|
| |
||
| |
|||||||||||||||||
|
|||||||||||||||||
|
|||||||||||||||||
|
EID Home | Ahead of Print | Past Issues | EID Search | Contact Us | Announcements | Suggested Citation | Submit Manuscript PDF
Version | Download Adobe
Acrobat | Comments | |
|
Dispatch Predicting Quarantine Failure RatesTroy Day*
Preemptive quarantine (isolating asymptomatic persons who have had contact
with an infected person) is an effective technique for slowing the spread
of emerging infectious diseases, but it also results in many uninfected
persons being isolated (for examples, see [1,2]). Health
officials must determine an acceptable quarantine duration that balances
the social and financial costs of holding potentially uninfected persons
for long durations with the risk of releasing an infected person into
the general public before he or she displays symptoms, if a shorter duration
is used (the quarantine failure rate, This approach requires considerable effort, and it must be carried out for each new disease. This assessment of quarantine failure rates is also necessarily retrospective, with the data required for analysis becoming available only after the fact. Here a much simpler approach is derived that requires no data specific to the disease in question. It applies for all possible infectious diseases, and therefore can be employed proactively rather than retrospectively. If the quarantine duration is chosen to be the longest incubation period
in a sample of n infections, then the probability,
for all possible infectious diseases (Appendix). For
example, the probability that the quarantine failure rate is no larger
than 1% is simply Often it is of more interest to estimate the quarantine failure rate
at a prescribed level of certainty. By rearranging equation 1, we have:
with
For example, the 95% confidence boundary for the failure rate is simply
Moreover, a point estimate for the failure rate is obtained by calculating
the expectation of Indeed, more generally the probability density of quarantine failure
rate, The above results also allow one to evaluate the protocol of using the
largest incubation period of n infected hosts as the quarantine
duration. For example, if n = 35 (a reasonable value for a newly
emerging disease) then the point estimate for Alternatively, the above results can be used to determine the sample
size, n, on which the quarantine duration must be based to ensure
that the quarantine failure rate is less than
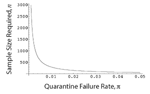
This is plotted in the Figure, indicating that enormous sample sizes are required to ensure that the quarantine failure rate is <1%. Together, the above results therefore call for two amendments to preemptive quarantine protocols. First, update the quarantine duration as further infections are observed during an outbreak. This amendment keeps n as large as possible. Secondly, set the quarantine duration to be longer than the maximum observed incubation period during the initial stages of the epidemic, when the sample size, n, is necessarily small.
References
Appendix: Explanation of Formula for Predicting Quarantine Failure RatesLet L be a random variable denoting the incubation period, and
f (l) and F (l) be its probability density
function (p.d.f.) and cumulative distribution function. Let M be
a random variable denoting the maximum incubation period in a sample of
n infections. The p.d.f. of M is then given by nf (m)F
(m)n-1. In other words, the probability
that, after n draws the maximum incubation period is m,
is given by the product of the probability that one draw yields an incubation
period of exactly m (i.e., nf (m)dm) with
the probability that the remaining n – 1 draws all yield incubation
periods no larger than m (i.e., F (m)n-1).
Now introduce a new random variable, X = F (m) (lying
in [0,1]), representing the probability that an infected host will have
an incubation period no larger than m (where F is the same
cumulative distribution function introduced above). The p.d.f. of X
is where G (x) is defined to be the inverse of F( x). The quarantine failure rate is 1-X, and
therefore its p.d.f., n-n
|
||||||||||||||||||
|
|
||||||||||||
|
||||||||||||
|
|
|
EID Home | Top of Page | Ahead-of-Print | Past Issues | Suggested Citation | EID Search | Contact Us | Accessibility | Privacy Policy Notice | CDC Home | CDC Search | Health Topics A-Z |
||
|
This page posted January
26, 2004 |
||
|
Emerging
Infectious Diseases Journal |
||