Using Generalized Estimating Equations to Account for
Correlation in Route Choice Models
MOHAMED ABDEL-ATY *
ABSTRACT
This paper presents the use of binary and multinomial generalized
estimating equation techniques (BGEE and MGEE) for modeling route
choice. The modeling results showed significant effects on route
choice for travel time, traffic information, weather, number of
roadway links, and driver age and education level, among other
factors. Each model was developed with and without a covariance
structure of the correlated choices. The effect of correlation was
found to be statistically significant in both models, which
highlights the importance of accounting for correlation in route
choice models that may lead to vastly different travel forecasts and
policy decisions.
KEYWORDS: Route choice, repeated observations,
overlapping routes, BGEE, MGEE, logit.
INTRODUCTION
How and when travelers make decisions about what route they will
take to their destination is an area of great interest to
researchers and decisionmakers alike. In this paper, binary and
multinomial generalized estimating equation techniques (BGEE and
MGEE) are used to model route choice.
Binary and multinomial route choice models may have two different
kinds of correlation. First, repeated observations may be
correlated. This is usually the case for studies that use
surveys/simulations where each respondent/subject provides repeated
responses. Second, the overlapping distance between alternative
routes may be correlated in multinomial route choice models. In a
multinomial route choice model, the case is further complicated when
the data structure includes both types of correlation.
In the 1980s, most discrete choice models were calibrated using
binary logit (BL) and multinomial logit (MNL) models (Yai et al.
1997). BL and MNL models characterize the choice of dichotomous or
polytomous alternatives, made by a decisionmaker (in our study, the
driver) as a function of attributes associated with each alternative
as well as the characteristics of the individual making the choice.
An advantage of both BL and MNL models is their analytical
tractability and ease of estimation. However, a major restriction of
MNL models is the Independence from Irrelevant Alternatives (IIA)
property, which arises because all observations are assumed to have
the same error distribution in the utility term based on a Gumbel
distribution (IIA arises because the assumption of being Independent
and Identically Distributed is made for the Gumbel). Therefore, BL
and MNL models assume independence between observations, which is
not true if each subject/driver has more than one observation. Also,
MNL models assume independence between alternatives, which is not
true when routes overlap.
A major statistical problem with cluster-correlated data, for
which BL/MNL models do not account, arises from intracluster
correlation or the potential for cluster mates to respond similarly.
This phenomenon is often referred to as overdispersion or extra
variation in an estimated statistic beyond what would be expected
under independence. Analyses that assume independence of the
observations will generally underestimate the true variance and lead
to test statistics with inflated Type I errors (Louviere and
Woodworth 1983).
Gopinath (1995) demonstrated that different model forecasts
result when the heterogeneity of travelers is not considered.
Delvert (1997) argued that models of travel behavior in response to
Advanced Traveler Information Systems must address heterogeneity in
behavior. When we cannot consider the observations to be random
draws from a large population, it is often reasonable to think of
the unobserved effects as parameters to estimate, in which case we
use fixed-effects methods. Even if we decide to treat the unobserved
effects as random variables, we must also decide whether the
unobserved effects are uncorrelated with the explanatory variables,
which is the case in many situations. To draw accurate conclusions
from correlated data, an appropriate model of within-cluster
correlation must be used. If correlation is ignored by using a model
that is too simple, the model would underestimate the standard
errors of modeling effects (Stokes et al. 2000).
This paper reviews the existing methodologies for route choice
modeling that account for one or both types of correlation mentioned
above. The advantages and drawbacks of each methodology are stated.
The main objective of this paper is to suggest a methodology (used
in other fields) that accounts for correlation in binary and
multinomial route choice modeling. BGEE and MGEE techniques are
introduced with a binomial logit link function for BGEE and
polytomous logistic link function for MGEE. The advantage of these
techniques is that they account for correlation using a simple
logistic link function instead of the probit function, which needs
tremendous computational effort and cannot be used for relatively
high numbers of alternatives or with large networks in multinomial
models.
METHODOLOGIES THAT ACCOUNT FOR CORRELATION
Repeated Observations
Statisticians and transportation researchers have developed
several methodological techniques to account for correlation between
repeated observations made by the same traveler in binary and
multinomial route choice models. Louviere and Woodworth (1983) and
Mannering (1987) corrected the standard errors produced in a
repeated responses regression model by multiplying the standard
errors by the square root of the number of repeated observations.
Kitamura and Bunch (1990) used a dynamic ordered-response probit
model of car ownership with error components. Mannering et al.
(1994) used an ordered logit probability model and a duration model
with a heterogeneity correlation term. Morikawa (1994) used logit
models with error components to treat serial correlation. Abdel-Aty
et al. (1997) and Jou (2001) addressed this issue using
individual-specific random error components in binary models with a
normal mixing distribution. The standard deviation of the error
components were found significant in both studies, which clearly
showed the need for some formal statistical corrections to account
for the unobserved heterogeneity. Jou and Mahmassani (1998) used a
general probit model form for the dynamic switching model, allowing
the introduction of state dependence and serial correlation in the
model specification.
At the multinomial level, Mahmassani and Liu (1999) used a
multinomial probit model framework to capture the serial correlation
arising from repeated decisions made by the same respondent. Garrido
and Mahmassani (2000) used a multinomial probit model with spatial
and temporally correlated error structure.
Overlapping Alternatives
The correlation between alternative routes due primarily to
overlapping distances has attracted many researchers to overcome the
limitations of MNL models. The nested logit (NL) model (proposed by
Ben-Akiva 1973) is an extension of the MNL model designed to capture
correlation among alternatives. It is based on the partitioning of
the choice set into different nests. The NL model partitions some or
all nests into subnests, which can in turn be divided into subnests.
This model is valid at every layer of the nesting, and the whole
model is generated recursively. The structure is usually represented
as a tree.
Clearly, the number of potential structures reflecting the
correlation among alternatives can be very large. No technique has
been proposed thus far to identify the most appropriate correlation
structure directly from the data (apart from using a heteroskedastic
extreme value choice model as a search engine for specification of
NL structures). The NL model is designed to capture choice problems
where alternatives within each nest are correlated. No correlation
across nests can be captured by the NL model. When alternatives
cannot be partitioned into well separated nests to reflect their
correlation, the NL model is not appropriate.
Cascetta et al. (1996) introduced the C-logit model as a MNL
model that captures the correlation among alternatives in a
deterministic way. The authors use a term called "commonality
factor," which they add to the deterministic part of the utility
function to capture the degree of similarity between the alternative
and all other alternatives in the choice set. The lack of theory or
guidance on which form of commonality factor should be used is a
drawback of the C-logit method.
McFadden (1978) presented the cross-nested logit (CNL) model as a
direct extension of the NL model, where each alternative may belong
to more than one nest. Similar to the NL model, the choice set is
partitioned into nests. Moreover, for each alternative i and
each nest m, parameters αim,
representing the degree of membership or the inclusive weight of
alternative i in nest m, have to be defined. A CNL
model is not appropriate for high numbers of alternatives.
Vovsha and Bekhor (1998) proposed and used a link-nested logit
model as an application of the CNL model. The largest network they
used contained 1 origin-destination pair, 8 nodes, 11 links, and 5
routes. Papola (2000) estimated a CNL model for intercity route
choice with a limited number of alternative routes. Swait (2001)
proposed the choice set generation logit model, in which choice sets
form the nests of a CNL structure. The author acknowledged the
computational difficulties of estimating this model when the choice
set is large. It was concluded that, for a realistic size network
and a realistic number of links per path, the CNL model and its
applications become quite complex and therefore computationally
onerous.
