Frequency and Severity of Belgian Road Traffic Accidents Studied by State-Space Methods
ELKE HERMANS 1
GEERT WETS 2 *
FILIP VAN DEN BOSSCHE 3
ABSTRACT
In this paper we investigate the monthly frequency and severity of road traffic accidents in Belgium from 1974 to 1999. We describe the trend in the time series, quantify the impact of explanatory variables, and make predictions. We found that laws concerning seat belts, speed, and alcohol have proven successful. Furthermore, road safety increases with freezing temperatures while sun has the opposite effect, and precipitation and thunderstorms particularly influence accidents with light injuries. Economic conditions have a limited impact. State-space methodology is used throughout the analysis. We compared the results of this study with those of earlier research that applied a regression model with autoregressive moving average errors on the same data. Many similarities were found between these two approaches.
KEYWORDS: Road safety, time series, trend, seasonal, explanatory model, state-space methodology, prediction.
INTRODUCTION
Every year, Belgium has about 70,000 road deaths and injuries (BIVV 2001). During the past decade, the steady increase in traffic volume has resulted in a steady growth in traffic problems. The negative impact of these problems on our society highlights the need for an effective road safety policy.
In order to take appropriate actions that will increase the level of road safety, we need to understand the underlying processes that result in traffic problems and their causes. This requires gathering extensive and reliable data over a long time period, together with modeling techniques suitable for describing, interpreting, and forecasting safety developments (EC 2004, 7). We studied the frequency and severity of traffic accidents in Belgium from 1974 through 1999.
Data in economics, engineering, and medicine are often collected in the form of time series—a sequence of observations taken at regular intervals of time (Peña et al. 2001, 1). This data collection method was also used here. From the broad category of time series model construction methods, we applied state-space methods in this study. This methodology will be explained in detail later in this paper. However, it is important to note here that one of the key characteristics of state-space time series models is that observations are regarded as comprising distinct components, such as trend, seasonal, and regression elements, each of which is modeled separately (Durbin and Koopman 2001, vii) and has a direct interpretation. Furthermore, the components are allowed to change in time, and the stationarity of the series is not required.
TIME SERIES APPLICATIONS IN ROAD SAFETY
The increasing interest in road safety is evident in the literature. An important class of road safety models is based on time series analysis. The succession of data points in time is a fundamental aspect in this analysis. Models are used to describe the behavior of the data, to explain the behavior of the time series in terms of exogenous variables, and for forecasting (Aoki 1987, v). The most relevant ideas highlighting developments in road safety inside this movement are described in the COST329 report of the European Commission (2004).
In addition to giving a description of the trend in traffic data, many models test the influence of explanatory factors. A simple, well-known example of such a time series model is the classical linear regression, which assumes a linear relationship between a criterion or dependent variable ( y t ) and one or more predictor or independent variables ( x t ). Explanatory models describe how the target variable depends on the explanatory variables and interventions. One special and prominent class of explanatory models in road safety analysis is known as the DRAG (Demand Routière, les Accidents et leur Gravité) family, extensively described in Gaudry and Lassarre (2000). DRAG models are structural explanatory models that include a relatively large number of explanatory variables whose partial effects on the exposure, the frequency, and the severity of accidents are estimated by means of econometric methods (EC 2004, 174).
The COST329 report (EC 2004, 47) mentions two main classes of univariate dynamic models: ARIMA models studied by Box and Jenkins; and unobserved components models, which are called structural models by Harvey. In a structural model, each component or equation is intended to represent a specific feature or relationship in the system under study (Harvey and Durbin 1986, 188). The models used here, state-space methods, belong to the latter group. To date, Box-Jenkins methods for time series analysis are applied more widely and are more popular than state-space methods, but this study will show the strengths of the state-space methodology.
