A Bayesian Network Model of Two-Car Accidents
MARJAN SIMONCIC*
ABSTRACT
This paper describes the Bayesian network method for modeling
traffic accident data and illustrates its use. Bayesian networks
employ techniques from probability and graph theory to model complex
systems with interrelated components. The model is built using
two-car accident data for 1998 from Slovenia, and inferences are
made from the model about how knowledge of the values of certain
variables influences the probabilities for values of other variables
or outcomes (e.g., how seat-belt use affects injury severity). An
advantage of the Bayesian network method presented here is its
complex approach where system variables are interdependent and where
no dependent and independent variables are needed.
KEYWORDS: Road accidents, modeling, Bayesian networks, machine learning.
INTRODUCTION
This paper presents a Bayesian network model of two-car accidents
based on different factors that influence accident outcomes. The
outcomes examined are "fatality or serious injury" and "other
outcomes." Influencing factors include:
- road characteristics (e.g., roadway, pavement),
- traffic flow characteristics,
- time/season factors (e.g., weather, season, weekday, daytime,
rush hour),
- characteristics of the people involved in an accident (e.g.,
age, sex, driving experience, health status, intoxication),
- use of protective devices (seat belt, air bag),
- types of vehicles (especially their crash resistance design),
and
- speed of the vehicles involved.
Besides these factors, other stochastic influences affect the
likelihood of an accident and its outcome. The factors presented
above are highly interrelated. For instance, road conditions are
influenced by the weather. Traffic flow depends on the time of the
day, whether it is a weekday or weekend, and weather conditions. The
characteristics of people involved (e.g., age, sex, experience) can
often be related to the speed of the vehicles in an accident and the
use or non-use of seat belts. The outcome of an accident is, by and
large, dependent on the speed of the vehicles involved.
A large road accident dataset was used to model the
interdependence among the variables related to accidents ("knowledge
of the subject") and the dependence of the outcome on the relevant
variables. Bayesian networks1
seem particularly useful for representing knowledge in domains where
large sets of interrelated (and relevant) data are available. They
are based on a combination of probability theory, which deals with
uncertainty, and graph theory, which deals with complexity
(interrelatedness). These networks are an important tool in the
design and analysis of machine learning algorithms and are based on
the idea of modularity whereby a complex system is built by
combining simpler parts. Probability theory connects parts and
ensures the consistency of the system as a whole while providing the
possibility of interfacing the models with the data (see Jordan
1999). This paper aims to show that Bayesian networks can also prove
their potential in modeling road accidents.
BAYESIAN NETWORKS
A Simple Example of a Bayesian Network
This section presents a simple Bayesian network for road
accidents. The example is merely for illustrative purposes and is
not intended to present a valid model. The aim is to introduce the
concept of Bayesian networks by example.
Using a given geographic area, the number of road accident
casualties per day can be schematically explained. Many factors are
interrelated: the number of road casualties depends on how many
trips car drivers took in the area and the danger level; the number
of trips is related to weather conditions and the season (e.g.,
summer means more vacation travel); season and weather are also
related; the level of danger is influenced by the average speed of
vehicles on the roads and on road conditions (e.g., a slippery
road); and road conditions depend on the weather and season and
influence the average speed and level of danger. Figure
1 presents these relationships in a directed acyclic graph where
the nodes correspond to different variables that are characteristic
of the given domain under consideration. Links2
in the graph represent dependence between variables, and acyclic
means that there is no node from which it is possible to follow a
sequence of (directed) links and return to the same node.
Let us suppose that all variables can only take on a finite
number of discrete values. We are interested in identifying the
probabilities of different events expressed in given values for all
variables. This can be expressed with a joint probability
distribution over all possible events in the given domain. The
number of possible events grows exponentially with the number of
relevant variables and, therefore, the joint probability function
approach quickly becomes unmanageable. Bayesian networks can
streamline the process, because they are a compact way of factoring
the joint probability distribution into local, conditional
distributions that reduce the number of multiplications necessary to
obtain the probability of specific events.