NL, C-logit, and CNL models are all extensions of the MNL models
that use a logit utility function. An alternative technique is the
multinomial probit (MP) model, which is derived from the assumption
that the error terms of the utility functions are normally
distributed. It uses a probit link function instead of a logit
function. The MP model captures explicitly the correlation among all
alternatives. Therefore, an arbitrary covariance structure can be
specified. Mostly, this covariance structure was proportional to
overlap length. Routes were also assumed to have heteroskedastic
error terms where variance was proportional to route length or
impedance. Yai et al. (1997) introduced a function that represents
an overlapping relation between pairs of alternatives. The
difficulty in implementing the probit model is that no closed form
exists for the Gaussian cumulative distribution function, so
numerical techniques must be used. Estimating an MP model is
difficult even for a relatively low number of alternatives.
Moreover, the number of unknown parameters in the
variance-covariance matrix grows with the square of the number of
alternatives (McFadden 1989).
Ben-Akiva and Bolduc (1996) introduced a multinomial probit model
with a logit kernel (or hybrid logit) model, which combines the
advantages of logit and probit models. It is based on a utility
function that has two error matrices. The elements of the first
matrix are normally distributed and capture correlation between
alternatives. The elements of the second matrix are independent and
identically distributed. These combined models have the same
computational difficulties as pure MP. In general, any application
of hybrid logit or probit to large-scale route choice is
questionable in terms of the computational effort needed for
estimating the parameter coefficients and their marginal effects,
especially for large networks.
Based on the above review, a clear need exists for a methodology
that accounts for the two kinds of correlation in binary and
multinomial route choice models with a computationally easy and
statistically efficient technique, both for small and large
networks. This paper applies BGEE and MGEE with logit functions
(binary and polytomous) to account for correlation between repeated
observations in binary models and correlation between repeated
observations and overlapping routes in multinomial models.
Applications
Route Choice and Switching
Pre-trip and en-route route switching is a direct response to
Advanced Traveler Information Systems (ATIS). Network conditions,
travel time, travel time variability, delays associated with
congestion and incidents, and traveler attributes are significant
determinants of route choice (Spyridakis et al. 1991; Adler et al.
1993; Mannering et al. 1994; Abdel-Aty et al. 1995a, b, 1997). Some
studies proved that providing information induces greater switching
in route choice behavior (Mahmassani 1990; Conquest et al. 1993;
Abdel-Aty et al. 1994b). For example, Conquest et al. (1993)
reported that 75% of commuters change either departure time or route
in response to information. Liu and Mahmassani (1998) concluded that
travelers were more likely to change their route when their current
choice would cause them to arrive late. They also concluded that
drivers exhibited some inertia in route choice, requiring travel
time savings of at least one minute on the alternative route.
Benefits of ATIS
Many studies have examined the potential benefits of providing
pre-trip and en route real-time information to travelers. Much
research focuses on the effects of ATIS on all types of travel
decisions. A number of studies show that ATIS results in reduced
travel time, congestion delays, and incident clearance time
(Wunderlich 1996; Abdel-Aty et al. 1997; Sengupta and Hongola 1998).
Empirical evidence supports the hypothesis that travelers alter
their behavior in response to ATIS (Bonsall and Parry 1991; Zhao et
al. 1996; Mahmassani and Hu 1997). Reiss et al. (1991) reported
travel time savings ranging from 3% to 30% and reduction in incident
and congestion delays of up to 80% for impacted vehicles.
Drivers' Familiarity with the Network and Diversion
Polydoropoulou et al. (1996) and Khattak et al. (1996) concluded
that drivers exhibit some inertia and tend to follow the same route,
especially for home-to-work trips. Polydoropoulou et al. found that
drivers are more likely to divert to another route when they learn
of a delay before a trip. Drivers are less likely to divert during
bad weather, as alternative routes may be equally slow. Prescriptive
information greatly increases travelers' diversion probabilities,
although similar diversion rates are attainable by providing
real-time quantitative or predictive information about travel times
on usual and alternative routes. The authors suggest that drivers
would prefer to receive travel time information and make their own
decisions. Abdel-Aty et al. (1994a) showed that ATIS has great
potential to influence commuters' route choice even when advising a
route different from the usual one.
Studies also indicate that traffic information should be provided
along with alternative route information. Streff and Wallace (1993)
reported differences in information requirements between commuting,
noncommuting trips, and trips in an unfamiliar area. Khattak et al.
(1996) found that travelers who were unfamiliar with alternative
routes or modes were particularly unwilling to divert. This confirms
the work of Kim and Vandebona (2002), which concluded that drivers
who were familiar with an area had a high propensity to change their
preselected routes. Further, accurate quantitative information might
be able to overcome behavioral inertia if commuters are willing to
follow advice from a prescriptive ATIS (Khattak et al. 1996; Lotan
1997). Adler and McNally (1994) found that travelers who were
familiar with the network were less likely to consult information.
Bonsall and Parry (1991) found that user acceptance declined with
decreasing quality of advice in an unfamiliar network, and in a
familiar network, drivers were less likely to accept advice from the
system. However, Allen et al. (1991) found that familiarity does not
affect route choice behavior.
GENERALIZED ESTIMATING EQUATIONS
The generalized estimating equations (GEE) technique analyzes
discrete and correlated data with reasonable statistical efficiency.
Liang and Zeger (1986) introduced GEE for binary models (BGEE) as an
extension of generalized linear models (GLM). Lipsitz et al. (1994)
extended the BGEE methodology to model correlation between repeated
multinomial categorical responses (MGEE).
The GEE methodology models a known function of the marginal
expectation of the dependent variable as a linear function of the
explanatory variables. With GEE, the analyst describes the random
component of the model for each marginal response with a common link
and variance function, similar to what happens with a GLM model.
However, unlike GLM, the GEE technique accounts for the covariance
structure of the repeated measures. This covariance structure across
repeated observations is managed as a nuisance parameter. The GEE
methodology provides consistent estimators of the regression
coefficient and their variances under weak assumptions about the
actual correlation among a subject's choices.
In the following section, we provide a brief explanation of the
BGEE models. The MGEE methodology is included in the appendix at the
end of this paper.
Binary Generalized Estimating Equations
Suppose a number of ni choices are made
by subject i, where the total number of subjects is K,
and yij denotes the jth response
from subject i. There are  total choices (measurements). Let the
vector total choices (measurements). Let the
vector
of choices made by the ith subject be
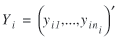
and let Vi be an estimate of the
covariance matrix of yi. Let the vector of
explanatory variables for the jth choice on the ith
subject be Xij1 =
(xij1,...,xijp)´.