Both classes are concerned with the decomposition of an observed time series into a certain number of components. ARMA models decompose the series into an autoregressive (AR) process, a moving average (MA) process, and a random process. Unobserved components models decompose a series in a trend, a seasonal, and an irregular part. An important characteristic is that the components can be stochastic. Moreover, explanatory variables can be added and intervention analysis carried out. The principal structural time series models are, therefore, nothing more than regression models in which the explanatory variables are functions of time and the parameters are time-varying (Harvey 1989, 10). The key to handling structural time series models is the state-space form, with the state of the system representing the various unobserved components. Once in state-space form, the Kalman filter (Kalman 1960) may be applied and this in turn leads to estimation, analysis, and forecasting.
Harvey (1989, 22–23) wrote comprehensively on structural time series models (primarily applied to economic time series), presenting an historical overview of the technique. A rapid growth of interest has ensued in recent years. Nowadays, the technique of unobserved components models is used in several studies: Flaig (2002) applied it to quarterly German Gross Domestic Product (GDP), Cuevas (2002) to real GDP and imports in Venezuela, and Orlandi and Pichelmann (2000) to unemployment series. Other than those economic applications, this technique (more specifically an intervention analysis) was also used in traffic-related research (Balkin and Ord 2001; Harvey and Durbin 1986). The state-space methodology forms a well-used approach in modeling road accidents in a number of countries, for example, the Netherlands (Bijleveld and Commandeur 2004), Sweden (Johansson 1996), and Denmark (Christens 2003). This paper presents the results of the first state-space analysis on Belgian data.
DATA
The data used in this study are monthly observations from January 1974 through December 1999; 12 observations each year over a period of 26 years equals 312 observations. All data have been gathered from governmental ministries and official documents published by the Belgian National Institute for Statistics. In addition to four dependent traffic-related variables, we studied the effect of 16 independent variables. These 16 explanatory factors can be divided into 3 groups: juristic, climatologic, and economic variables. Table 1 gives an overview of all the variables used in this study.
The four dependent variables in our data are the number of accidents with persons killed or seriously injured (NACCKSI), the number of accidents with minor injuries (NACCLI), the number of persons killed or seriously injured (NPERKSI), and the number of persons with minor injuries (NPERLI). The evolution in time of these variables is displayed in figures 1a and 1b. In order to make a comparison between the results of the state-space method and the regression model with ARMA errors, the same variables, data, and time periods were used. In accordance with the study of the regression model with ARMA errors, the logarithm of the dependent variables were modeled and written respectively as LNACCKSI, LNACCLI, LNPERKSI, and LNPERLI.
As figure 1a reveals, the variables concerning killed or seriously injured persons (NACCKSI and NPERKSI) show a decreasing trend over the period. This is less obvious in the case of lightly injured casualties (figure 1b). Another aspect is the recurring pattern in the data. Thirdly, some months have an extremely low value.
The first group of explanatory variables contains laws and regulations. Five dummy variables were included in the model to study the effect of policy measures introduced in Belgium at a certain date within the scope of our analysis. These variables are equal to zero before the introduction and have a value of one from the moment of introduction. Table 1 describes the laws. Weather conditions form the second group of explanatory factors. All meteorological variables were gathered by the Belgian Royal Meteorological Institute and published by the National Institute for Statistics. The quantity of precipitation (in mm) was measured as an average for the whole country. The other variables were measured in the climatologic center in Ukkel (in the center of Belgium). Thirdly, the influence of four indicators of the economic climate will be investigated.
According to several studies (e.g., Fridstrøm et al. 1995, 12; OECD 1997, 16), exposure is a key variable in traffic research. In this study, the frequency and severity of accidents will be explained by many variables, but the impact of exposure is not measured. We cannot describe this effect because adequate monthly data of the total number of kilometers covered on the whole Belgian road system are not available. Population-related exposure statistics could be a solution, but these data are only available on a yearly basis, and no distribution code is at hand. Although we are aware that this is a serious limitation, even without an exposure variable valid models can be constructed and a good fit obtained. (For more details, refer to Van den Bossche et al. 2005). Other factors possibly omitted are assumed to be taken into account to some extent by the unobserved components framework.
