Respondent Behavior in Discrete Choice Modeling with a Focus on the Valuation of Travel Time Savings
DAVID A. HENSHER1,*
JOHN M. ROSE2
ABSTRACT
For models of discrete choice and their parameter estimates we examine the impact of assuming that all attributes are deemed relevant to some degree in stated choice experiments, compared with a situation where some attributes are excluded (i.e., not attended to) by some individuals. Using information collected exogenous of the choice experiment on whether respondents either ignored or considered each attribute of the choice task, we conditioned the estimation of each parameter associated with each attribute and compare, in the context of tolled vs. free routes for noncommuting car trips, the valuation of travel time savings under the assumption that all attributes are considered and the alternative assumption of relevancy. We show empirically that accounting for the relevance of attributes will have a notable influence on the valuation of travel time savings.
KEYWORDS: Stated choice experiment, willingness to pay, attribute relevance.
INTRODUCTION
What lies ahead for discrete choice analysis? . . . The potentially important roles of information processing, perception formation and cognitive illusions are just beginning to be explored, and behavioral and experimental economics are still in their adolescence. (McFadden 2001)
Stated choice (SC) experiments have become a popular method to model choice behavior in transportation contexts (see Louviere et al. 2000 for an overview). The outputs of SC models (e.g., willingness-to-pay estimates), have been used extensively to understand and model choice behavior (e.g., Jovicic and Hansen 2003; Jou 2001; Lam and Xie 2002), including the determination of the viability of new infrastructure projects such as proposed toll roads (e.g., Ortúzar et al. 2000; Hensher 2001). Given the risks often associated with these projects and the potential for large financial losses if they fail, it has become increasingly important that the outputs of SC models, such as the value of travel time savings (VTTS), be both reliable and unbiased estimates of the true population behavioral parameters that they purport to represent.
Realism in SC experiments can be captured by asking respondents to make "choices" between a finite but universal set of available alternatives, similar to those actions they would take in real markets. However, for any individual respondent, realism may be lost if the alternatives, attributes, and/or attribute levels used to describe the alternatives do not realistically portray that respondent's experiences or, in terms of "new" or "innovative" alternatives, are deemed not to be credible (e.g., Green and Srinivasan 1978, 1990; Cattin and Wittink 1982; Wittink and Cattin 1989; Lazari and Anderson 1994). An example in which individuals sometimes make decisions that deviate strikingly and systematically from the predictions of the standard SC model is the phenomena called availability effects, where responses rely heavily on readily retrieved information and too little on background information (e.g., rules adopted to process information) and the relevancy of such information. Information processing is distorted by what are called regression and superstition effects, in which we are too quick to attribute elaborate causal patterns to coincidences and attach too much permanence to fluctuations, failing to anticipate regression to the mean (McFadden 2001).
Regarding the attributes and attribute levels used within an SC experiment, significant prior preparation on behalf of the analyst may reduce the possible inclusion of irrelevant or improbable product descriptors within the choice sets shown to respondents (Hensher et al. 2005). Additionally, for quantitative variables, pivoting the attribute levels of the SC task from a respondent's current or recent experience is likely to produce levels within the experiment that are consistent with those experiences and, hence, produce a more credible or realistic survey task for the respondent (e.g., Hensher In press (a)).
Researchers have expended significant effort on the design of statistically efficient choice experiments (e.g., Bunch et al. 1996; Huber and Zwerina 1996; Kanninen 2002; Kuhfeld et al. 1994; Sandor and Wedel 2001) that minimize the amount of thought required of respondents (e.g., Louviere and Timmermans 1990; Oppewal et al. 1994; Wang et al. 2001; Richardson 2002; Swait and Adamowicz 2001a and b; Arentze et al. 2003). These efforts, however, appear to have been developed without adequate recognition that respondents may process SC tasks differently. That is, there may exist heterogeneity in the information processing strategies employed by respondents. SC surveys should, therefore, be tailored to be as realistic as possible at the level of the individual respondent.
Advances in econometric modeling of discrete choices, in the form of latent class and mixed logit models, may help in uncovering preference heterogeneity for attributes. However, experience suggests that, depending on the random parameter distribution, these models will likely assign non-zero parameter estimates to individual decisionmakers, even though their marginal utility for an attribute may be zero.1 This may apply to only a small number of decisionmakers, but a bias in the population parameter estimates is still likely to exist. Therefore, the econometric models used to estimate SC outputs need to be conditioned to assign to those individuals, who either ignore an attribute or do not have that attribute present, a zero parameter estimate.