The GEEs for estimating the (1 × p) vector of
regression parameters β is an extension of the independence
estimating equation to correlated data and is given by
 (1) (1)
where p is the number of regression parameters,
Since g(uij) =
xij, β, the p ×
ni matrix of partial derivatives of the
mean with respect to the regression parameters for the ith
subject is given by
![lowercase delta lowercase mu prime subscript i divided by lowercase delta lowercase beta = [column 1 row 1 lowercase x subscript {lowercase i 1 1} divided by lowercase g prime (lowercase mu subscript {lowercase i 1) column 1 row 2 ... column 1 row 3 lowercase x subscript {lowercase i 1 lowercase p} divided by lowercase g prime (lowercase mu subscript {lowercase i 1} column 2 row 1 ... column 2 row 2 column 2 row 3 ... column 3 row 1 lowercase x subscript {lowercase i lowercase n subscript {lowercase i} 1 divided by lowercase g prime (lowercase mu subscript {lowercase i lowercase n subscript {lowercase i}}) column 3 row 2 ... column 3 row 3 lowercase x subscript {lowercase i lowercase n subscript {lowercase i} lowercase p} divided by lowercase g prime (lowercase mu subscript {lowercase i lowercase n subscript {lowercase i}})]](https://webarchive.library.unt.edu/eot2008/20090115200031im_/https://www.bts.gov/publications/journal_of_transportation_and_statistics/volume_08_number_01/images/Abdel-Aty-11.gif) (2) (2)
where
g is the logit link function g(μ) = log(p(1
– p)), which is the inverse of the cumulative logistic
distribution function, which is:
 (3) (3)
Working Correlation Matrix in BGEE
Let Ri(α) be an
ni × ni "working"
correlation matrix that is fully specified by the vector of
parameters α (the correlation between any two choices). The
(j, k) element of
Ri(α) is the known, hypothesized, or
estimated correlation between yij and
yik. The covariance matrix of Yi
is modeled as
 (4) (4)
where
Ai is an ni ×
ni diagonal matrix with
υ(μij) as the jth diagonal
element.
φ is a dispersion parameter and is estimated by
 (5) (5)
R is the working correlation matrix. It is the same for
all subjects, is not usually known, and must be estimated. The
estimation occurs during the iterative fitting process using the
current value of the parameter matrix β to compute
appropriate functions of the Pearson residual
 . .
If Ri(α) is the true correlation
matrix of Yi, then Vi is the
true covariance matrix of Yi. If the working
correlation is specified as R = I, which is the
identity matrix, the GEE reduces to the independence estimating
equation. The exchangeable correlation structure introduced by Liang
and Zeger (1986) assumes constant correlation between any two
choices within a subject/cluster. This exchangeable correlation
structure can be used in the BGEE where the correlation matrix of
each subject/cluster is defined as:

![e.g. right arrow uppercase r subscript {3 x 3} = [column 1 row 1 1 column 1 row 2 lowercase alpha column 1 row 3 lowercase alpha column 2 row 1 lowercase alpha column 2 row 2 1 column 2 row 3 lowercase alpha column 3 row 1 lowercase alpha column 3 row 2 lowercase alpha column 3 row 3 1]](https://webarchive.library.unt.edu/eot2008/20090115200031im_/https://www.bts.gov/publications/journal_of_transportation_and_statistics/volume_08_number_01/images/Abdel-Aty-27.gif) (6) (6)
where
 and and
 (7) (7)
DATA COLLECTION AND EXPERIMENT DESCRIPTION
We used the travel simulator, Orlando Transportation Experimental
Simulation Program (OTESP), to collect dynamic pre-trip and en-route
route choice data. OTESP is an interactive windows-based computer
simulation tool. It simulates a commuter home-to-work morning trip.
OTESP provides five scenarios (levels) of traffic information to the
subjects. In scenario #1, subjects receive no traffic information.
Pre-trip information without and with advice are presented in
scenarios #2 and #3, respectively. En route information, keeping the
pre-trip information, without and with advice is presented in
scenarios #4 and #5, respectively. The subject is required to choose
his/her link-by-link route from a specified origin to a specified
destination. The subject has the ability to move the vehicle on
different segments of the network using the computer's mouse.
Driving and riding one of two available bus routes are the travel
modes used in OTESP. However, this study focuses only on the drive
option.
In this study, we used a real network with historical congestion
levels and weather conditions (figure
1). Intersections, recurring congestion, nonrecurring congestion
(incidents), toll plazas, and weather condition delays are
considered. The Moore's shortest path algorithm (Pallottino and
Grazia 1998) was employed in the OTESP code to determine the
travel-time-based shortest path, which is introduced as advice to
the subjects in some scenarios. The simulation starts and ends with
a short survey to collect the subjects' sociodemographic
characteristics, preferences, perceptions, and feedback. A
four-table database was created to capture all the
information/advice provided and the traveler decisions. The program
presents 10 simulated days (2 days for each scenario) after
familiarizing the subjects with the system by introducing a training
day for each scenario. Figure 1 shows a spot view of OTESP in its
third scenario as an example.
Network
Figure 1 presents a portion of the city of Orlando network
captured from a geographic information system database. The network
has a unique origin-destination pair, where the assumed origin is
the subject's home and the assumed destination is the subject's work
place. The network consists of 25 nodes and 40 links. This network
portion was carefully chosen from the entirety of the Orlando
network. It comprises different types of highways, including
six-lane principle arterials, four-lane principle arterials,
six-lane minor arterials, two-lane minor arterials, and local
collectors. The network also includes two expressways.
Subjects
Subjects were recruited based on an experiment to guarantee the
inclusion of groups of drivers that represent different incomes (two
levels), ages (three levels), gender, familiarity with the network
(two levels), and education (two levels). Because the subjects drove
for their morning home-to-work trips, they were instructed that
their main task was to minimize the overall trip travel time by
deciding when and when not to follow the information and/or advice
provided. Subjects were asked not to go through the simulation
unless they had at least 30 minutes to devote to it (the average
simulation took 23.77 minutes) and felt they could concentrate on
it. Moreover, during the simulation, the subjects' response times
were measured without notifying them, to ensure that they were
paying attention. A total of 65 subjects participated in the
simulation for 10 trial days each. Twenty-two subjects were under
the age of 25 while 24 subjects were between 25 and 40 years of age,
and 19 subjects were over 40 years old. Of the subjects, 24 were
female and 41 were male. Two of the 65 subjects were excluded from
this study, because their response times were outliers in the normal
distribution (Z = 3.21 and 3.78, Zcr =
2.57).
BGEE APPLICATION
Subjects viewed the level of congestion of every link in
quantitative (travel time) and qualitative (green, yellow, and red
links for free flow, moderate, and congested links, respectively)
forms. The simulator also provided the shortest path from the
subject's current position to the destination as advice. The
information/advice level the subject received depended on the
scenario, as mentioned above. At each node, the subject had to
decide and choose between the two upcoming links. We considered this
choice positive if the subject picked the link that had a lower
level of congestion than the others (the delay on a link was equal
to the difference between actual travel time at a specific
movement—when a decision is made—and free flow travel time). A
choice was considered negative if the subject picked the link with a
higher level of congestion. We focused on the delay on a link when a
particular movement occurred instead of travel time, because the
links are different in length and speed limit.
Sixty-three subjects completed 10 trial days each, for a total of
539 trial days in the drive mode (the remainder of the trial days
were in the transit mode). During the trial days, 4,753 movements
(decisions) were made on the 40 network links. Out of the 4,753
movements, 1,667 were excluded from the analysis, because the driver
had no choice but to proceed onto a unique coming link. The
remaining 3,086 link choices make up the data used for the BGEE
model with binomial logistic function. The model was correlated
because each subject had multiple choices in the data structure. The
response variable was binary with the value of one for positive
choices and zero for negative choices. The explanatory variables
follow:
- Information familiarity: one if the subject, in real
life, uses pre-trip and/or en route information usually or
everyday, zero otherwise.
- Information provision: one for trial days where en
route information was provided, zero otherwise.
- Same color: one if the two coming links had the same
color (qualitative congestion level), zero otherwise. This
variable tests the effect of qualitative vs. quantitative
information.