METHODOLOGY
In this study, state-space models are constructed using STAMP software (Koopman et al. 2000). With state-space models, we were able to obtain an explicit description of the series in terms of trend and seasonal. It was also possible to quantify the impact of explanatory factors. For example, the effect of road safety measures over time can be checked by adding so-called intervention variables to the model. Apart from these purposes, state-space models can easily be used for forecasting. (For a technical discussion of state-space models, see to the methodological appendix at the end of this paper.)
The objective here is to find the model that best describes the data. For each of the four dependent variables, we constructed several state-space models, each with their specific components. To be able to choose the best model, we used the Akaike Information Criterion (AIC), a measurement of fit that takes the number of parameters into account (Akaike 1973, 267–281; Koopman et al. 2000, 180).
We conclude this section with the discussion of some of the advantages of state-space models compared with classical regression. An interesting characteristic of state-space methods is the possibility of modeling stochastically the variation in the estimation of the various components. Contrary to classical regression models, where components are fixed or unchangeable in time, a component can also vary in time. This is an advantage because variation in time makes it easier to follow the fluctuations in the data. Secondly, when the time dependency between observations is taken into account (which is not the case in classical regression analysis), the observation errors will mostly be situated more closely to independently random values. This makes significance tests of explanatory variables more reliable. Furthermore, state-space methods can easily handle missing observations, multivariate data, and (stochastic) explanatory variables. A last advantage is that the components can be modeled separately and interpreted directly.
RESULTS
Not all numerical outcomes of the different models will be presented here. However, this section reports and discusses the most essential results of the analysis. It is divided into four parts. First, the outcomes of the descriptive analysis are presented, followed by an interpretation of the explanatory analysis. Next, the forecasting capacity is evaluated. Finally, we compare our results with those obtained by the regression model with ARMA errors and deduce the most important similarities and differences between these two methodologies.
Description
Based on AIC, we chose the model that best describes the accident data. For each of the four variables the same model resulted in the best fit. This contains a stochastic trend (that adapts every time period) and a deterministic or fixed recurring seasonal pattern.
The interpretation of the seasonal coefficients shows that October and June are the most unsafe road traffic months of the year. During these months, respectively, approximately 13% and 11% more accidents happen than on average. The October percentage can be partly explained by the fact that it is a long month (31 days) without holidays; it is autumn and there is the transition from Central European Summer Time to Central European Time; and it is the start of the academic year. Possible explanations are not apparent for the large number of accidents during June.
Explanation
To look at the explanatory objective, we tested the effect of 16 independent variables. In order to obtain more reliable results (which implies normally distributed residuals), we added correction variables to the model.
The inclusion of correction variables has algebraically been presented in the model formulation (see the methodological appendix). In general, two main intervention effects can be distinguished (Sridharan et al. 2003), namely a pulse intervention and a step intervention. The first effect is used to capture single special events because they may cause outlying observations that the pulse regression variable accounts for. The variable takes value 1 if t is the month that needs correction for a special event and has value 0 otherwise. The second intervention—called a step intervention or level shift—is added to the model to capture events such as the introduction of new policy measures. Laws and regulations can be incorporated in a model as this second type of intervention. Before its introduction, the variable has value 0, but from the moment of introduction it has value 1. Our focus is on the first type, the temporal pulse intervention.
As could be seen on the graphs of the actual data (figures 1a and 1b) as well as on the graph of the residuals (figure 2), the number of accidents and casualties was unexpectedly low during some months. Either these months indeed had extremely low values or some registration error was left in the accident statistics. The following are extreme values for which correction is necessary. January 1979, January 1984 (only for LNPERLI, so a registration error probably occurred here), January 1985, and February 1997 are outliers. There are some indications for a very severe winter in 1979 and 1985 (BIVV 2001, 5). We explicitly correct for those four months by adding pulse intervention variables to the model, which are coded one during the month they represent and zero elsewhere. We are convinced that the most striking shocks must be excluded in order to fulfill the error terms conditions: no autocorrelation, homoscedasticity, and normality. In the end, we want to obtain a correct parameter interpretation. The inclusion of these correction variables lowers the difference between the predicted and the real series and thus improves the quality of the estimations. All tested correction variables are highly statistically significant. The exact t -values are given in table 2 under "correction variables." Taking these outliers into account, the fit of the models improves.