If we interpret the Bayesian network in probabilistic terms, the
related joint distribution function over a given domain can be
written (described by n variables) with the product3:
 (1) (1)
where Xi is the variable and
xi is its value; Pa (Xi)
is the set of variables that represents Xi's
parents4
and pa(Xi) is a vector of actual values for
all parents of Xi.
Let us note here the general validity of the chain rule
formula:
P ( x1 , x2,…,
xn) = P ( x1) P
(x 2 | x1 ) •
P (
x3 | x1, x2
)…P (xn | x1 ,
x2 ,…, xn-1)
From our example in figure 1, we have:
P ( x1 , x2 ,…,
x7) = P ( x1 ) P (
x2 | x1 ) •
P (
x3 | x1 , x2)
P ( x4 | x1 ,
x2) P ( x5 | x3
) •
P ( x6 | x3
, x5) P ( x7 |
x4 , x6)
Aside from the global semantics reflected in equation (1), there
is also a local meaning related to a Bayesian network. From figure
1, we see:
P ( x4 | x1 ,
x2 , x3) = P (
x4 | x1 ,
x2)
where X4 is independent of the variable
X3 given X1 and
X2 (reflecting the fact that X3
is not among the parents of X4 ). These local
semantics are very useful for constructing a Bayesian network. Here,
only direct causes (or predispositions) are selected as the parents
of a given variable, which leads to the automatic fulfillment of
local independence conditions.
Links in Bayesian networks may have different meanings. If we
have a link from node A to node B, this could mean:
1. A causes B,
2. A partially causes or predisposes B,
3. B is an imperfect observation of A,
4. A and B are functionally related, or
5. A and B are statistically correlated.
This paper employs the second meaning of a link.
Bayesian networks for a certain domain can be used for inference
purposes. With the network in figure 1, we will illustrate the
meaning of inference and also show the difference between a Bayesian
network model and better known classical models, such as logistic
regression. After a product specification (equation (1)) of a joint
probability distribution is obtained, the probability of any event
in the domain can be expressed. Conditional events where certain
variables have known values are especially interesting. This type of
probabilistic inference is called a belief update. An example for
the domain represented in figure 1 is the following:



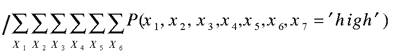
For illustrative purposes, we have assumed that one possible
value of the variable X 3 (road conditions) is
"slippery." This variable can also take on other values. A similar
description holds for variable X 7 . This
expression can be further simplified, but this is unnecessary here.
Let us now illustrate the difference between the Bayesian network
model and the classical logistic regression (for logistic regression
see Agresti (1990) or Hosmer and Lemeshow (2000)). The most
significant difference is that with logistic regression the model's
dependent and independent variables must be chosen; while, with the
Bayesian network model, all variables are treated equally. The
logistic regression has a response (or dependent) variable Y
that is a categorical variable with J ( J ≥ 2) classes
and a vector X (with p components) of explanatory (or
independent) variables that are also categorical5
variables. Here, Y could be the number of casualties (with
Y = 1 for "high" and Y = 0 for "other"). The
components of vector X could be the six other variables from
figure 1. The generalized logit model can be put in the following
way:
 (2) (2)
If the attributes X are also 0/1 variables, then the
following formula is valid6:
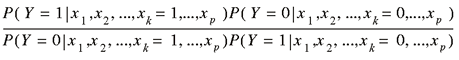
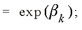
k = 1, 2, ..., p
The expression is called the odds ratio and allows an easy
interpretation of the estimated parameters7.
In the logit model for figure 1, exp( βk ) is the
odds that the number of casualties will be high in the circumstances
given by variable xk = 1 relative to the odds that
the number of casualties will not be high in the circumstances given
by variable xk = 0.