- System learning: one for the second five trial days of
the simulations, zero for the first five. This is based on the
assumption that the subject in the last five simulation runs is
more familiar with the information system and can use and benefit
from it more effectively.
- Heavy rain: one for heavy rain conditions; zero for
light rain or clear sky conditions. Weather conditions were
provided as part of the information.
- Number of movements from the origin: representing the
closeness to the destination.
Table
1 presents the results of the BGEE model for the independent
case (no correlation is considered) and for the proposed
exchangeable correlation. The differences in the results are due to
the effect of correlation. By comparing the overall F
statistic values for the two models, the exchangeable model was
favored over the independent model. This indicates that the model
has correlation that should be accounted for.
The modeling results showed that, in general, the provision of en
route information increases the likelihood of making a positive link
choice. This means that the en route short-term information has a
good chance of being used. When the two coming links had the same
qualitative level of congestion, drivers were less likely to make a
positive choice. Thus, the qualitative information is more likely to
be used than the quantitative information. Therefore, it is not
enough to provide the driver with the expected travel time or that
there is congestion, but providing the driver with information on
the level of congestion is also necessary.
The following effects/interactions increase the likelihood of
following the en route short-term information:
- Being familiar with traffic information;
- Learning and being familiar with the system that provides the
information;
- Heavy rain conditions;
- Being away from the origin, that is, close to the destination
(presented by the number of movements since the origin);
- Providing qualitative information in heavy rain conditions;
and
- Being away from the origin and being familiar with the device
that provides the information.
MGEE APPLICATION
The long-term route choices of the subjects in the experiment
were used as the database for estimating this model. The 539 routes
that were chosen during the 539 trial days (each subject chooses one
route each trial day) were identified and categorized by the
sequence of links that were traversed on a given trial day. The
network used consists of four west-east expressway/arterials that
connect the origin to the destination: named here MR1, MR2, MR3, and
MR4.
MR1 represents the expressway alternative on the network. MR2 is
a six-lane arterial while MR3 is mainly a four-lane arterial with a
relatively high number of traffic lights. MR4 is primarily a rural,
two-lane, two-way arterial with a speed limit approximately equal to
that of MR2 and MR3. MR1 has the highest speed limit among the four
alternatives with few traffic lights, because it consists mainly of
expressway links. The network has also five local collectors that
allow the subject to divert from one main route to another.
In order to come up with a reasonable number of alternatives, in
the analysis phase, the route choices made during the trial days
were aggregated into the above four main routes. We considered that
each chosen route belonged to a main route if most of the chosen
route's links belong to this main route. That is, a chosen route was
assigned to a certain main arterial if, and only if, the chosen
route overlaps with this main arterial for a longer distance than it
does with any of the other three main arterials. As a result, the
four main routes MR1, 2, 3, and 4 were chosen 374, 99, 37, and 29
times, respectively.
The proposed MGEE method with a generalized polytomous logit
function was employed to model correlated route choices. The
categorical dependent variable has four alternatives, MR1, MR2, MR3,
and MR4. These four alternatives form the fixed choice set available
for all subjects at all trial days. The reference alternative for
which all attributes in the analysis are set equal to zero is MR4.
This route was chosen because it was picked with lesser frequency
over the other three main routes. The dependent variable takes on a
value of one to four. The independent variables include:
- Age: one if the subject's age is over 30, zero
otherwise;
- Income: one if household income is greater than
$65,000, zero otherwise;
- Education: one if the subject has a graduate-level
degree or higher, zero otherwise;
- Shortest 1: one if MR1 was the shortest path, zero
otherwise;
- Shortest 2: one if MR2 was the shortest path, zero
otherwise;
- Shortest 3: one if MR3 was the shortest path, zero
otherwise;
- Advised 2: one if MR2 was the shortest path and the
trial day was under scenario #3 or #5 (i.e., MR2 was the suggested
route), zero otherwise;
- Advised 3: one if MR3 was the shortest path and the
trial day was under scenario #3 or #5 (i.e., MR3 was the suggested
route), zero otherwise;
- Travel time 1: travel time on MR1;
- Travel time 2: travel time on MR2;
- Travel time 3: travel time on MR3;
- Travel time 4: travel time on MR4.
Tables 2 and 3 show the modeling results using the MGEE model for
the independent case (no correlation is considered) and for the
proposed exchangeable correlation, respectively. The differences in
the results are due to the effect of correlation. By comparing the
overall F statistic values for the two models, the
exchangeable model was favored over the independent model (83,417.09
vs. 11,464.98). Also, as expected, the independent MGEE model
underestimated the standard errors of the modeling effects that lead
to inflated t statistic values (table
2).
In table
3, the t statistics were lower when compared with the
corresponding values in table 2 (for most of the effects),
indicating that the proposed methodology has also adjusted this
error. This means that the proposed methodology overcomes the
disadvantage of underestimating the standard errors for models that
do not account for correlation. A number of studies reported this
disadvantage (Louviere et al. 1983; Mannering 1987; Gopinath 1995;
Abdel-Aty et al. 1997; and Stokes et al. 2000). The model produced
three logistic equations for the four alternatives (MR1 vs. MR4; MR2
vs. MR4, MR3 vs. MR4). These equations are:
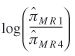 = -65.12 + 3.42Age +
2.36Income = -65.12 + 3.42Age +
2.36Income
+
5.00Education +
22.15S1
+
11.65S2 + 13.23S3 +
29.60A1
-
4.70A2 - 4.87A3 -
6.00TT1
-
2.35TT2 - 0.67TT3 + 9.56TT4
 = -35.39 +2.41Age +
1.01Income = -35.39 +2.41Age +
1.01Income
+
1.99Education
+21.62S1
+
12.17S2 - 7.01S3 +
5.56A1
+
11.34A2 - 25.95A3 -
4.28TT1
-
2.18TT2 - 0.36TT3 + 7.36TT4
 = -3.63 + 9.38Age +
2.49Income = -3.63 + 9.38Age +
2.49Income
+
12.37Education -
10.49S1
-
48.61S2 + 22.67S3 +
3.69A1
-
44.56A2 + 1.41A3 -
0.79TT1
-
0.10TT2 - 1.00TT3 + 1.89TT4
where the symbols Sx, Ax, and TTx refer to
the effects "Shortest x," "Advised x," and "Travel
time x," respectively, where x is the main route
number. Using the above equations, the probability of choosing an
alternative given a set of values for the independent variables is
simple compared with using any probit link function (probit models).
Moreover, computing a certain marginal effect of any variable on
choosing an alternative is straightforward and simple regardless of
the number of alternatives used in the model, which is not the case
for the corresponding multinomial probit models.
In the above equations, exponentiating the estimated regression
coefficient yields the odds of choosing the corresponding
alternative vs. choosing the base alternative MR4 for each one-unit
increase in the corresponding explanatory variable. For example, the
ratio of odds for a one-unit change in the travel time on MR2 is
equal to e–2.18 = 0.11. This shows the ease of
this model compared with the corresponding probit models.
Tables 2 and 3 also show the parameter coefficients for each
equation with the corresponding t statistic of each effect.
Furthermore, tables 2 and 3 present the F statistic for each
effect in the overall MGEE model. These values indicate the
individual significance of every effect in the overall model and
determine if changing the value of this effect statistically changes
the probability of choosing a certain alternative. A certain effect
may appear significant in one equation but be insignificant in
another. All 13 effects included were found significant.