The last step in the construction of the final model consists of the significance tests of the explanatory variables. An explanatory variable must have a significant influence at least at the 90% confidence level to be included in the final model. Each model was re-estimated after dropping the nonsignificant variables such that the ultimate model for every dependent variable consists of a stochastic level, a deterministic seasonal, and significant correction and explanatory variables. The addition of significant explanatory variables further improves the fit. Table 2 gives an overview of all significant combinations of variables. The parameter estimates and the t -statistics (between brackets) of the significant explanatory and correction variables according to the state-space method on the one hand and the regression model with ARMA errors on the other hand are presented.
At first sight, there are a lot of similarities between the results of the two methods. Note that the majority of explanatory variables is statistically significant at least at the 95% confidence interval. In the remainder of this section, we will interpret the significant explanatory variables according to the state-space method per category.
The results of laws and regulations are instructive and interesting. Three of the five variables originally included in the model proved to be significant for at least two dependent variables. Their introduction has been of major importance for road safety. This is reflected by the magnitude of the coefficients. The negative signs are as expected because laws are established to enhance road safety. The introduction of the law of June 1975 (LAW0675)— the mandatory seat belt use in the front seats—resulted in a considerable and highly significant increase in road safety. This law reduced all kinds of accidents and casualties. Several empirical studies (Hakim et al. 1991, 392; Harvey and Durbin 1986) have shown that seat belt legislation significantly reduces the number of fatalities and the severity of injuries. The introduction of a speed limit of 50 km/h in urban areas and 90 km/h at road sections with at least 2 x 2 lanes without separation (LAW0192) seemed significant for two dependent variables. The literature verifies the positive effect on road safety in case of a reduction in speed limit. Severity of injuries appears to be positively related to the allowed speed (Van den Bossche and Wets 2003, 15; Hakim et al 1991, 390). Yet another promising effect can be noted for the regulations and fines on the maximum blood alcohol concentration (LAW1294). They played an important role in the decrease in the number of serious accidents and the number of persons killed or seriously injured. The results confirm the hypothesis that drunk drivers often cause serious or fatal accidents. Amongst others, Gaudry (2000, 1-36) studied the effect of the consumption of alcohol on road safety and found that the relative accident probability, as a function of blood alcohol concentration, is J-shaped.
In our models, it is assumed that the introduction of a law results in a sudden and permanent decrease in the dependent variable. This assumption of a step-based intervention is not always a natural one (Van den Bossche et al. 2004, 8). The significant impact of laws and regulations may be better described as "something changed at that time," instead of attributing the whole effect to the law itself. Nevertheless, it makes sense to test whether these changes are indeed substantial.
As one would expect intuitively, the weather plays an important role in explaining the number of accidents and casualties (especially for the variables concerning lightly injured persons). In terms of direction, we can make a distinction between precipitation, sun, and thunderstorms on the one hand and freezing temperatures on the other hand. In addition to precipitation (QUAPREC and PDAYPREC) and thunderstorms (PDAYTHUN), the sun (HRSSUN) is a factor tied to an increase in accidents. It is plausible to assume reduced visibility in stormy weather and on sunny days, a greater likelihood of blinding by the sun. The only weather variable that has a positive effect on road safety is the monthly percentage of days with freezing temperatures (PDAYFROST). A possible explanation is that drivers adjust their driving habits—steer more slowly and prudently and concentrate more—because they perceive driving in freezing conditions as dangerous (which is not the case with rain and thunderstorms). Thus, it seems like road users compensate for the higher risk imposed by freezing temperatures. This result is in line with other studies (Fridstrøm et al. 1995, 9) wherein it is mentioned that exposure to traffic is lower in winter and the average driving capacity increases because less proficient drivers prefer to avoid driving on slippery roads.
The impact of freezing road conditions (PDAYFROST) and sun (HRSSUN) is noticeable for all dependent variables. The quantity of precipitation (QUAPREC) and the monthly percentage of days with thunderstorms (PDAYTHUN) are only relevant for the variables concerning lightly injured casualties. Eisenberg (2004, 641) noticed that in adverse weather conditions, persons possibly drive more slowly and therefore, on average, accidents are less severe.