It is obvious that the model shown in equation (2) does not
explicitly take into account eventual interdependence between
variables of X, nor does it allow for an estimation of other
probabilities that could be of interest (e.g., the belief update
given as an example for the network in figure 1). Interdependences
among variables in a Bayesian network are explicit and represent a
distinguishing feature of the method.
The general problem of computing posterior probabilities (or of a
belief update) for large and structurally more complex Bayesian
networks is computationally very demanding (more precisely:
NP-hard). The computational burden was the reason that the inference
in Bayesian networks was initially limited only to special types of
structures, namely tree-structured networks. Later, efficient
algorithms were proposed for more general types of network
structures (Lauritzen and Spiegelhalter 1988; Zhang and Poole
1996).
Formal Definition of Bayesian Networks
Bayesian networks contain qualitative (structural) and
quantitative (probabilistic) parts. The qualitative part is based on
statistical independence statements and can be represented by a
directed acyclic graph. The nodes are related to random variables of
interest for a given domain, while the links correspond to a direct
influence among the variables. The quantitative part is captured by
local probability models, given by a set of conditional probability
distributions. Both the qualitative and quantitative parts of the
Bayesian network uniquely represent the joint probability
distribution over a domain. The definitions follow.
Definition 1. A Bayesian network B is a triplet
(X, A, P) where:
- X is a set of nodes
- A is a set of links that, together with X,
represent a directed acyclic graph:
G = (X, A)
- P = {P (x | pa(x)):xε
X }
where Pa(X) is the set of parents of X, and
pa(x) is its instantiation8.P
stands for probability.
It is clear that P is the set of conditional probabilities
for all variables, given their parents. From definition 1, the
conclusion can be drawn that nodes and variables are used
interchangeably. Variables in a Bayesian network are called nodes
when we speak about the graph.
Graph G corresponding to a Bayesian network has to be acyclic. If
cycles were allowed, the feedback influence would be enabled. It is
well known that feedback cycles are difficult to model
quantitatively and no calculus has been developed for the Bayesian
network to cope with these.
The notion of conditional independency is a basic concept of
Bayesian networks. We say that (random) variables A and
B are independent given the variable C if the
following is true:
P(A|B,C) = P(A|C)
This means that if the value of variable C is known, then
knowledge of B does not alter the probability of
A.
The Bayesian network provides a graphic representation of many
independency relationships that are embedded in the underlying
probability model. No formal definitions are provided here, but it
should be understood that the mathematical conception of
d-separation is fundamental relative to independence (Jensen 2001).
The next definition gives the global interpretation of Bayesian
networks.
Definition 2. The prior joint probability
PB of a Bayesian network B is defined by
the following expression:

The factorization in definition 2 rests on a set of local
independence assumptions, asserting that each variable is
independent of its predecessors9
in the network, given its parents. The opposite is also true. We can
use the interdependence in constructing Bayesian networks from
expert opinion, because selecting as parents all the direct causes
of a given variable satisfies the local conditional independence
conditions (Pearl 2000).
For the Bayesian network from figure 1, the prior joint
probability is equal to:
PB(x) =
PB(X1 =
x1,X2 =
x2,…,X7 =
x7)
= P (X1 = x1) P
(X2 = x2 | X1
= x1)
•
P (X3 = x3 |
X1 = x1, X2 =
x2)
•
P (X4 = x4 |
X1 = x1, X2 =
x2)
•
P (X5 = x5 |
X3 = x3)
•
P (X6 = x6 |
X3 = x3, X5 =
x5)
•
P (X7 = x7 |
X4 = x4, X6 =
x6) •
When we have a joint probability distribution defined on a set of
variables X, we can calculate the probability distribution of
any subset S of X. This calculation is called
marginalization and is very useful in inference exercises on
Bayesian networks.