The parameter coefficients in table 3 show that older drivers
(>30), those with larger household incomes, and those with a high
level of education are, in general, more likely to choose MR1, MR2,
or MR3 than MR4; that is, they are more likely to choose the
expressways and/or the multilane arterials. Recall, MR4 is a
two-lane, two-way rural arterial. However, the increase in this
likelihood in some cases is not statistically significant. For
example, these three socioeconomic factors above do not affect the
probability of choosing MR2 vs. MR4 (t statistics = 1.07,
0.45, 0.74 < 1.96).
"Shortest 1," "Shortest 2," and "Shortest 3" measure the effect
of providing information without advice to the subjects. The
significance of "Shortest 1" in the first equation, with a positive
coefficient parameter (22.15), shows that the probability of
choosing the first alternative, MR1, increases if this route is the
travel-time-based shortest route on the network, even with providing
advice-free information. This means that the subjects were able to
use and benefit from the qualitative and quantitative information
provided to them. Moreover, they might be able to identify and then
take the shortest route themselves using the travel times given to
them by the information system. The same interpretation applies to
the coefficient parameters of the effects "Shortest 2" and "Shortest
3" in equations 2 and 3, respectively. By comparing these three
coefficients (22.15, 12.17, 22.67), differences can be seen. This
indicates that the marginal effects of these variables are not the
same. However, they measure the same independent variable for
different alternatives. Thus, it can be concluded that providing
traffic information to drivers increases the likelihood that they
will choose the shortest path (identified by them or given to them
by an information system), but the odds differ between the shortest
path and another, depending on the characteristics of each
route.
To measure the effect of advising drivers to take a particular
route, in addition to providing traffic information on all links of
the network, the three effects, "Advised 1," "Advised 2," and
"Advised 3" were employed. Advising MR1 or MR2 to the subjects
increased the likelihood of their being their chosen (coefficients
of 29.60 and 11.34, respectively). However, advising MR3 as the
shortest path for a certain trial day does not affect its
probability of being chosen (t statistic = 0.24). This result
was not surprising, because MR3 is well known for its regular
congestion due to its high accessibility and many traffic lights
(most of the subjects were familiar with the network).
Similar to the effect of information without advice, the
coefficient parameters "Advised 1" in equation 1, "Advised 2" in
equation 2, and "Advised 3" in equation 3 (29.60, 11.34, 1.41,
respectively) show that it is unclear that advising drivers to take
a certain route increases the likelihood they will chose to do so.
The characteristics of the route itself seem to be a factor in the
decision. In this analysis, advising drivers to use an expressway or
six-lane arterial increased the likelihood of it being chosen (MR1
and MR2). When drivers were advised to use a four-lane arterial with
high density and traffic lights it did not affect the likelihood of
that route being chosen. From these data, we can conclude that the
characteristics of a certain route affect whether it is chosen even
if the information advises drivers to use it.
The effect of travel time was represented in our model by the
variables TT1, TT2, TT3, and TT4. The first three variables have
negative coefficients in the three equations, with significant
effects for TT1 in equation 1, TT2 in equation 2, and TT3 in
equation 3. This clearly shows that the probability of choosing a
certain route decreases as travel time increases. The effect TT4,
the travel time of the base route MR4, showed up as a positive
significant variable in the three equations. Therefore, the
probability of choosing the other route (not choosing this base
route) increases as travel time rises for the base alternative.
CONCLUSIONS
The proposed BGEE and MGEE techniques add new and useful
methodology to the family of models that account for correlation in
discrete choice models, especially for route choice applications.
The literature review illustrated that a methodology was needed to
account for correlation between repeated choices and/or between
overlapping alternatives with simple computational effort and that
can be applied to large networks. The proposed model proved to
account for both types of correlation with simple computational
effort and reasonable statistical efficiency for small and large
networks. This makes BGEE and MGEE superior to the existing
methodologies.
As a BGEE application, this paper presents a model of short-term
route choice in compliance with ATIS. The paper also presents a
multinomial route choice model (as an MGEE application). Both
applications were developed with and without accounting for
correlation. In both applications, the effect of correlation was
tested statistically and found significant, which shows the
importance of accounting for correlation in route choice models that
may lead to different travel forecasts and policy decisions. This
also shows the importance of our proposed methodology for large
networks where the efficiency of the existing methodologies is
questionable, as discussed in the literature review.
In this paper, we interpreted the modeling output of the BGEE and
MGEE applications. The short-term route choice (BGEE) modeling
results show that the provision of en route information increases
the likelihood of making a positive link choice. The qualitative
short-term information is more likely to be used than the
quantitative information. Other effects were found to increase the
usage of en route short-term traffic information: being familiar
with the system that provides the information, heavy rain
conditions, and proximity to the destination.
The multinomial route choice (MGEE) modeling results show that
the subjects were able to use and benefit from the qualitative and
quantitative information provided to them. Moreover, they might be
able to identify the shortest route themselves using the travel
times given to them. Finally, the odds of choosing a certain
shortest route (advised or recognized by drivers using the
advice-free traffic information provided) varied from one route to
another and depended on the characteristics of the route itself. For
example, the analysis in this paper showed that advising the use of
the expressway or the six-lane arterial increase the likelihood of
the route being chosen (MR1 and MR2). While advising the use of a
four-lane arterial with a large number of traffic lights does not
affect its likelihood of being chosen.
ACKNOWLEDGMENT
The author thanks Dr. M. Fathy Abdalla for his significant
contribution to this paper. The results in this paper are based on a
research project funded by the Center for Advanced Transportation
Simulation Systems (CATSS) at the University of Central Florida
(UCF) and the Florida Department of Transportation, and were
included in Dr. Abdalla's Ph.D. dissertation at UCF, for which the
author was the academic advisor (Abdalla 2003).
REFERENCES
Abdalla, M. 2003. Modeling Multiple Route Choice
Paradigms Under Different Types and Levels of ATIS Using Correlated
Data, Ph.D. dissertation. Department of Civil and Environmental
Engineering, University of Central Florida.
Abdel-Aty, M., K. Vaughn, P. Jovanis, R. Kitamura, and
F. Mannering. 1994a. Impact of Traffic Information on Commuters'
Behavior: Empirical Results from Southern California and Their
Implications for ATIS. Proceedings of the 1994 Annual Meeting of
IVHS America, pp. 823–830.
Abdel-Aty, M., R. Kitamura, P. Jovanis, and K. Vaughn.
1994b. Investigation of Criteria Influencing Route Choice: Initial
Analysis Using Revealed and Stated Preference Data, Report No.
UCD-ITS-RR-94-12. University of California, Davis.
Abdel-Aty, M., R. Kitamura, and P. Jovanis. 1995a.
Investigating the Effect of Travel Time Variability on Route Choice
Using Repeated Measurement Stated Preference Data. Transportation
Research Record 1493:39–45.
Abdel-Aty, M., K. Vaughn, R. Kitamura, P. Jovanis, and
F. Mannering. 1995b. Models of Commuters' Information Use and Route
Choice: Initial Results Based on Southern California Commuter Route
Choice Survey. Transportation Research Record 1453:46–55.
Abdel-Aty, M., R. Kitamura, and P. Jovanis. 1997.
Using Stated Preference Data for Studying the Effect of Advanced
Traffic Information on Drivers' Route Choice. Transportation
Research C 5(1):39–50.
Adler, J., W. Recker, and M. McNally. 1993. A Conflict
Model and Interactive Simulator (FASTCARS) for Predicting En-Route
Driver Behavior in Response to Real-Time Traffic Condition
Information. Transportation 20(2):83–106.