Concerning the quantity of precipitation (QUAPREC) (on the killed or seriously injured outcomes) it is possible that two effects canceled out each other. As also found in Gaudry and Lassarre (2000, 67–96), the onset of rain has a larger and more general impact than the amount of rain (habituation can lead to more risky driving behavior). A conclusive remark on the explanatory capacity of weather conditions is that the effect of weather data is strongly related to the geographical properties of the area of concern and the level of aggregation.
Concerning the economically related variables, two economic indicators happened to be significant, namely the number of unemployed (LNUNEMP) and the number of car registrations (LNCAR) for the variable LNPERKSI. They have an opposite sign and both imply that a better economy—with less unemployment and more car registrations—decreases the number of killed or seriously injured casualties. In the literature the findings about the direction of this effect are very diverse (Hakim et al. 1991, 384). In this study, the number of car registrations is used as one of the indicators for the economic climate. The assumption we make is that when the economy goes well more cars will be bought, and the average quality of the vehicles on the road increases. In the future, more variables (e.g., disposable income) should be included in the analysis to better assess the explanatory capacity of economic variables and their impact.
Prediction
The third objective of this study is predicting accident data with state-space methods for the years 2000 and 2001. Future values of the explanatory variables are available. Only the values of QUAPREC and PDAYTHUN for 2001 have to be estimated. This is done with a simple univariate state-space model based on the data from 1974 through 2000.1) We use the final model—which contains a stochastic level, a deterministic seasonal, and significant explanatory and correction variables—to forecast the values of the out-of-sample dataset for 2000 and 2001 and compare them to the actual observations. To depict possible uncertainty, 95% prediction intervals are provided. The graphs (see figure 3) show us that the predictions are close to the actual observations. So we are able to capture a great part of the fluctuations in the series. Only a few points lie outside the prediction intervals.
Apart from a visual presentation, we also quantified the forecasting precision. We interpreted the results of the Failure Chi-squared test and computed the mean squared error (MSE). Those tests confirmed our conclusion of accurate predictions.
Comparison with ARMA regression model
In addition to the interesting characteristics of state-space models already mentioned in the methodology section, we discuss an important disadvantage of ARIMA models here. It is not possible to explicitly describe a time series in terms of the different components because ARIMA models require the time series to be stationary (Harvey and Durbin 1986, 188). In those models the trend and/or seasonal are treated as a problem and therefore removed from the series by a procedure called differencing (in order to transform the series into a stationary one) before any analysis can be performed. But few economic and social time series are stationary, and there is no overwhelming reason to suppose that they can necessarily be made stationary by differencing (Harvey and Shephard 1993, 266).
In 2003, a study on intervention time series analysis of crime rates (Sridharan et al.) showed that the results of a legislation on different kinds of crimes were very similar between the ARIMA model and the structural time series model. Both coefficients and t -values were very analogous. A comparison with the regression model with ARMA errors, however, showed different results. Earlier, Harvey and Todd (1983) compared the results of the prediction of a number of economic time series done by the basic structural model with those obtained using the Box-Jenkins models. They concluded that the forecasts given by both methods are comparable.
In this study, we investigate the differences and similarities in explanatory and predictive analysis between the state-space method and the regression model with ARMA errors. Table 2 shows that the outcomes of these two approaches are comparable. The same correction variables seemed significant and the juristic and climatologic variables also matched quite well. Different from the results of the regression model with ARMA errors is the fact that two of the four economic variables are significant. A possible reason is that the evolution in economic factors is a very slow one. In case of a regression model with ARMA errors differences are taken, resulting in almost a constant. Differencing possibly cancels out the already little variation in time. Next, the estimated parameters of the two methods have the same (expected) sign and are of the same order of magnitude.