This paper examines how we can use exogenous information on the attribute processing strategies (APS) employed by individual respondents undertaking SC tasks, and how such information can aid in conditioning the parameter estimates derived from the econometric models fitted. Additional nondesign information that may be captured in SC surveys and assist in revealing the APS include the inclusion/exclusion plan for each attribute as well as an aggregation plan (e.g., adding up attributes such as components of travel time). In this paper, we concentrate only on the attribute inclusion/exclusion strategy employed by individual respondents.
Experimental evidence and self-reported decision protocols support the view that heuristic rules are the proximate drivers of most human behavior (McFadden 2001). The question remains as to whether rules themselves develop in patterns that are broadly consistent with random utility maximization postulates. If there are preferences behind rules, then it is possible to define them and correctly evaluate policies in terms of these underlying preferences. It not, economics will have to seek a new foundation for this task. While many psychologists argue that behavior is far too sensitive to context and effect to be useful in relating to stable preferences, this is a somewhat pessimistic view. A number of authors have challenged this position (e.g., Hensher In press (a); McFadden 2001; Swait and Adamowicz 2001a). Many behavioral deviations from the economist's standard model can be attributed to perceptual illusions, particularly in the way in which we process information, rather than a more fundamental breakdown in the pursuit of self-interest. Many of the rules we do use are essentially defensive, protecting us from mistakes that perceptual illusions may induce.
There is a link between the topic here and the debate about self-explicated methods in conjoint analysis. This is especially true in light of the use of this method in Sawtooth's ACA software, which has an option to ask respondents prior to the conjoint tasks to indicate which attribute levels they would find unacceptable. ACA then deletes these declared unacceptable levels from the experimental design for the particular individual. The debate about this method has focused on whether respondents can reliably indicate which levels are unacceptable. Evidence shows that respondents often do consider or accept levels that they initially rejected. The method used for this paper is less affected by this issue, because the attribute screening task is presented after respondents have seen all the profiles or choice sets. So, when indicating which attributes they use or consider, the respondents know the complete attribute space.2
Adaptive choice-based conjoint (e.g., see Toubia et al. 2004) such as ACA also customizes the attribute levels of an SC experiment shown to a respondent using the previous choices made. This, however, is not the same as customizing the actual alternatives or attributes in order to make the choice task more realistic or believable to the individual respondent. Rose and Hensher (2004) addressed the mapping of alternatives in terms of their presence or absence in reality to choice experiments at the individual respondent level; however, presence or absence of attributes at the individual level is lacking in the literature. This is somewhat surprising given that, in real markets, there will likely exist heterogeneity in the information respondents have about the attributes and attribute levels of alternatives, as well heterogeneity in terms of the salience of and preference for specific attributes. For example, one respondent may have perfect information on the safety of using a tolled route compared with a free route and possess a positive marginal utility for the attribute, while a second respondent may have no understanding of the attributes' applicability to specific routes or the attributes in general and hence possess no marginal utility for the attribute at all. SC experiments assume that all respondents have perfect information (at least on the attributes included within the experiment) and that all respondents process these attributes in the same way.
MODEL DEVELOPMENT
Consider a situation in which q = 1,2,...,Q individuals evaluate a finite number of alternatives. Let subscripts j and t refer to alternative j = 1,2, ..., J and choice situation t = 1,2, ...,T. Random utility theory posits that the utility for alternative j present in choice situation t may be expressed as
 (1) (1)
where
U j t q is the utility associated with alternative j in choice situation t held by individual q,
x j t q is a vector of values representing attributes belonging to alternative j, characteristics associated with sampled decisionmakers q, and/or variables associated with context of choice situation t,
ε j t q represents unobserved influences on utility, and
θ′q is a vector of parameters such that θ = θ1, θ2, …, θK where K is the number of parameters corresponding to the vector x j t q
.
In the most popular choice model, multinomial logit, the probability that alternative i will be chosen is given as
 (2) (2)
where
V j t q = θ′qxj t q. (3)
Assuming a sample of choice situations, t = 1,2,...,T, has been observed with corresponding values x j t q, and letting i designate the alternative choice situation t, the likelihood function for the sample is given as
 (4) (4)
and the log-likelihood function of the sample as
![uppercase l asterisk (lowercase theta) = lon [uppercase l (lowercase theta) ] = summation from lowercase t = 1 to uppercase t of (lon (uppercase p (lowercase i | lowercase j)))](https://webarchive.library.unt.edu/eot2008/20090115181742im_/https://www.bts.gov/publications/journal_of_transportation_and_statistics/volume_08_number_02/images/Hensher_and_Rose-11.gif) .(5) .(5)
Equation (5) may be rewritten to identify the chosen alternative i
![uppercase l asterisk (lowercase theta) = summation of lowercase t = 1 to uppercase t of [uppercase v subscript {lowercase i lowercase t lowercase q} minus lon (summation from lowercase j of (lowercase e superscript {uppercase v subscript {lowercase j lowercase t lowercase q}}))]](https://webarchive.library.unt.edu/eot2008/20090115181742im_/https://www.bts.gov/publications/journal_of_transportation_and_statistics/volume_08_number_02/images/Hensher_and_Rose-12.gif) .(6) .(6)
Given that θ is unknown, it must be estimated from the sample data. To do this, we used the maximum likelihood estimator of θ, which is the value of  at which L (θ) is maximized. In maximizing equation (6), it is usual to use the entire set of data for Vj t q. That is, it is assumed that across all t, all V j t q and hence x j t q are considered, and, as such, the levels assumed by each x in the x j t q matrix are used in determining the value at which maximizes the likelihood estimator of θ . at which L (θ) is maximized. In maximizing equation (6), it is usual to use the entire set of data for Vj t q. That is, it is assumed that across all t, all V j t q and hence x j t q are considered, and, as such, the levels assumed by each x in the x j t q matrix are used in determining the value at which maximizes the likelihood estimator of θ .