Adler, J. and M. McNally. 1994. In-Laboratory
Experiments to Investigate Driver Behavior Under Advanced Traveler
Information Systems. Transportation Research C 2:149–164.
Allen, R., D. Ziedman, T. Rosenthal, A. Stein, J.
Torres, and A. Halati. 1991. Laboratory Assessment of Driver Route
Diversion in Response to In-Vehicle Navigation and Motorist
Information Systems. Transportation Research Record
1306:82–91.
Ben-Akiva, M. 1973. Structure of Passenger Travel
Demand Models, Ph.D. thesis. Massachusetts Institute of
Technology.
Ben-Akiva, M. and D. Bolduc. 1996. Multinomial Probit
with a Logit Kernel and a General Parametric Specification of the
Covariance Structure, presented at the 3rd International Choice
Symposium, Columbia University, New York, NY.
Bonsall, P. and T. Parry. 1991. Using an Interactive
Route-Choice Simulator to Investigate Driver's Compliance with Route
Guidance Advice. Transportation Research Record
1306:59–68.
Cascetta, E., A. Nuzzolo, F. Russo, and A. Vitetta.
1996. A Modified Logit Route Choice Model Overcoming Path
Overlapping Problems: Specification and Some Calibration Results for
Interurban Networks. Proceedings from the 13th International
Symposium on Transportation and Traffic Theory, Lyon, France.
Conquest, L., J. Spyridakis, and M. Haselkorn. 1993.
The Effect of Motorist Information on Commuter Behavior:
Classification of Drivers into Commuter Groups. Transportation
Research C 1:183–201.
Delvert, K. 1997. Heterogeneous Agents Facing Route
Choice: Experienced versus Inexperienced Tripmakers, presented at
IATBR `97, Austin, TX.
Garrido, R. and H. Mahmassani. 2000. Forecasting
Freight Transportation Demand with the Space-Time Multinomial Probit
Model. Transportation Research B 34(5):403–418.
Gopinath, D. 1995. Modeling Heterogeneity in Discrete
Choice Processes: Application to Travel Demand, Ph.D. thesis.
Massachusetts Institute of Technology.
Jou, R. 2001. Modeling the Impact of Pre-Trip
Information on Commuter Departure Time and Route Choice.
Transportation Research B 35:887–902.
Jou, R. and H. Mahmassani. 1998. Day-to-Day Dynamics
of Urban Commuter Departure Time and Route Switching Decisions:
Joint Model Estimation. Travel Behavior Research. New York,
NY: Elsevier.
Khattak, A., A. Polydoropoulou, and M. Ben-Akiva.
1996. Modeling Revealed and Stated Pretrip Travel Response to
Advanced Traveler Information Systems. Transportation Research
Record 1537:46
Kim, K. and U. Vandebona. 2002. Understanding Route
Change Behavior: A Commuter Survey in South Korea, presented at the
81st Annual Meetings of the Transportation Research Board,
Washington, DC.
Kitamura, R. and D. Bunch. 1990. Heterogeneity and
State Dependence in Household Car Ownership: A Panel Analysis Using
Ordered-Response Probit Models with Error Components.
Transportation and Traffic Theory. Oxford, England:
Elsevier.
Liang, K. and S. Zeger. 1986. Longitudinal Data
Analysis Using Generalized Linear Models. Biometrika
73:13–22.
Lipsitz, S., K. Kim, and L. Zhao. 1994. Analysis of
Repeated Categorical Data Using Generalized Estimating Equations.
Statistics in Medicine 13:1149–1163.
Liu, Y. and H. Mahmassani. 1998. Dynamic Aspects of
Departure Time and Route Decision Behavior Under Advanced Traveler
Information Systems (ATIS): Modeling Framework and Experimental
Results. Transportation Research Record 1645:111–119.
Lotan, T. 1997. Effects of Familiarity on Route Choice
Behavior in the Presence of Information. Transportation Research
C 5:225–243.
Louviere, J. and G. Woodworth. 1983. Design and
Analysis of Simulated Consumer Choice or Allocation Experiments: An
Approach Based on Aggregate Data. Journal of Marketing Research
20:350–367.
Mahmassani, H. 1990. Dynamic Models of Commuter
Behaviour: Experimental Investigation and Application to the
Analysis of Planned Traffic Disruptions. Transportation Research
A 24(6):465–484.
Mahmassani, H. and T. Hu. 1997. Day-to-Day Evolution
of Network Flows Under Real-Time Information and Reactive Signal
Control. Transportation Research C 5(1):51–69.
Mahmassani, H. and Y. Liu. 1999. Dynamics of Commuting
Decision Behaviour Under Advanced Traveler Information Systems.
Transportation Research C 7(2–3):91–107.
Mannering, F. 1987. Analysis of the Impact of Interest
Rates on Automobile Demand. Transportation Research Record
1116:10–14.
Mannering, F., S. Kim, W. Barfield, and L. Ng. 1994.
Statistical Analysis of Commuters' Route, Mode, and Departure Time
Flexibility. Transportation Research C 2(1):35–47.
McFadden, D. 1978. Modeling the Choice of Residential
Location. Transportation Research Record 672:72–77.
____. 1989. A Method of Simulated Moments for
Estimation of Discrete Response Models Without Numerical
Integration. Econometrica 57(5):995–1026.
Morikawa, T. 1994. Correcting State Dependence and
Serial Correlation in the RP/SP Combined Estimation Method.
Transportation 21(2):153–165.
Pallottino, S. and M. Grazia. 1998. Shortest Path
Algorithms in Transportation Models: Classical and Innovative
Aspects. Edited by P. Marcotte and S. Nguyen. Equilibrium and
Advanced Transportation Modeling. Boston, MA: Kluwer Academic
Publishers.
Papola, A. 2000. Some Development of the Cross-Nested
Logit Model. Proceedings of the 9th IATBR Conference, July
2000.
Polydoropoulou, A., M. Ben-Akiva, A. Khattak, and G.
Lauprete. 1996. Modeling Revealed and Stated En-Route Travel
Response to Advanced Traveler Information Systems. Transportation
Research Record 1537:38.
Reiss, R., N. Gartner, and S. Cohen. 1991. Dynamic
Control and Traffic Performance in a Freeway Corridor: A Simulation
Study. Transportation Research A 25(5):267–276.
Sengupta, R. and B. Hongola. 1998. Estimating ATIS
Benefits for the Smart Corridor Partners for Advanced Transit and
Highways, UCB-ITS-PRR-98-30. Institute of Transportation Studies,
University of California, Berkeley.
Spyridakis, J., W. Barfield, L. Conquest, M.
Haselkorn, and C. Isakson. 1991. Surveying Commuter Behavior:
Designing Motorist Information Systems. Transportation Research
A 25:17–30.
Stokes, M., C. Davis, and G. Koch. 2000.
Categorical Data Analysis Using the SAS System, 2nd ed. Cary,
NC: SAS Institute.
Streff, F. and R. Wallace. 1993. Analysis of Drivers'
Information Preferences and Use in Automobile Travel: Implications
for Advanced Traveler Information Systems. Proceedings of the
Vehicle Navigation and Information Systems Conference, Ottawa,
Ontario, Canada.
Swait, J. 2001. Choice Set Generation within the
Generalized Extreme Value Family of Discrete Choice Models.
Transportation Research B 35:643–666.
Vovsha, P. and S. Bekhor. 1998. The Link-Nested Logit
Model of Route Choice: Overcoming the Route Overlapping Problem.