Definition 3. Let S be a subset of the set of
variables X. The marginal probability
PB(S) is defined by

Let us now suppose that some variables have specific values. In
our example from figure 1, variables X7 and
X3 may be observed to have values "high"
(X7) and "slippery" (X3). If
Y ⊆ X is the set of variables with actual (observed)
values, Y0 is the corresponding vector of values
and X1 ⊆ X is the set of variables of
interest (X1 ⊆ X − Y), then the following
definition of posterior probability is useful.
Definition 4. The posterior probability
PB ( X1 | Y =
Y0) of X1 of
X1
is defined by the expression
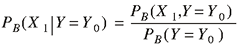
THE MODEL
Data
This paper focuses on road accidents in which two car drivers
were involved. The empirical part is based on data from the road
accidents database assembled by the Slovenian Ministry of the
Interior from police reports. For the model, 1998 data containing
36,704 Slovenian police accident reports were used. From this total,
17,558 (48%) were of the selected type. To illustrate the risk of
Slovenian drivers being involved in a two-car accident, some basic
data show that, in 1998, 797,855 cars were registered in Slovenia
(the country has 2 million inhabitants). Because we are looking at
accidents involving two cars, we know that approximately 4% of the
Slovenian car fleet was involved in accidents of this type that
year.
Table
1 presents data on two-car accidents for selected variables.
Variables from Accident_type to Cause (the first column of table 1)
are related to the accident, while variables from Age to Injury are
related to the drivers10.
The share of accidents that resulted in a fatality or serious injury
of at least one person is 1.9%. Over 70% of accidents occur in
built-up areas and more than half happen in good weather and under
normal traffic conditions. Among participants, the lion's share
corresponds to drivers 25 to 64 years old, yet the share of drivers
under 25 years of age is also relatively high (23%). For drivers
involved in accidents, a significant proportion has less than one
year of driving experience (12.9%). Only a small share of drivers
involved in accidents was intoxicated (4.3%).
Bayesian Network Estimation
A Bayesian network for a given domain can be estimated using
different approaches. This paper uses a template model that should
not vary from one problem to another. Our purpose here is to
estimate a fixed Bayesian network over a given set of variables,
obtained by a combination of expert judgment and empirical data.
Specifications for some alternative possibilities for estimating a
Bayesian network are presented below.
A difficult part of building a Bayesian network is quantifying
probabilities, which can be derived from various sources:
- from domain experts (subjective probabilities),
- from published statistical studies,
- derived analytically, or
- learned directly from raw data.
This paper uses the last option, mainly because of the
availability of a relatively large database.
Sometimes the process of learning the structure of a Bayesian
network (if necessary) may be even more difficult than quantifying
probabilities. According to the structure, models can be classified
as those with a known structure or those with an unknown structure.
We experimented with both options.
There are basically two different approaches to learning the
structure of a Bayesian network from data: 1) search and scoring
methods and 2) dependency analysis methods. In the first approach,
different scoring criteria are used for evaluating competing
structures. Two of the well-known methods of this type are the
Bayesian scoring method (Cooper and Herskovits 1992) and the minimum
description length method (Lam and Bacchus 1994). Because learning a
Bayesian network structure by a search and score approach is
NP-hard, different heuristic searches have been proposed. Algorithms
from the second group try to discover the dependences among
variables from data and then use them to infer the structure. During
this process, a conditional independence test, usually based on the
concept of mutual information of two nodes (variables), X and
Y, is used
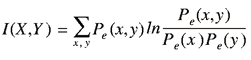
In this expression, Pe denotes the observed
relative frequencies in the dataset. Conditional mutual information
is defined analogously:

Z can be a single node or a set of nodes. Mutual
information I is non-negative and equal to 0 when X
and Y are conditionally independent. The higher the mutual
information, the stronger the dependence between X and
Y. In heuristic algorithms a certain threshold ε is
usually used: if I(X,Y) is smaller than ε, then
X and Y are taken as marginally independent.
Similarly, if I(X,Y|Z) is smaller than ε, we
consider X and Y as conditionally independent given
Z.