Both methods forecasted the data for the year 2000, so we are able to assess and compare the quality of the predictions. The measure used is MSE, and the values of the two methodologies for the four variables are reported in the last row of table 2. The lower MSE, the better the prediction. The values are of the same order of magnitude. The predictions for the two variables concerning killed or seriously injured persons from the regression model with ARMA errors are more accurate. The state-space method better predicts the values of the variables concerning lightly injured persons. In case of killed or seriously injured persons, the decreasing level is more important than the recurring seasonal pattern. In contrast, for light injuries with values fluctuating around the average, the seasonal effect is more important. Because the seasonal effect is explicitly modeled in the state-space model, this model possibly predicts more accurately in case of lightly injured persons than the regression model with ARMA errors.
CONCLUSIONS
In this study state-space models were elaborated to describe the developments in the frequency and severity of accidents and casualties in Belgium from 1974 through 1999. Furthermore, the impact of laws, weather, and economic conditions was measured. In the third place, an out-of-sample forecast of the dependent variables for 24 months was made. The results were compared with those obtained from a regression model with ARMA errors, based on the same data.
For each of the four dependent variables we built several models. The model that described all data best consisted of a level that is allowed to vary over time and a seasonal. Explanatory and correction variables were added to this descriptive model. The fact that accidents happen can to a certain extent be attributed to juristic, meteorological, and economic factors. Due to data and multicollinearity issues and for reasons of comparison, we tested the influence of 16 independent variables. Additionally, correction variables for January 1979, January 1984 (only for LNPERLI), January 1985, and February 1997 were significant.
From this study we can conclude that there is a lot of similarity between the results of the state-space method and the regression model with ARMA errors. Both methods labeled (more or less) the same explanatory variables as significant, and their influence was at all times in the same direction and of comparable magnitude. Several laws had a clear positive effect. Apart from those, the weather elements precipitation, sun, freezing temperatures, and thunderstorms were important. Nevertheless, note the difference between the two methods on the subject of the economic variables. The forecasting capacity of the methods was tested quantitatively and was shown to be approximately the same.
The models developed in this text show large potential for describing long-term trends in road safety. On the one hand, they can isolate the effect of phenomena that cannot be influenced, but certainly act on road safety (for example the weather). Similarly, macroeconomic and sociodemographic evolutions could be added to the model. On the other hand, the efficiency of policy decisions (for example laws) or time-specific interventions can be tested. These are the direct tools for increasing the level of road safety. Moreover, forecasts can be made, uncertainty estimated, and ruptures in the time series detected. Furthermore, some advantages of state-space methods over regression and ARIMA models were reported.
We conclude with some topics for model improvement and further research. In this study the variable exposure was not included. In the future, monthly observations of the total mileage covered on the Belgian road system could be taken into account in order to measure this effect. Secondly, because the number of variables in our models is limited, the effect of more explanatory factors could be tested, for example income or public transportation. The elaboration of data quality and availability together with the development of extensive but statistically sound models should lead to high quality results.
REFERENCES
Akaike, H. 1973. Information Theory and an Extension of the Maximum Likelihood Principle. Second International Symposium on Information Theory.Edited by P.N. Petrov and F. Csaki. Budapest: Akadémiai Kiadó.
Aoki, M. 1987. State Space Modeling of Time Series.New York, NY: Springer-Verlag.
Balkin, S. and J.K. Ord. 2001. Assessing the Impact of Speed-Limit Increases on Fatal Interstate Crashes. Journal of Transportation and Statistics 4(1):1–26.
Belgisch Instituut voor de Verkeersveiligheid (BIVV). 2001. Verkeersveiligheid Statistieken 2001. Available at http://www.bivv.be/main/PublicatieMateriaal/Statistieken.shtml.
Bijleveld, F.D. and J.J.F. Commandeur. 2004. The Basic Evaluation Model, paper presented at the ICTSA meeting, INRETS, Arcueil, France, May 27–28, 2004.
Christens, P.F. 2003. Statistical Modelling of Traffic Safety Development, IMM-PHD-2003-119. Available at http://www.imm.dtu.dk.
Cuevas, M.A. 2002. Demand for Imports in Venezuela: A Structural Time Series Approach, World Bank Policy Research Working Paper No. 2825. Available at http://ssrn.com/abstract=313423.