Transportation Research Record 1645.
Wunderlich, K. 1996. An Assessment of Pre-Trip and En
Route ATIS Benefits in a Simulated Regional Urban Network.
Proceedings of the Third World Congress on Intelligent Transport
Systems, Orlando, FL.
Yai, T., S. Iwakura, and S. Morichi. 1997. Multinomial
Probit with Structured Covariance for Route Choice Behavior.
Transportation Research B 31(3):195–207.
Zeger, S., K. Liang, and P. Albert. 1988. Models for
Longitudinal Data: A Generalized Estimating Equation Approach.
Biometrics 44:1049–1060.
Zhao, S., N. Harata, and K. Ohta. 1996. Assessing
Driver Benefits from Information Provision: A Logit Model
Incorporating Perception Band of Information. Proceedings of the
24th Annual Passenger Transport Research Conference, London,
England.
APPENDIX
Multinomial Generalized Estimating Equations (MGEE)
Suppose a number of t repeated choices are made by subject
i (i = 1,...,N), the total number of repeated
choices for subject i is Ti, and
K is the total number of alternatives available for all
subjects at all observations. Two-level indicator variables can be
formed as yikt, where
yikt = 1 if subject i had the choice
k at time t, while yikt =
0, otherwise. A (k – 1) vector yit =
[yi1t,...,yi,
k–1, t] can be formed to show
the choice of subject i at time t. Each subject has
Ti covariate vectors
xit, where an xit
vector contains all the relevant covariates including the intercept,
between- and within-subject covariates. Therefore, each subject has
a matrix of covariates
![uppercase x subscript {lowercase i} = [lowercase x subscript {lowercase i 1}, ..., lowercase x subscript {lowercase i uppercase t subscript {lowercase i}}] prime](https://webarchive.library.unt.edu/eot2008/20090115200031im_/https://www.bts.gov/publications/journal_of_transportation_and_statistics/volume_08_number_01/images/Abdel-Aty-47.gif)
of dimension Ti × p, where
p is the total number of covariates excluding the
intercept.
The distribution of yit is multinomial
with the probability function
 (8) (8)
where π i k t = E (y i k
t | x i t, β) = pr {y
i k t = 1 | x i t, β } is
the probability that subject i had choice k at time
t, and β is a p × 1 vector of parameters. When
yit is binary,
πikt is usually modeled with a logistic or
probit link function (Zeger et al. 1988). When k > 2 with
non-ordered response, the generalized polytomous logit link is
appropriate (Lipsitz et al. 1994).
The matrix of coefficient parameters β is associated with
the [(K – 1) × 1] marginal probability vector
E (Y i t | X
i) = π i t (α) = [π
i t 1, …, π i, (K - 1),
t] ′ (9)
These marginal probability vectors can be grouped together to
form the [Ti(K – 1) × 1] vector
![uppercase e (uppercase y subscript {lowercase i} | uppercase x subscript {lowercase i}) = lowercase pi subscript {lowercase i} (lowercase beta) = [lowercase pi prime subscript {lowercase i 1}, ..., lowercase pi prime subscript {lowercase i uppercase t subscript {lowercase i}}] prime](https://webarchive.library.unt.edu/eot2008/20090115200031im_/https://www.bts.gov/publications/journal_of_transportation_and_statistics/volume_08_number_01/images/Abdel-Aty-58.gif)
where
![uppercase y subscript {lowercase i} = [uppercase prime subscript {lowercase i 1}, ..., uppercase y prime subscript {lowercase i uppercase t subscript {lowercase i}}] prime](https://webarchive.library.unt.edu/eot2008/20090115200031im_/https://www.bts.gov/publications/journal_of_transportation_and_statistics/volume_08_number_01/images/Abdel-Aty-59.gif) (10) (10)
The GEEs of the following form can be used to estimate β
(Liang and Zeger 1986; Lipsitz et al. 1994)
![lowercase u (lowercase beta caret) = summation from lowercase i = 1 to uppercase n of (lowercase d [lowercase pi subscript {lowercase i} (lowercase beta)] prime) divided by (lowercase d lowercase beta) uppercase v caret superscript {negative 1} subscript {lowercase i} [uppercase y subscript {lowercase i} minus lowercase pi caret subscript {lowercase i}] = 0](https://webarchive.library.unt.edu/eot2008/20090115200031im_/https://www.bts.gov/publications/journal_of_transportation_and_statistics/volume_08_number_01/images/Abdel-Aty-61.gif) (11) (11)
where Vi is the covariance matrix of
Yi. This covariance matrix,
Vi, is a function of β and other
nuisance parameters α, which is a function of the correlation
between repeated choices made by the same subject i. Also,
Vi depends on the correlation between
overlapped (or correlated) alternative routes. This covariance
matrix, Vi, has
[Ti × Ti] blocks.
Each block has [(K – 1) × (K – 1)] elements.
Estimating the Covariance Matrix
To get a general form of Vi, the correlation
matrix of the elements of Yi must be
developed or estimated first. Therefore, the pairwise correlation
between the (K – 1) elements of Yis and
Yit, which accounts for correlation between
observations s and t of subject i , must be
determined. A typical element of the correlation matrix of the
elements of Yi is, for any pair of
responsive levels j and k and pair of times s
and t,
Corr (Y i j s, Y i
k t) = E [e i j s, e i k
t],
where ![lowercase e subscript {lowercase i lowercase k lowercase t} = (uppercase y subscript {lowercase i lowercase k lowercase t} minus lowercase pi subscript {lowercase i lowercase k lowercase t}) divided by [lowercase pi subscript {lowercase i lowercase k lowercase t (1 minus lowercase pi subscript {lowercase i lowercase k lowercase t)] superscript {1 divided by 2}](https://webarchive.library.unt.edu/eot2008/20090115200031im_/https://www.bts.gov/publications/journal_of_transportation_and_statistics/volume_08_number_01/images/Abdel-Aty-67.gif) (12) (12)
The element eikt is the residual for
Yikt. This residual
eikt is a typical element of the residual
vector
![lowercase e subscript {lowercase i lowercase t} = uppercase a superscript {negative 1 over 2} subscript {lowercase i lowercase t} [uppercase y subscript {lowercase i lowercase t} minus lowercase pi subscript {lowercase i lowercase t}]](https://webarchive.library.unt.edu/eot2008/20090115200031im_/https://www.bts.gov/publications/journal_of_transportation_and_statistics/volume_08_number_01/images/Abdel-Aty-68.gif)
where Ait is a function of β and
is equal to:
![uppercase a subscript {lowercase i lowercase t} = Diag [lowercase pi subscript {lowercase i 1 lowercase t} (1 minus lowercase pi subscript {lowercase i 1 lowercase t}), ..., lowercase pi subscript {lowercase i, uppercase k minus 1, lowercase t} (1 minus lowercase pi subscript {lowercase i, uppercase k minus 1, lowercase t})]](https://webarchive.library.unt.edu/eot2008/20090115200031im_/https://www.bts.gov/publications/journal_of_transportation_and_statistics/volume_08_number_01/images/Abdel-Aty-70.gif) (13) (13)
![uppercase a superscript {negative 1 over 2} subscript {lowercase i lowercase t} = Diag [(lowercase pi subscript {lowercase i 1 lowercase t} (1 minus lowercase pi subscript {lowercase i 1 lowercase t})) superscript {1 divided by 2}, ..., (lowercase pi subscript {lowercase i, uppercase k minus 1, lowercase t} (1 minus lowercase pi subscript {lowercase i, uppercase k minus 1, lowercase t})) superscript {1 divided by 2}]](https://webarchive.library.unt.edu/eot2008/20090115200031im_/https://www.bts.gov/publications/journal_of_transportation_and_statistics/volume_08_number_01/images/Abdel-Aty-72.gif) (14) (14)