Assuming that over a sample of choice situations t, not all k variables within the x j t q vector are considered in the decision process, the value of , which is conditioned on the assumption that all x j t q are considered, will likely be biased. For those choice situations in which attribute k is excluded from consideration in the choice process, 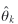 should be equal to zero. Note that this is not the same as saying that the attribute itself should be treated as being equal to zero.3 should be equal to zero. Note that this is not the same as saying that the attribute itself should be treated as being equal to zero.3
In cases where attribute k is indicated as being excluded from the decision process, rather than set the value for the kth element in the x j t q vector to zero and maximizing equation (6), the algorithm that searches for the maximum of equation (5) excludes that x from the estimation procedure and automatically assigns it a parameter value of zero. The parameter estimate is then estimated solely on the sample population for which the variable was not excluded. In this sense, the process is analogous to selectivity models (which censor the distribution, as distinct from truncation). To demonstrate, consider a simple example in which there are only two variables, x1 and x2, associated with each of j alternatives. Denote N as the number of attribute processing strategies such that n = 1 represents those decisionmakers who consider only x1 in choosing between the j alternatives, n = 2 represents those decisionmakers who consider only x2, and n = 3 represents those decisionmakers who consider both x1 and x2. The likelihood is defined by the partitioning of observations based on the subset membership defined above. The likelihood function is therefore given as
 .(7) .(7)
The derivatives of the log likelihood for groups n1 and n2 have zeros in the position of zero coefficients and the Hessians have corresponding rows and columns of zeros. This partitioning of the log-likelihood function may be extended to any of the logit class of models, including the nested logit and mixed logit family of models. We used a mixed logit specification in the empirical study, in which we accounted for preference heterogeneity in the specification of random parameters where their mean and standard deviation are a function of contextual influences.
θ q k = θ q + δ′k z q + δkexp(δ′k h q)v q. (8)
The distribution of θ q k over individuals depends in general on underlying structural parameters (θ k, δ k, σ k ), the observed data zq, a vector hq of M variables such as demographic characteristics that enter the variances (and possibly the means as well), and the unobserved vector of K random components in the set of utility functions
ηq = Γ Σ1 / 2 vq.
The random vector ηq endows the random parameter with its stochastic properties. In isolating the model components, we defined vq to be a vector of uncorrelated random variables with known variances. In the empirical study, we adopted a Rayleigh distribution (defined below) as the analytical representation of vq. The heteroskedastic mixed logit model is detailed in Greene et al. (2006). In the next section, we discuss the empirical application in which we estimate models of the form described above.
EMPIRICAL APPLICATION
The data used to contrast models that do and do not account for the attention paid to each attribute are drawn from a study undertaken in Sydney in 2004, in the context of car-driving noncommuters making choices from a range of level-of-service packages defined in terms of travel times and costs, including a toll where applicable. The sample of 223 effective interviews, each responding to 16 choice sets, resulted in 3,568 observations for model estimation.
To ensure that we captured a large number of travel circumstances, which will enable us to see how individuals trade off different levels of travel times with various levels of tolls, we sampled individuals who had recently taken trips of various travel times (called trip length segmentation) in locations with tollroads.4 To ensure some variety in trip length, three segments were investigated: no more than 30 minutes, 31 to 60 minutes, and more than 61 minutes (capped at two hours).