Durbin, J. and S.J. Koopman. 2001. Time Series Analysis by State-Space Methods.Oxford, England: Oxford University Press.
Eisenberg, D. 2004. The Mixed Effects of Precipitation on Traffic Crashes. Accident Analysis and Prevention 36: 637–647.
European Commission (EC). 2004. COST Action 329: Models for Traffic and Safety Development and Interventions.Luxembourg: European Communities.
Flaig, G. 2002. Unobserved Components Models for Quarterly German GDP, CESifo Working Paper no. 681. Available at http://www.cesifo.de.
Fridstrøm, L., J. Ifver, S. Ingebrigtsen, R. Kulmala, and L.K. Thomsen. 1995. Measuring the Contribution of Randomness, Exposure, Weather and Daylight to the Variation in Road Accident Counts. Accident Analysis and Prevention 27(1):1–20.
Gaudry, M. and S. Lassarre. 2000. Structural Road Accident Model: The International DRAG Family.Oxford, England: Elsevier Science Ltd.
Hakim, S., D. Shefer, A.S. Hakkert, and I. Hocherman. 1991. A Critical Review of Macro Models for Road Accidents. Accident Analysis and Prevention 23(5):379–400.
Harvey, A.C. 1989. Forecasting, Structural Time Series Models and the Kalman Filter.Cambridge, England: Cambridge University Press.
Harvey, A.C. and J. Durbin. 1986. The Effect of Seat Belt Legislation on British Road Casualties: A Case Study in Structural Time Series Modeling. Royal Statistical Society A 149(3):187–227.
Harvey, A.C. and N. Shephard. 1993. Structural Time Series Models. Handbook of Statistics 11:261–302.
Harvey, A.C. and P.H.J. Todd. 1983. Forecasting Economic Time Series with Structural and Box-Jenkins Models: A Case Study. Journal of Business and Economic Statistics 1(4):299–315.
Johansson, P. 1996. Speed Limitation and Motorway Casualties: A Time Series Count Data Regression Approach. Accident Analysis and Prevention 28(1):73–87.
Kalman, R.E. 1960. A New Approach to Linear Filtering and Prediction Problems. Journal of Basic Engineering D 82:35–45.
Koopman, S. J., A.C. Harvey, J.A. Doornik, and N. Shephard. 2000. Stamp: Structural Time Series Analyser, Modeller and Predictor.London, England: Timberlake Consultants Ltd.
Organization for Economic Cooperation and Development (OECD). 1997. Road Safety Principles and Models: Review of Descriptive, Predictive, Risk and Accident Consequence Models.Paris, France.
Orlandi, F. and K. Pichelmann. 2000. Disentangling Trend and Cycle in the EUR-11 Unemployment Series, ECFIN/27/2000-EN, No. 140. Available at http://europa.eu.int.
Peña, D., G.C. Tiao, and R.S. Stay. 2001. A Course in Time Series Analysis.New York, NY: John Wiley & Sons.
Sridharan, S., S. Vujic, and S.J. Koopman. 2003. Intervention Time Series Analysis of Crime Rates, TI 03-040/4. Available at http://www.tinbergen.nl.
Van den Bossche, F. and G. Wets. 2003. Macro Models in Traffic Safety and the DRAG Family: Literature Review, RA-2003-08. Available at http://www.steunpuntverkeersveiligheid.be/en.
Van den Bossche, F., G. Wets, and T. Brijs. 2004. A Regression Model with ARMA Errors to Investigate the Frequency and Severity of Road Traffic Accidents. Proceedings of the 83rd Annual Meetings of the Transportation Research Board, Washington, DC, January 11–15, 2004: 1-15.
______. 2005. The Role of Exposure in the Analysis of Road Accidents: A Belgian Case-Study. Proceedings of the 84th Annual Meetings of the Transportation Research Board ,Washington, DC, January 9–13, pp.1–16.