All these methods can be expected to find the correct structure
only when the probability distribution of the data satisfies certain
assumptions. But generally both types of methods find only
approximations for the true structure.
According to the available data, models for learning Bayesian
networks can be classified into those with complete data available
or those with incomplete data available. In the first case, all
variables are observed for all instances in the database while, in
the second case, values for some variables may be missing or some
variables may not even be observed (hidden variables). Because the
available database used for this paper contains complete data, the
first possibility is relevant.
Variables Considered in the Model
Some conditions of an accident may be called exogenous. They are
tied to the accident and happen without the volition or action of
the drivers involved. Variables from table 1 in this category
are:
- weather condition,
- weekday,
- settlement (whether an accident occurs in a built-up area or
not), and
- daytime (whether an accident occurs during the night or day).
These external conditions influence some internal and objective
conditions also tied to the accident, such as traffic and the
roadway. For each accident, these conditions are also exogenous11.
Besides these internal and objective conditions, there are also
internal subjective (and not volitional) conditions that relate to
the drivers involved:
- age and sex,
- driving experience,
- intoxication (alcohol), and
- use of a seat belt.
Objective and subjective internal conditions influence the cause
of an accident. The particular cause further influences the outcome
of the accident. Here, only two types of accident outcomes are
considered: a fatality or serious injury, and other12.
Subjective internal conditions and the cause of an accident
influence the type of driver injury.
Different network structures can reflect these conditions. In the
process of finding a suitable network structure, we experimented
with PowerConstructor. PowerConstructor (Cheng et al. 2001) is a
computer program that can estimate the Bayesian network structure if
a database of cases is available. The method (Cheng et al. 1997)
used in PowerConstructor for comparing competing structures is of
the dependency analysis type and requires
O(n4) conditional independence tests
(n being the number of variables). The program is able to
take into account additional restrictions on variables (e.g.,
partial ordering, forbidden links, roots, leaves, and causes and
effects).
For this research, external variables and the variables related
to the driver (e.g., age, sex, and experience) were among the root
nodes (links can only point out of such nodes). Variables relating
to the type of accident and the drivers' injuries were put among the
leaf nodes (links can only point into such nodes). The variable
related to the fault of the two drivers involved was also put among
the leaves. PowerConstructor produced results pretty much as
anticipated, except for some links that were missing.
Our anticipation was also based on some relevant findings from
the literature. Kim (1996) analyzed the differences between male and
female involvement in motor vehicle collisions in Hawaii and found
that male drivers are:
- 4 times more likely than female drivers to not wear a seat
belt,
- 3.6 times more likely than female drivers to be involved in
alcohol-related collisions,
- 2 times more likely than female drivers to be involved in
speed-related collisions, and
- 1.3 times more likely than female drivers to be involved in
head-on collisions.
For the relationship between road accident severity and recorded
weather, Edwards (1998) based her conclusions on data from police
reports and found that:
- accident severity decreases in rain as compared with good
weather,
- accident severity in fog shows geographical variation, and
- evidence for accident severity in high winds is inconclusive.
It is also well known that older drivers are more likely to be
killed if involved in a fatal crash than younger drivers. Based on
these results and common sense, additional restrictions for
PowerConstructor included the following links:
- Age → Injury (older drivers are expected to be more prone to
serious injuries than younger drivers)
- Seat belt → Injury (drivers not wearing a seat belt are likely
to be more vulnerable)
- Experience → At-fault driver (drivers with little driving
experience are more likely to be at fault)
- Sex → Seat belt use
- Sex → Alcohol
- Alcohol → At-fault driver
The resulting network is presented in figure
2. It is evident that only a small number of all theoretically
possible interdependences was found to be important.
Weekday, daytime, and weather conditions influence traffic. An
assumption was made that the share of intoxicated drivers is greater
for accidents that happen at night than during the day. Only weather
influences road conditions13
.The type of accident and the use of a seat belt also depend on
whether an accident happens in a built-up area or not (settlement
variable). A smaller share of drivers wearing a seat belt in
built-up areas was expected.