A telephone call was used to establish eligible participants from households stratified geographically, and a time and location agreed on for a face-to-face computer-aided personal interview. An SC experiment offers the opportunity to establish the preferences of travelers for existing and new route offerings under varying packages of trip attributes. The statistical state of the art of designing SC experiments has moved away from orthogonal designs to D-optimal designs (see below and Rose and Bliemer 2004; Huber and Zwerina 1996; Kanninen 2002; Kuhfeld et al. 1994; Sandor and Wedel 2001). The behavioral state of the art has moved to promoting designs that are centered around the knowledge base of travelers, in recognition of a number of supporting theories in behavioral and cognitive psychology and economics, such as prospect theory, case-based decision theory and minimum-regret theory.5 Starmer (2000, p. 353) makes a very strong plea in support of the use of reference points (i.e., a current trip):
While some economists might be tempted to think that questions about how reference points are determined sound more like psychological than economic issues, recent research is showing that understanding the role of reference points may be an important step in explaining real economic behaviour in the field.
The two SC alternatives are unlabeled routes. The trip attributes associated with each route are summarized in table 1. These were identified from reviews of the literature and through the effectiveness of previous VTTS studies undertaken by Hensher (2001).
All attributes of the SC alternatives are based on the values of the current trip. Variability in travel time for the current alternative was calculated as the difference between the longest and shortest trip time provided in non-SC questions. The SC alternative values for this attribute are variations around the total trip time. For all other attributes, the values for the SC alternatives are variations around the values for the current trip. The variations used for each attribute are given in table 2.
The experimental design has 1 version of 16 choice sets (games), with no dominance given the assumption that less of all attributes is better. The distinction between free flow and slowed down time is designed to promote the differences in the quality of travel time between various routes—especially a tolled route vs. a nontolled route—and is separate from the influence of total time. Free flow time is interpreted with reference to a trip at 3 a.m., when there are no traffic delays.6 Figure 1 illustrates an example of an SC screen, and figure 2 shows a screen with elicitation questions associated with attribute inclusion and exclusion.
In choosing the most statistically efficient design, the literature has tended toward designs that maximize the determinant of the variance-covariance matrix, otherwise known as the Fisher information matrix, of the model to be estimated. These so-called D-optimal designs require explicit incorporation of prior information about the respondents' preferences.7 In determining the D-optimal design, it is usual to use the inversely related measure to calculate the level of D-efficiency, that is, minimize the determinant of the inverse of the variance-covariance matrix. The determinant of the inverse of the variance-covariance matrix is known as D-error and will yield the same results maximizing the determinant of the variance-covariance matrix.
The log-likelihood function of the multinomial logit model is shown as
 (9) (9)
where y n j s is a column matrix with 1 indicating that an alternative j was chosen by respondent n in choice situation s and 0 otherwise, P n j s represents the choice probability from the choice model, and c is a constant. Maximizing equation (9) yields the maximum likelihood estimator, , of the specified choice model given a particular set of choice data. McFadden (1974) showed that the distribution of is asymptotically normal with a mean, , and covariance matrix
![uppercase omega = (uppercase x prime uppercase p uppercase x) = [summation from lowercase m = 1 to uppercase m of summation from lowercase j = 1 to uppercase j of lowercase x prime subscript {lowercase n lowercase j lowercase s} uppercase p subscript {lowercase n lowercase j lowercase s} lowercase x subscript {lowercase n lowercase j lowercase s}]](https://webarchive.library.unt.edu/eot2008/20090115181742im_/https://www.bts.gov/publications/journal_of_transportation_and_statistics/volume_08_number_02/images/Hensher_and_Rose-37.gif) (10) (10)
and inverse,
![uppercase omega superscript {negative 1} = (uppercase x prime uppercase p uppercase x) superscript {negative 1} = [summation from lowercase m = 1 to uppercase m of summation from lowercase j = 1 to uppercase j of lowercase x prime subscript {lowercase n lowercase j lowercase s} uppercase p subscript {lowercase n lowercase j lowercase s} lowercase x subscript {lowercase n lowercase j lowercase s}] superscript {negative 1}](https://webarchive.library.unt.edu/eot2008/20090115181742im_/https://www.bts.gov/publications/journal_of_transportation_and_statistics/volume_08_number_02/images/Hensher_and_Rose-38.gif) (11) (11)
where P is a JS × JS diagonal matrix with elements equal to the choice probabilities of the alternatives, j, over choice sets, s. For Ω, several established summary measures of error have been shown to be useful when contrasting designs. The most popular summary measure is known as D-error, inversely related to D-efficiency.
D-error = (det Ω−1)1 / K (12)
where K is the total number of generic parameters to be estimated from the design. Minimization of equation (12) will produce the design with the smallest possible errors around the estimated parameters.
MODEL RESULTS
Table 3 presents the model results for the experiment. Model 1 uses all data irrespective of whether a sampled individual indicated they had ignored an attribute throughout the experiment or not. Model 2 took into account the exogenous information on attribute relevance.
