| Home > In the genome > Focus on genes > Background > Gene structure | |
|
|
There are two general types of gene in the human genome: non-coding RNA genes and protein-coding genes. Non-coding RNA genes represent 2-5 per cent of the total and encode functional RNA molecules. Many of these RNAs are involved in the control of gene expression, particularly protein synthesis. They have no overall conserved structure. Protein-coding genes represent the majority of the total and are expressed in two stages: transcription and translation (see Gene expression ). They show incredible diversity in size and organisation and have no typical structure. There are, however, several conserved features.
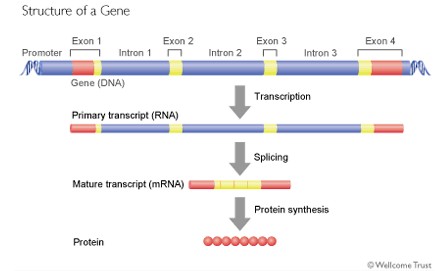
The boundaries of a protein-encoding gene are defined as the points at which transcription begins and ends. The core of the gene is the coding region, which contains the nucleotide sequence that is eventually translated into the sequence of amino acids in the protein. The coding region begins with the initiation codon, which is normally ATG. It ends with one of three termination codons: TAA, TAG or TGA. On either side of the coding region are DNA sequences that are transcribed but are not translated. These untranslated regions or non-coding regions often contain regulatory elements that control protein synthesis (see Figure). Both the coding region and the untranslated regions may be interrupted by introns. Most human genes are divided into exons and introns. The exons are the sections that are found in the mature transcript (messenger RNA), while the introns are removed from the primary transcript by a process called splicing (see Gene expression ). The smallest protein-coding gene in the human genome is only 500 nucleotides long and has no introns. It encodes a histone protein (see Epigenetics ). The largest human gene encodes the protein dystrophin, which is missing or non-functional in the disease muscular dystrophy. This gene is 2.5 million nucleotides in length and it takes over 16 hours to produce a single transcript. However, more than 99 per cent of the gene made up of its 79 introns. |
|
| Gibbs Building, 215 Euston Road, London NW1 2BE, UK tel:+44 (0)20 7611 8888 email:genome@wellcome.ac.uk | Privacy statement|Disclaimer |