METHODOLOGICAL APPENDIX
In this appendix state-space models are discussed in more detail. The overall objective of the state-space analysis is to study the development of the state over time using observed values (Durbin and Koopman 2001, 11). More specifically, we want to obtain an adequate description of this development and to find explanations hereof. Furthermore, these models have the ability to predict developments of a series into the future.
The state is the unobserved value of the true development at time t . The gathering (or space) of possible values of the state is called the state-space of the process. The state consists of several components: on the one hand a l evel, slope, and seasonal that give a description of the time series and on the other hand explanatory and intervention variables that give an explanation about the actual development in the series.
A state-space model consists of an observation or measurement equation and one or more state equations (depending on the number of components). The first one contains the unobserved state at time t and an observation residual (ε t ), which is white noise. In the state equation, time dependencies in the observed time series are dealt with by letting the state at time t +1 be a direct function of the state at time t, and the state error is also white noise. Algebraically, the final state-space model used in this analysis can be written as:
(Eq. 1) 
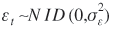
(Eq. 2)  
(Eq. 3) 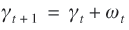 
(Eq. 4)  
(Eq. 5)  
for t = 1,..., n ; j =1,..., k and i =1,..., l .
The observation equation (Eq. 1) relates the values of the dependent variable y t to the level μt , the seasonal component γt , explanatory variables x jt ( j = 1,..., k ), intervention variables w it ( i = 1,..., l ), and an observation error εt . Each component has its state equation (Eq. 2 till 5 respectively). All (observation and state) errors are assumed to be mutually independent and normally distributed with mean zero and variances  , ,  , ,  , ,  and and 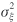 respectively. βj is the unknown regression coefficient of the j th explanatory variable. One type of intervention is the temporal pulse intervention. Only during one time point a correction of an unusual high or low value occurs. In this paper, four correction variables of this type were used. Concerning these variables, w it = 1 if t is the month of correction, and 0 otherwise. λi is the coefficient of the i th correction variable. respectively. βj is the unknown regression coefficient of the j th explanatory variable. One type of intervention is the temporal pulse intervention. Only during one time point a correction of an unusual high or low value occurs. In this paper, four correction variables of this type were used. Concerning these variables, w it = 1 if t is the month of correction, and 0 otherwise. λi is the coefficient of the i th correction variable.
The error variances are used in order to obtain the most parsimonious model that describes the data best. Each component can be chosen deterministically or stochastically. Deterministic implies one parameter estimate during the whole time period while stochastic implies that the estimate will be adapted every time point. However, this last option requires more parameters. Whether a state component should be treated deterministically or stochastically can be determined by evaluating the error variance of the component when analyzed stochastically. If the error variance of the stochastic component is very small (i.e., almost zero), this indicates that the corresponding state component should be handled deterministically. Because we consider only deterministic explanatory variables, the corresponding errors τjt are equal to zero.
In state-space methods the value of the unobserved state at the beginning of the time series ( t = 1) is unknown. Using diffuse initialisation (Durbin and Koopman 2001, 28) estimates for the unknown parameters are obtained. Also none of the observation and state error variances are known. The estimation of all these parameters can be obtained with an iterative process using the maximum likelihood principle.
END NOTE
1 One could question the correctness of using estimated values in the prediction, but we can assume that the estimates of these two weather variables will be in line with the actual unknown values due to little variation from year to year and the strong seasonal pattern.
ADDRESSES FOR CORRESPONDENCE
1 E. Hermans, Transportation Research Institute, Hasselt University, Campus Diepenbeek, Wetenschapspark 5 bus 6, 3590 Diepenbeek, Belgium. E-mail: elke.hermans@uhasselt.be
2 Corresponding author: G. Wets, Transportation Research Institute, Hasselt University, Campus Diepenbeek, Wetenschapspark 5 bus 6, 3590 Diepenbeek, Belgium. E-mail: geert.wets@uhasselt.be
3 F. Van den Bossche, Transportation Research Institute, Hasselt University, Campus Diepenbeek, Wetenschapspark 5 bus 6, 3590 Diepenbeek, Belgium. E-mail: filip.vandenbossche@uhasselt.be
|