A profile of attribute inclusion and exclusion is shown in table 4. This is the attribute processing choice set for the sample. Just over half (52%) of the sample attended to every attribute and not one respondent attended to none of the attributes. Running cost was the attribute most likely to be ignored (17.9% of the sample); in contrast, the toll cost was attended to by 96% of the sample. Free flow time was not attended to by 13% of the sample, with 8.5 percentage points of this being when both components of travel time were ignored and the focus was totally on cost. The key message is that 78% of the sample attended to the components of travel time and 69% attended to the components of cost.
For both models, all parameters associated with the design attributes were specified as generic random parameter estimates. These parameters, with the exception of travel time variability, are statistically significant and of the expected sign. In specifying the mixed logit models, we drew the parameters associated with the design attributes from an unconstrained Rayleigh distribution. Hensher (In press (b)) showed that the Rayleigh distribution in its unconstrained and constrained forms has attractive properties. In particular, it does not have the long tail that the log normal exhibits and appears to deliver a relatively small proportion of negative VTTS when the function is not globally signed to be positive. The Rayleigh distribution probability function is given in equation (13).
 (13) (13)
for r ∈ [0, ∞). The moments about 0 are given by

where I(x) is a Gaussian integral. The Rayleigh variable8 is a special case of the Weibull density,9 with parameters 2 and s / 2 where s is the desired scale parameter in the Rayleigh distribution. The mean is centered as s* and the standard deviation is and the standard deviation is  . This distribution has a long tail, but empirically appears much less extreme than the log normal. We obtained the random parameter estimates of the mixed logit models using 500 Halton draws. . This distribution has a long tail, but empirically appears much less extreme than the log normal. We obtained the random parameter estimates of the mixed logit models using 500 Halton draws.
A comparison of models 1 and 2 reveals significant differences in their parameter estimates. Caution in interpretation, however, is required, because we have estimated complex nonlinear attribute functions as per equation (8), and so individual parameter estimates for the random parameters are not meaningful in isolation. The VTTS comparison, our behavioral output of interest for toll road patronage forecasting studies, provides a valid contrast and accounts for any scale differences.
The results in table 3 show the importance of accounting for heterogeneity in the mean of random parameters and heteroskedasticity in these parameters via decomposition of the standard deviation parameter estimate. The attribute inclusion rule influences the contributing effect. For example, all three random parameters are conditioned on the trip length in kilometers through decomposition of the standard deviation with strong statistical significance, yet the sign changes with respect to slowed down time. All other effects being held constant, when combined with the standard deviation of the random parameter (all being positive as required), we found that as trip length increased the standard deviation decreased, resulting in reduced heterogeneity in preferences over longer trips. The exception was when all data were considered relevant for slowed down time, with preference heterogeneity increasing as trip length increased.
Seven variables had a statistically significant influence on the mean of the three random parameters when all attributes were included; but when we allowed for attribution exclusion for the same set of influences, three became statistically insignificant. These influences on heterogeneity around the mean are opinion variables, derived from a weighting of a response on a seven-point Likert scale of the importance of such factors associated with toll roads in general and a seven-point "likely to deliver" Likert scale for specific tolled routes that respondents use. A positive parameter indicates, all other influences remaining fixed, that the opinion reflects something of greater importance and/or greater likelihood of it being delivered. For example, given that the mean estimate of the random parameter for slowed down time was negative and "avoid traffic lights" had a positive parameter estimate, the presence of a strong positive effect reduces the marginal (dis)utility of slowed down time. Again, we remind readers that, strictly, the signs cannot be interpreted independently of the full effect of all contributing sources aligned with the mean, the standard deviation and the sources of decomposition around the mean, and standard deviation parameter estimates. For example, the full marginal (dis)utility effect of free flow time for model 1 is:
θ q = {0.0893 + 0.0016 × lead to improved pedestrian safety + 0.1565 × exp [−0.0056 × trip kms] r} q (14)
In interpreting the parameter estimates for model 2, it is important to note that the estimates are specific only to sample population segments that consider an attribute while undertaking the choice experiment. For those in the population who do not consider an attribute, the parameter estimate expression in equation (14) for that individual is zero. That is, the parameter estimates are specific to each attribute inclusion/exclusion strategy. In terms of segmentation and benefit studies, this is an important development. In traditional models, these benefit segments may be lost if the segment is small relative to the total population size.
Willingness to pay (WTP) distributions for travel time savings can be derived from the conditional "individual specific" parameter estimates obtained using methods outlined in Train (2003) and Hensher et al. (2005). Estimates can be constructed of individual-specific preferences by deriving the conditional distribution based (in-sample) on known choices (i.e., prior knowledge), as originally shown by Revelt and Train (2000). These conditional parameter estimates are strictly same-choice-specific parameters or the mean of the parameters of the subpopulation of individuals who, when faced with the same choice situation, would have made the same choices. Table 5 summarizes the VTTS based on individual parameters. Not all WTP distributions are in the positive range (figure 3); indeed, the percentage that is negative is small (up to 2.9%) but substantially higher when we assume that all attributes are relevant for all respondents.