Figure 2 also takes into account the different characteristics of
drivers. Drivers with little driving experience are more likely to
be at fault in an accident than more experienced ones. There are
also significant differences between men and women, with women being
more likely to use seat belts than men. On average, older drivers
are more prone to serious injuries than younger ones.
The central variable in figure 2 is the cause of an
accident14,
which is influenced by road, weather, and traffic conditions and by
the variable related to driver intoxication. Finally, the outcome of
an accident (defined as the most serious injury to participants in
an accident) is largely conditioned by the cause of the
accident.
The estimated structure seems plausible, but a different one may
also be acceptable. The scoring functions used in the optimizing
approach could shed some light on the quality of the estimated
Bayesian network. Furthermore, the Kullback-Leibler measure of
divergence could be used. Its value could be computed for the
structure at hand but would only be of interest when comparing two
or more specific structures. By presenting the most probable
explanation (MPE), the corresponding probability, and the relative
frequency obtained from the database, the statistical quality of the
given network can be seen. MPE is given by the most probable
configuration of values for all variables in the Bayesian network.
For the estimated structure, the MPE is given by the following
values for variables:
Night = No; Weekday = Wrk (working day); Weather = Bright;
Settlement = Yes; Experience = E11–Inf (driver's experience of 11
years or more); Sex = Male; Age = A25–64; Seat_belt = Yes; Alcohol =
No; Alco12 = No; Roadway = Dry; Traffic = Norm (normal); Cause = PV
(car maneuvers); At-fault_driver = No; Injury = Oth (other then
fatality or serious injury); Accident_type = Oth
Given the estimated structure of the Bayesian network and the
conditional probabilities for each node, the probability of the MPE
can be computed as shown below.
P(MPE) = P(Night = No) • P(Weekday = Wrk) •
P(Weather = Bright) • P(Settlement = Yes) •
P(Experience = E11–Inf) • P(Sex = Male) • P(Age
= A25–64) •
P(Roadway = Dry|Weather = Bright) •
P(Traffic = Norm|Weather = Bright, Weekday = Wrk, Night = No)
•
P(Belt_use = Yes|Sex = Male, Settlement = Yes) •
P(Alcohol = No|Night = No, Weekday = Wrk, Sex = Male) •
P(Alco12 = No|Night = No, Weekday = Wrk) •
P(At-fault_driver = No|Experience = E11–Inf, Alcohol = No)
•
P(Cause = PV|Roadway = Dry, Traffic = Norm, Weather =
Bright, Alco12 = No) •
P(Injury = Oth|Age = A25–64,
Belt_use = Yes) •
P(Accident_type = Oth|Settlement = Yes,
Cause = PV) = 0.0018
An examination of databases for 1998 and 1999 produced the
following relative frequencies for MPE:
Pe(1998) = 94 / 35116 = 0.00268
Pe(1999) = 103 / 39950 = 0.00258
It is obvious that even the most likely explanation has a small
probability of its appearance. A comparison of P(MPE)
and Pe(MPE) can serve as an indication of
the quality of the estimated Bayesian network.
Figure
3 presents probabilities (also called beliefs) estimated from
the database of accidents for 1998 and based on the assumption of
the network structure given in figure 2. Values of variables related
to the different nodes are self-explanatory. Let us recall the
abbreviation used for accident type and injury: 1) Fos means
a fatality or serious injury, and 2) Oth means other (less
serious) outcomes. (Abbreviations for values related to the variable
Cause are explained in table 1.) Figure 3 shows only the
unconditional probabilities that correspond to each node (and not
the conditional probabilities discussed earlier).
