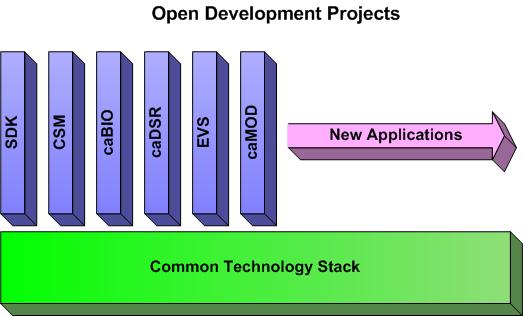
As seen in the above figure, all the projects at NCICB are based on a common technology stack.
Using a common set of tools facilitates interoperability between various projects.
All contributors are required to adhere to following set of tools. Currently, the common
tools are JDK 1.4.2_06, JBoss 4.0.1sp1 and Apache 1.33. Please contact individual project teams for
any additional tools and also for the latest versions of the tools before proceeding with development
activity.
All NCICB produced software products follow rigorous release planning activities. The caCORE
release process is described by the release process  document. The list of required deliverables
for individual projects during each stage of the development phase is described in the
deliverables document.
All documents will be based on standard templates followed at NCICB. document. The list of required deliverables
for individual projects during each stage of the development phase is described in the
deliverables document.
All documents will be based on standard templates followed at NCICB.
Below is a list of common project components that should be leveraged, where applicable, on each project
supporting the NCICB.
Software Architecture Specification Document
Implementation Specification Document
Please consult with the project teams for other templates that are being used.
Once selected, contributors are expected to participate in all the release planning activities
such as developing design documents, attending status meetings, performing code reviews and
testing their components in an integrated environment. An overview of the development partner process
is available at Open Source Development Partner Checklist.
The process is designed with flexibility to fit the needs of the product, contributors and NCICB.
All NCICB-developed caCORE components are distributed under open-source licenses that
support usage by both non-profit and commercial entities. All open source contributions
will be covered by this licensing policy. For additional details, please refer to license policy
for individual projects.
NCICB is willing to work with institutions participating in ODI if they would like to be
recognized in the license policy for the specific projects.
The CVS repository for the NCICB projects are built nightly based on new development activity.
To see a read-only view of our ODI CVS repository, please visit http://cabigcvs.nci.nih.gov/viewcvs/viewcvs.cgi/?cvsroot=opendevelopment .
To check out a copy of an ODI source module for local editing only, you will require a username
and password from NCICB, as well as a CVS client installed on your computer. To request a
username and password, along with instructions for connecting to the ODI CVS repository,
please contact us at the email address above. Please include your name and affiliation.
At this time, we are limiting such access to actual contributors, or those who wish to
examine the code for the purpose of becoming contributors
All caCORE-compatible systems are built on four primary principles:
- Model Driven Architecture
- n-tier architecture with open APIs
- Use of controlled vocabularies
- Registered metadata
The use of Model Driven Architecture and n-tier architecture are both standard software
engineering practices, and many tools exist to assist developers. The remaining principles are
less common in conventional software practice and required specialized tools
that were generally unavailable. As a result, the NCICB (in cooperation with the NCI Office of Communications)
developed the Enterprise Vocabulary Services (EVS) system to supply controlled vocabularies,
and the caDSR was developed to provide a dynamic metadata registry.
When all four principles are addressed, the resulting system has several desirable properties:
- n-tier architecture with its open APIs frees the end user (whether human or machine) from needing to understand the implementation details of the underlying data system to retrieve information.
- The maintainer of the resource can move the data or change implementation details (Relational Database Management System, etc) without affecting the ability of remote systems to access the data.
- Most importantly, the system is ‘semantically interoperable’; that is, there exists runtime retrievable information that can provide an explicit definition and complete data characteristics for each object and attribute that can be supplied by the data system.
Model Driven Architecture is a software development practice that uses a structured modeling
language to describe the requirements, objects, and interactions of a data system prior to
its construction. When coupled with a design process such as the Rational Unified Process (RUP)
and Extreme Programming (XP), it can greatly assist in the production of quality software
delivered in a timely fashion. At NCICB, caCORE is modeled using the UML, coupled with a
fusion of the Rational Unified Process and XP.
A typical client-server system is a two-tier system (the client and the server
that returns the data). This has the advantage of simplicity, but it ties the client
very tightly to the details of the implementation model. To isolate the client from the
implementation details, a data system can be built with one or more layers of ‘middleware’,
software whose purpose is to act as a bridge between the server and the client. If changes are
made to the server, the middleware is modified so that the client sees a consistent interface
(API).
We expect that the contributors to the ODI will possess a good understanding of these principles.
|