Given the differences in variances of the VTTS distributions over the models for the same attribute, we conducted a Kruskall-Wallis test, which is the nonparametric equivalent to the ANOVA test (Siegel and Castellan 1988). For the VTTS distributions obtained from the models, chi-square statistics were obtained for the free flow and slowed down time VTTS distributions, which we compared with a critical value of 5.99 (i.e., x22
at the 95% confidence level). We concluded that both the means and variances of the VTTS distributions for both attributes were statistically different between the two models.
Figure 3 shows the VTTS distributions for the free flow and slowed down travel time attributes estimated from the two models. When all data were used in the estimation process, the VTTS distribution had a much greater range than when the attribute inclusion/exclusion strategy was accounted for.
This evidence suggests a deflating effect on VTTS when one ignores the attribute processing strategy and assumes that all attributes are attended to. When the attribute exclusion rule was not included, the mean VTTS was 94.9% and 70.6%, respectively, of the VTTS under the attribution exclusion rule. Furthermore, when all attributes were deemed relevant, the mean VTTS for free flow and slowed down time was almost identical, in contrast to a slowed down time VTTS that was 32.2% higher than the free flow time value when the exclusion rule was invoked. The latter relationship is intuitively more appealing. When converted to time savings benefits in road projects, these differences would make a substantial difference to the user benefits, given the dominance of travel time savings.
DISCUSSION AND CONCLUSION
In this paper, we show that accounting for individual specific information on attribute inclusion/exclusion results in significant differences in the parameter estimates of and hence the willingness to pay for specific attributes in choice models. These differences arise from a form of respondent segmentation, the basis of which is respondent attribute processing. By partitioning the log-likelihood function of discrete choice models based on the way individual respondents process each attribute, the outputs of the models we estimated represent the attribute processing segments only, rather than those of the entire sample population. In this way, we can detect the preferences for different segments in the sample population based on the attribute processing strategies existing in that population. In traditional choice models, such segments will likely go undetected.
Whether an attribute should be excluded from model estimation for a specific respondent is critical to the method and the results. We recognize that there may be other ways of defining the behavioral rule for including or excluding an attribute.10 We also recognize that it is important to understand whether the attribute was excluded simply because of cognitive burden in the survey task in contrast to a genuine behavioral exclusion with respect to the relevance of the attribute in making such choices in real markets. It could be the case that the cognitive burden associated with the survey instrument may indeed be real, as it can be real in markets with information acquisition and processing; and so care is required in separating out and accounting for all these reasoning processes. Clearly, these conditions are all legitimate members of an individual's attribute processing strategy.
Ultimately, our preferred strategy would be to tailor the stated choice experiment to the individual based on the attribute processing strategy of the respondent. How best to do this is a matter of research. One question is whether the attribute processing strategy should be determined a priori and the SC experiment fixed for each respondent over the course of the experiment or whether the strategy is determined for each distinct choice set. The former approach is appealing for reasons of simplicity, the latter for completeness given that the attribute processing strategy may be linked not only to the attributes but to the attribute levels of the experiment.
The approach we outline here, whereby we employ an SC experiment derived from a single design plan, represents the more traditional approach to conducting SC experiments; however, we were able to account for the attribute processing strategy exogenously without having to tailor the SC experiment to each individual. Still, research is required as to whether it is best to ask each respondent which attributes were ignored at the end of the experiment, as we did here, or upon completion of each choice task. As with the tailoring of the SC task, the former approach is appealing for reasons of simplicity as well as the probable limiting of cognitive burden experienced by respondents, while the latter may represent a more complete approach, given that the attributes that are ignored or considered may be a function of the attribute levels of the alternatives as well as a function of experience or fatigue as the number of choice tasks completed increases.
We conclude by noting that the proposed approach discussed here applies equally to models estimated using revealed preference (RP) data. Researchers collecting RP data must prespecify the data collected and assume, as with SC data, that the attributes of RP data are processed homogenously over the sampled population. As with SC data, this need not be the case.
ACKNOWLEDGMENT
The comments of two referees improved this paper materially.
REFERENCES
Arentze, T., A. Borgers, H. Timmermans, and R. DelMistro. 2003. Transport Stated Choice Responses: Effects of Task Complexity, Presentation Format and Literacy. Transportation Research E 39:229–244.
Bunch, D.S., J.J. Louviere, and D. Anderson. 1996. A Comparison of Experimental Design Strategies for Choice-Based Conjoint Analysis with Generic-Attribute Multinomial Logit Models, working paper. Graduate School of Management, University of California, Davis.
Carlsson, F. and P. Martinsson. 2003. Design Techniques for Stated Preference Methods in Health Economics. Health Economics 12:281–294.