INFERENCE IN THE BAYESIAN NETWORK
The discussion here focuses on only three tables with specific
inference results. For the inference process, Netica software
(Norsys 1997) was used, and it proved to be very convenient and
effective. Results are presented in tables 2 to 4 where
predetermined values for a selected categorical variable (or
variables) are given in the first column and probabilities for
variables of interest are seen in other columns.
Table
2 shows inference results based on evidence for the variable
related to the type of accident. Inference results are presented
only for variables Cause, Settlement, Night, and Alco12. The
probability that the cause of the accident is inappropriate speed
(HI) is 0.279 in the case of accident type "Fos" (fatality or
serious injury) and 0.134 for the accident type "Oth" (less severe
injury). The odds ratio is therefore 2.1. Only a slightly smaller
odds ratio is found for cause SV (wrong side/direction); a similar
odds ratio for the Settlement variable (2.2); smaller odds ratios
for variables Night and Alco12; and odds ratios smaller than 1 for
cause PV (car maneuvers), OS (other), and VR (safety distance).
Table
3 reports the inference results based on the evidence for the
intoxication variables (Alcohol and Alco12). The probability of an
accident taking place at night is 0.752 if drivers are intoxicated
and 0.206 if they are not. The odds ratio is, therefore, 3.7. Odds
ratios are also high for variables Sex, At_fault, and Cause (for the
values related to inappropriate speed and driving on the wrong side
of the road).
Inference results based on the evidence for some exogenous
variables are presented in table
4. The results shown correspond to a risky situation (driving at
night, outside built-up areas, on the weekend, and in rainy weather)
and to risky demographic variables (young and inexperienced drivers,
i.e., males less than 25 years of age and less than 1 year of
driving experience). Nonrisky values were defined with the opposite
values for binary variables. For other (non-binary) variables, the
following values were used: age between 24 and 65, driving
experience more than 11 years, and for the weekday the working day.
Odds ratios are especially high for the type of accident and
intoxication variables.
While more inference results and a complete picture of the
influence on all variables are available, this paper presents only
the more interesting variables because the primary aim is to
illustrate the capabilities of Bayesian networks in this domain of
knowledge. A more indepth analysis of inference results could be
used for detecting any weaknesses in the Bayesian network and for
improving its structure. By using data for more than one year, the
results become more reliable. New variables can also be added, for
example, actual data on traffic flows on the road sections on which
accidents occur or other specific characteristics of roads and
regions.
CONCLUSIONS
This paper deals with road accidents involving two car drivers. A
model of such accidents is presented to capture the interrelations
between different relevant variables. To this end, Bayesian networks
that have proved their modeling capabilities in different knowledge
domains were used. The paper first introduces Bayesian networks on a
small example and then formally defines them. After presenting data
on two-car accidents for Slovenia in 1998, a structure is proposed
based on knowledge of the domain and on computer experiments. For
this structure the corresponding probabilities were estimated from
the available database. We then demonstrate how the estimated
Bayesian network can be used for drawing inferences. Inference
results are consistent with expectations as far as the direction of
influence is concerned.
The estimated Bayesian network can be regarded as a compact and
structured representation of the given database of two-car
accidents. This representation relates to specific types of
accidents in a given country and year. It also enables different
inferences, but other methods, such as logistic regression, should
also be used.
Based on the research presented here, we feel that Bayesian
networks can be fruitfully applied in the domain of road-accident
modeling. Compared with other well-known statistical methods, the
main advantage of the Bayesian network method seems to be its
complex approach where system variables are interdependent and where
no dependent and independent variables are needed. The method's
chief weakness is the somewhat arbitrary search for an appropriate
network structure. Nevertheless, the results shown here are
encouraging and point to possible directions for improvement, such
as including more variables and larger datasets that cover more
years. Extending the Bayesian network (with good performance
results) into a decision network is another possibility.
ACKNOWLEDGMENTS
The Ministry of Science and Education of the Republic of Slovenia
supported this research. Thanks go to anonymous referees for
suggestions on improving this paper and to Jie Cheng for providing
his PowerConstructor software for use with the data. Any errors,
however, remain ours alone.