The correlation matrix of Yi =
Ri(α) with
eikt as a typical element can be written
as
 (15) (15)
or
 (16) (16)
where
![lowercase e caret subscript {lowercase i} = [lowercase e caret subscript {lowercase i 1}, ..., lowercase e caret subscript {lowercase i uppercase t subscript {lowercase i}}]](https://webarchive.library.unt.edu/eot2008/20090115200031im_/https://www.bts.gov/publications/journal_of_transportation_and_statistics/volume_08_number_01/images/Abdel-Aty-78.gif) and and ![uppercase a subscript {lowercase i} = Diag [uppercase a subscript {lowercase i 1}, ..., uppercase a subscript {lowercase i uppercase t subscript {lowercase i}}]](https://webarchive.library.unt.edu/eot2008/20090115200031im_/https://www.bts.gov/publications/journal_of_transportation_and_statistics/volume_08_number_01/images/Abdel-Aty-79.gif)
Then, var(Yi) depends on β and
Ri(α) where the latter takes the
effect of correlation in computing the covariance matrix
var(Yi). The matrix
Ri(α) is a Ti
by Ti block diagonal matrix. Each block is
a [(K – 1) × (K – 1)] matrix. The tth diagonal
block of Ri(α) is  , also the sth-row and
tth-column off-diagonal block
ρist(α) is , also the sth-row and
tth-column off-diagonal block
ρist(α) is
![lowercase rho subscript {lowercase i lowercase s lowercase t} (lowercase alpha) = uppercase a superscript {negative 1 divided by 2} subscript {lowercase i lowercase s} uppercase e [(uppercase y subcsript {lowercase i lowercase s} minus lowercase pi subscript {lowercase i lowercase s}) dot (uppercase y subscript {lowercase i lowercase t} minus lowercase pi subscript {lowercase i lowercase t}) prime] uppercase a superscript {negative 1 divided by 2} subscript {lowercase i lowercase t}](https://webarchive.library.unt.edu/eot2008/20090115200031im_/https://www.bts.gov/publications/journal_of_transportation_and_statistics/volume_08_number_01/images/Abdel-Aty-87.gif) (17) (17)
where
V i t = var (Y i
t) = Diag [π i t] - π i
t π′i t
and Diag[πit] denotes a diagonal
matrix with elements of πit on the main
diagonal and zero off-diagonal elements. The diagonal blocks of
Ri(α) depend only on
πi(β). In these diagonal blocks, the
diagonal elements are:
Corr (Y i k t , Y i
k t) = 1 (18)
and the off-diagonal elements are
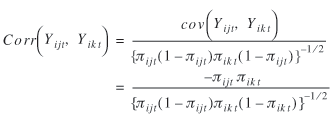 (19) (19)
Recall that these off-diagonal elements of the diagonal blocks of
Ri(α) depend only on the tth
choice of subject i from the K alternatives available.
This clearly takes care of any correlation among the different
alternatives of the multidimensional route choice model, usually due
to overlapping distances between different routes. Thus, the unknown
elements of Ri(α) are the elements
of its off-diagonal blocks ρist(α).
This must be estimated.
If ρist(α) is known, then
Ri(α) is known. The only unknown
term in equation 11 then is β. The estimated  can be obtained by a Fisher scoring
algorithm until convergence, can be obtained by a Fisher scoring
algorithm until convergence,
![lowercase beta caret superscript {lowercase m plus 1} = lowercase beta caret superscript {lowercase m} plus [summation from lowercase i = 1 to uppercase n of lowercase d [lowercase pi subscript {lowercase i} (lowercase beta caret superscript {lowercase m})] divided by lowercase d lowercase beta (lowercase beta caret superscript {lowercase m}) prime dot [uppercase v subscript {lowercase i} (lowercase beta caret superscript {lowercase m}, lowercase alpha caret superscript {lowercase m})]] superscript {negative 1} [lowercase d [lowercase pi subscript {lowercase i (lowercase beta caret superscript {lowercase m})] divided by lowercase d lowercase beta lowercase beta caret superscript {lowercase m}] superscript {negative 1} dot summation from lowercase i = 1 to uppercase n of lowercase d [lowercase pi subscript {lowercase i} (lowercase beta caret superscript {lowercase m})] divided by lowercase d lowercase beta (lowercase beta caret superscript {lowercase m}) prime [uppercase v subscript {lowercase i} (lowercase beta caret superscript {lowercase m}, lowercase alpha caret superscript {lowercase m})] superscript {negative 1} dot [uppercase y subscript {lowercase i} minus lowercase pi subscript {lowercase i} (lowercase beta caret superscript {lowercase m})]](https://webarchive.library.unt.edu/eot2008/20090115200031im_/https://www.bts.gov/publications/journal_of_transportation_and_statistics/volume_08_number_01/images/Abdel-Aty-104.gif) (20) (20)
where m is the iteration number. A starting β can
be obtained by applying the regular MNL model. Iteration should
continue until  and and  , where , where  is the estimated
ρist(α) in the mth step. is the estimated
ρist(α) in the mth step.
Estimating the Off-Diagonal Blocks of the Correlation
Matrix
Lipsitz et al. (1994) extended the exchangeable correlation
structure, introduced by Liang and Zeger (1986), used in BGEE for
multidimensional models. They used the same assumption that any two
observations on the same subject/cluster i and category
k are equally correlated. Under this assumption,
ρist(α) can be estimated as
![lowercase alpha caret = lowercase rho subscript {lowercase i lowercase s lowercase t} (lowercase alpha caret) = (summation from lowercase i = 1 to uppercase n of summation with lowercase t greater than lowercase s of lowercase e caret subscript {lowercase i lowercase s} lowercase e caret prime subscript {lowercase i lowercase t}) divided by ([summation from lowercase i = 1 to uppercase n of 0.5 uppercase t subscript {lowercase i} (uppercase t subscript {lowercase i} minus 1)] minus lowercase p)](https://webarchive.library.unt.edu/eot2008/20090115200031im_/https://www.bts.gov/publications/journal_of_transportation_and_statistics/volume_08_number_01/images/Abdel-Aty-114.gif) (21) (21)
where p is the total number of independent variables,
including any interactions. The residual vector
![lowercase e caret subscript {lowercase i lowercase t} = uppercase a caret superscript {negative 1 over 2} subscript {lowercase i lowercase t} [uppercase y subscript {lowercase i lowercase t} minus lowercase pi caret subscript {lowercase i lowercase t}]](https://webarchive.library.unt.edu/eot2008/20090115200031im_/https://www.bts.gov/publications/journal_of_transportation_and_statistics/volume_08_number_01/images/Abdel-Aty-115.gif) , ,
which is estimated by plugging from a previous step of iteration into
Ait and πit. It is
worth mentioning that the elements of the sth-row and
tth-column off-diagonal block
ρist(α) do not depend on the times
s and t, but they do depend on the levels j and
k.
ADDRESS FOR CORRESPONDENCE
* M. Abdel-Aty, Department of
Civil and Environmental Engineering, University of Central Florida,
Orlando, FL 32816-2450. E-mail: mabdel@mail.ucf.edu
|