Cattin, P. and D.R. Wittink. 1982. Commercial Use of Conjoint Analysis: A Survey. Journal of Marketing 46(3):44–53.
Gilboa, I., D. Schmeidler, and P. Wakker. 2002. Utility in Case-Based Decision Theory. Journal of Economic Theory 105:483–502.
Green, P.E and V. Srinivasan. 1978. Conjoint Analysis in Consumer Research: Issues and Outlook. Journal of Consumer Research 5(2):103–123.
____. 1990. Conjoint Analysis in Marketing Research: New Developments and Directions. Journal of Marketing 54(4):3–19.
Greene, W.H., D.A. Hensher, and J. Rose. 2006. Accounting for Heterogeneity in the Variance of Unobserved Effects in Mixed Logit Models (NW Transport Study Data). Transportation Research B 40(1):75–92.
Hensher, D.A. 2001. Measurement of the Valuation of Travel Time Savings. Journal of Transport Economics and Policy 35(1):71–98.
____. 2004. Accounting for Stated Choice Design Dimensionality in Willingness to Pay for Travel Time Savings. Journal of Transport Economics and Policy 38(2):425–446.
____. In press (a). How Do Respondents Handle Stated Choice Experiments? Attribute Processing Strategies Under Varying Information Load. Journal of Applied Econometrics.
____. In press (b). The Signs of the Times: Imposing a Globally Signed Condition on Willingness to Pay Distributions. Transportation.
Hensher, D.A., J. Rose, and W.H. Greene. 2005. Applied Choice Analysis: A Primer. Cambridge, England: Cambridge University Press.
Huber, J. and K. Zwerina. 1996. The Importance of Utility Balance and Efficient Choice Designs. Journal of Marketing Research 33(3):307–317.
Jou, R. 2001. Modelling the Impact of Pre-Trip Information on Commuter Departure Time and Route Choice. Transportation Research B 35(10):887–902.
Jovicic, G. and C.O. Hansen. 2003. A Passenger Travel Demand Model for Copenhagen. Transportation Research A 37(4):333–349.
Kahnemann, D. and A. Tversky. 1979. Prospect Theory: An Analysis of Decisions Under Risk. Econometrica 47(2):263–291.
Kanninen, B.J. 2002. Optimal Design for Multinomial Choice Experiments. Journal of Marketing Research 39:214–217. May.
Kuhfeld, W.F., R.D. Tobias, and M. Garratt. 1994. Efficient Experimental Design with Marketing Research Applications. Journal of Marketing Research 21(4):545–557.
Lam, S.H. and F. Xie. 2002. Transit Path Models That Use RP and SP Data. Transportation Research Record 1799:58–65.
Lazari, A.G. and D.A. Anderson. 1994. Designs of Discrete Choice Experiments for Estimating Both Attribute and Availability Cross Effects. Journal of Marketing Research 31(3):375–383.
Louviere, J.J. and H.J.P. Timmermans. 1990. Hierarchical Information Integration Applied to Residential Choice Behaviour. Geographical Analysis 22:127–145.
Louviere, J.J., D.A. Hensher, and J.F. Swait. 2000. Stated Choice Methods and Analysis. Cambridge, England: Cambridge University Press.
McFadden, D. 1974. Conditional Logit Analysis of Qualitative Choice Behaviour. Frontiers of Econometrics. Edited by P. Zarembka. New York, NY: Academic Press.
____. 2001. Economic Choices: Economic Decisions of Individuals, notes prepared for a lecture at the University of California, Berkeley. March 18.
Oppewal, H., J.J. Louviere, and H.J.P. Timmermans. 1994. Modeling Hierarchical Information Integration Processes with Integrated Conjoint Choice Experiments. Journal of Marketing Research 31(1):92–105.
Ortúzar, J. de Dios., A. Iacobelli, and C. Valeze. 2000. Estimating Demand for a Cycle-Way Network. Transportation Research A 34(5):353–373.
Revelt, D. and K. Train. 2000. Customer-Specific Taste Parameters and Mixed Logit, working paper. Department of Economics, University of California, Berkeley. Available at http://elsa.berkeley.edu/wp/train0999.pdf.
Richardson, A.J. 2002. Simulation Study of Estimation of Individual Specific Values of Time Using an Adaptive Stated Preference Survey, paper presented at the Annual Meetings of the Transportation Research Board, Washington, DC.
Rose, J.M. and M.C.J. Bliemer. 2004. The Design of Stated Choice Experiments: The State of Practice and Future Challenges, working paper. University of Sydney. April.
Rose, J.M. and D.A. Hensher. 2004. Handling Individual Specific Availability of Alternatives in Stated Choice Experiments, paper presented at the 7th International Conference on Travel Survey Methods, Los Sueños, Costa Rica.