REFERENCES
Agresti, A. 1990. Categorical Data Analysis.
New York, NY: Wiley & Sons.
Cheng, J., D.A. Bell, and W. Liu. 1997. Learning
Belief Networks from Data: An Information Theory Based Approach.
Proceedings of the Sixth ACM International Conference on Information
and Knowledge Management.
____. 2001. Learning Belief Networks from Data: An
Efficient Approach Based on Information Theory. Available at http://www.cs.ualberta.ca/%7Ejcheng/bnpc.htm,
as of January 24, 2005.
Cooper G.F. and E. Herskovits. 1992. A Bayesian Method
for the Induction of Probabilistic Networks from Data. Machine
Learning 9:309–347.
Edwards, J.B. 1998. The Relationship Between Road
Accident Severity and Recorded Weather. Journal of Safety
Research 29(4):249–262.
Hosmer, D.W. and S. Lemeshow. 2000. Applied
Logistic Regression. New York, NY: Wiley & Sons.
Jensen, F.V. 2001. Bayesian Networks and Decision
Graphs. New York, NY: Springer-Verlag.
Jordan, M.I., ed. 1999. Learning in Graphical
Models. Cambridge, MA: The MIT Press.
Kim, K.E. 1996. Differences Between Male and Female
Involvement in Motor Vehicle Collisions in Hawaii, 1986–1993.
Proceedings from the Second National Conference. Available at http://www.durp.hawaii.edu.
Lam, W. and F. Bacchus. 1994. Learning Bayesian Belief
Networks: An Approach Based on the MDL Principle. Computational
Intelligence 10:269–293.
Lauritzen, S.L. and D.J. Spiegelhalter. 1988. Local
Computations with Probabilities on Graphical Structures and Their
Application to Expert Systems. Journal of the Royal Statistical
Society B 50(2):157–194.
Norsys Software Corp. 1997. Netica Application
User's Guide. Vancouver, Canada.
Pearl, J. 2000. Causality. Cambridge, UK:
Cambridge University Press.
Zhang, N.L. and D. Poole. 1996. Exploiting Causal
Independence in Bayesian Network Inference. Journal of Artificial
Intelligence Research 5:301–328.
END NOTES
1 Some similar or synonymous
concepts are graphic models, belief networks, probabilistic
networks, independence networks, causal networks, and Markov
fields.
2 In Bayesian network
literature, the terms vertex and edge are sometimes
applied instead of node and link.
3 The probability of the
event A is denoted by P (A).
4 Node A is the parent of
node B if there is a link from A toward B in the graph.
5 In a general logistic
regression, they are not limited to only these types of
variables.
6 A similar interpretation
is possible if we have categorical variables with more than two
values.
7 Explanatory variables can
be interdependent. Their interdependence plays a role in the
estimation of these parameters (see chapter 2 in Hosmer and Lemeshow
2000).
8 When the state of a
variable is known, we say that it is instantiated. We have an
instantiation of a set of variables if each variable is instantiated
(Jensen 2001).
9 A is a predecessor
of B if a directed path (a sequence of links) exists from
A to B.
10 Passengers are taken
into account only indirectly. A fatal accident may mean that both
drivers were only injured, but at least one passenger was
killed.
11 It is assumed that an
individual driver does not significantly influence traffic
conditions.
12 The variable
Accident_type is related to the accident, while the variable Injury
is related to the driver. This presents no problem for an analysis
with Bayesian networks.
13 New variables could have
been added here but were not in order to maintain a more manageable
total number of variables.
14 This is partly
conditioned by the large number of possible states (seven) and by
the method used in PowerConstructor.
ADDRESS FOR CORRESPONDENCE
*M. Simoncic, Institute for Economic Research, Kardeljeva pl. 17, Ljubljana, Slovenia. Email: simoncicm@ier.si
|