Sandor, Z. and M. Wedel. 2001. Designing Conjoint Choice Experiments Using Managers' Prior Beliefs. Journal of Marketing Research 38(4):430–444.
Siegel S. and N. Castellan. 1988. Nonparametric Statistics for the Behavioral Sciences. New York, NY: McGraw Hill.
Starmer, C. 2000. Developments in Non-Expected Utility Theory: The Hunt for a Descriptive Theory of Choice Under Risk. Journal of Economic Literature 38:332-382.
Swait, J. and W. Adamowicz. 2001a. The Influence of Task Complexity on Consumer Choice: A Latent Class Model of Decision Strategy Switching. Journal of Consumer Research 28:135–148.
____. 2001b. Choice Environment, Market Complexity, and Consumer Behavior: A Theoretical and Empirical Approach for Incorporating Decision Complexity into Models of Consumer Choice. Organizational Behavior and Human Decision Processes 49:1–27.
Train, K. 2003. Discrete Choice Methods with Simulation. Cambridge, England: Cambridge University Press.
Toubia, R., J.R. Hauser, and D.I. Simester. 2004. Polyhedral Methods for Adaptive Choice Based Conjoint Analysis. Journal of Marketing Research 41(1):116–131.
Wang, D., L. Jiuqun, and H.J.P. Timmermans. 2001. Reducing Respondent Burden, Information Processing and Incomprehensibility in Stated Preference Surveys: Principles and Properties of Paired Conjoint Analysis. Transportation Research Record 1768:71–78.
Wittink, D.R. and P. Cattin. 1989. Commercial Use of Conjoint Analysis: An Update. Journal of Marketing 53(3):91–96.
END NOTES
1. This will be the case if the constrained triangular or log-normal distributions are used. While these distributions force the parameter estimates to be of the same sign, they also ensure that few, if any, individual-specific parameter estimates will be zero.
2. We thank a referee for highlighting the point of distinction.
3. To demonstrate, consider the situation where attribute x j t q is the price for alternative j in choice situation t. For all but Giffen goods, setting the price to equal zero will likely make that alternative much more attractive relative to other alternatives in which the price is not equal to zero. Further, the procedure for maximizing L * (θ) will be ignorant of the fact that setting x j t q = 0 represents the exclusion of that attribute in the choice process and will estimate a value of assuming that the value observed by the decisionmaker in choice situation t was zero for that attribute when indeed it was not. As such, setting x k j t = 0 will not guarantee that the parameter for that attribute will be equal to zero for that choice situation. It is, therefore, that should be set to zero in the estimation process, not x k j t.
4. Sydney has a number of operating tollroads; hence, drivers have a lot of exposure to paying tolls. Indeed, Sydney has the greatest amount on urban kilometers under tolls than any other metropolitan area.
5. See Starmer 2000; Hensher 2004; Kahnemann and Tversky 1979; Gilboa et al. 2002.
6. This distinction does not imply that there is a specific minute of a trip that is free flow per se, but it does tell respondents that there is a certain amount of the total time that is slowed down due to traffic, for instance, and hence a balance is not slowed down (i.e., the trip is free flow like that observed typically at 3 a.m.).
7. Orthogonal designs also require prior information in order to choose the attribute levels in such a way that dominating and inferior attributes are avoided. Optimal designs will be statistically efficient but will likely have correlations; orthogonal fractional factorial designs will have no correlations but may not be the most statistically efficient design available. Hence, the type of design generated reflects the belief of analysts as to what is the most important property of the constructed design. Carlsson and Martinsson (2003) used Monte Carlo simulation to show that D-optimal designs, like orthogonal designs, produce unbiased parameter estimates but that the former have lower mean.
8. In the current paper, we use a conditional (on choice made) distribution, but for an unconditional distribution, the empirical specification used is
Rayleigh = 2 * (abs (log (r n u (0,1))))0.70710678 where r n u is the uniform distribution.
9. The Weibull(b,c) is: w = b * (−log U) ^ (1 / c).
10. Preliminary unpublished research by the authors in which we treat the exclusion rule as stochastic suggests that the mean VTTS is slightly higher than the evidence based on the deterministic application of the exclusion rule. This supports a position that suggests that failure to account for attribute processing rules tends to underestimate the mean VTTS.
ADDRESSES FOR CORRESPONDENCE
Corresponding author: D. Hensher, Institute of Transport and Logistics Studies, Faculty of Economics and Business, University of Sydney, NSW 2006, Australia. E-mail: davidh@itls.usyd.edu.au
J. Rose, Institute of Transport and Logistics Studies, Faculty of Economics and Business, University of Sydney, NSW 2006, Australia. E-mail: johnr@itls.usyd.edu.au
|

