

Biowulf Benchmarks
- NAMD benchmarks (Jan 2009)
- Blast Benchmarks (Dec 2008)
- GROMACS benchmarks (May 2008)
- Amber 10 benchmarks (May 2008)
- WU-Blast benchmarks (Jun 2007)
- Charmm Benchmarks (Apr 2007)
- CNS benchmarks (Aug 2005)
- Sequence Analysis benchmark suite (2006)
CHARMM (c31b2) Benchmarks (Apr 2007)
Model: Myoglobin with CO in a cubic box of 4985 water molecules
Test : dynamics using pme (Particle Mesh Ewald) method, nstep = 2000

| # proc. | Time in minutes | ||||
| p2800,gige 2.8 GHz Xeon, 1Gb/s ethernet |
o2000,gige (2.0 GHz Opteron, 1Gb/s ethernet) |
o2200,gige (2.2 GHz Opteron, 1Gb/s ethernet) |
o2800,gige (2.8 GHz Opteron, 1Gb/s ethernet) |
o2600,gige (2.6 GHz Opteron, dual-core(4p), 1Gb/s ethernet) |
|
| 1 | 38.2 | 35.8 | 32.4 | 26.0 | 27.4 |
| 2 | 21.8 | 35.8 | 32.4 | 13.7 | 14.4 |
| 4 | 26.0 | 15.9 | 15.5 | 13.4 | 21.1 |
CHARMM (c28b3) Benchmarks (7/22/02)
Model: Myoglobin with CO in a cubic box of 4985 water moleculesTest : dynamics using pme (Particle Mesh Ewald) method, nstep = 1000
CHARMM (c28b3) Benchmarks (12/5/01)
Model: Myoglobin with CO in a cubic box of 4985 water moleculesTest : dynamics using pme (Particle Mesh Ewald) method, nstep = 1000
- Myrinet vs. Ethernet
- 2.2-tcpfix vs. 2.4 kernels
- Pentium vs. XP
- Athlon vs XP
- 2.4.12 vs 2.4.18 kernels
Test: QM using GAMESS, nstep = 1
CHARMM MPICH/GM Benchmarks (3/27/01)
These benchmarks are described in /usr/local/src/mpich-1.2..5/examples/perftest- 2 x 866 MHz Pentium III, 256k full speed secondary cache, 512MB memory
- Myricom Myrinet-2000 PCI64B
- RedHat Linux 6.x/2.2.16 kernel
- MPICH-GM 1.2..5
- GM-1.4pre56
| Average latency (uS) |
Average transfer rate (Mbytes/s) |
||
| p2p-short | blocking point-to-point message sizes 0 - 1k bytes |
9.77 | 37.05 |
| p2p-long | blocking point-to-point message sizes 16k - 64k bytes |
118.33 | 193.95 |
| nbpt2pt-long | non-blocking point-to-point message sizes 16k - 64k bytes |
119.06 | 193.44 |
| bisect8-short | bisectional bandwidth message sizes 0 - 1k bytes 8 procs on 8 nodes |
9.77 | 148.47 |
| bisect8-long | bisectional bandwidth message sizes 16k - 64k bytes 8 procs on 8 nodes |
118.32 | 193.96 |
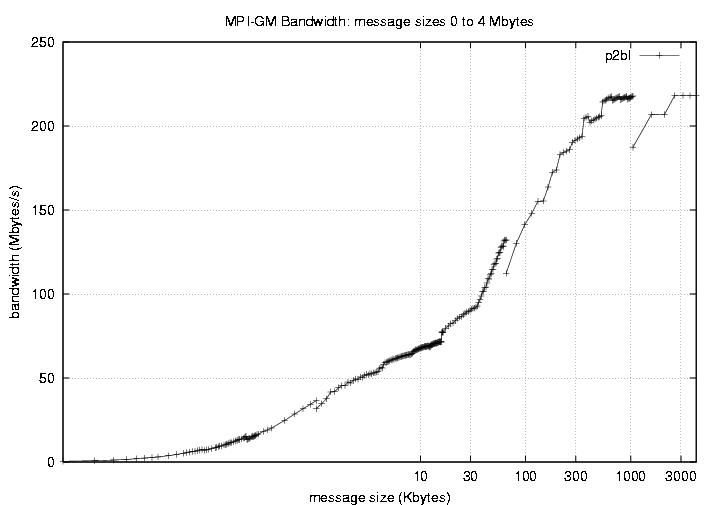
| bw | Blocking bandwidth 0 - 4MBytes | 9.96 | 218.12 |
CHARMM MPICH/GM Benchmarks (3/27/00)
These benchmarks are described in /usr/local/src/mpich-1.1.2..13/examples/perftest.- 2 x 450 MHz Pentium III, 512k secondary caches, 256MB memory
- Myricom Myrinet PCI32C (1MB)
- RedHat Linux 6.x/2.2.13 kernel
- MPICH-GM 1.1.2..13
- GM-1.1.3
| latency (uS) |
transfer rate (Mbytes/s) |
variance in fit |
||
| pt2ptshort | blocking point-to-point message sizes 0 - 1k bytes |
24.55 | 25.29 | 0.000034 |
| pt2ptlong | blocking point-to-point message sizes 16k - 64k bytes |
119.77 | 50.16 | 0.001753 |
| nbpt2ptlong | non-blocking point-to-point message sizes 16k - 64k bytes |
121.85 | 50.03 | 0.001655 |
| bisectshort8 | bisectional bandwidth message sizes 0 - 1k bytes 8 procs on 8 nodes |
24.53 | 25.30 | 0.000034 |
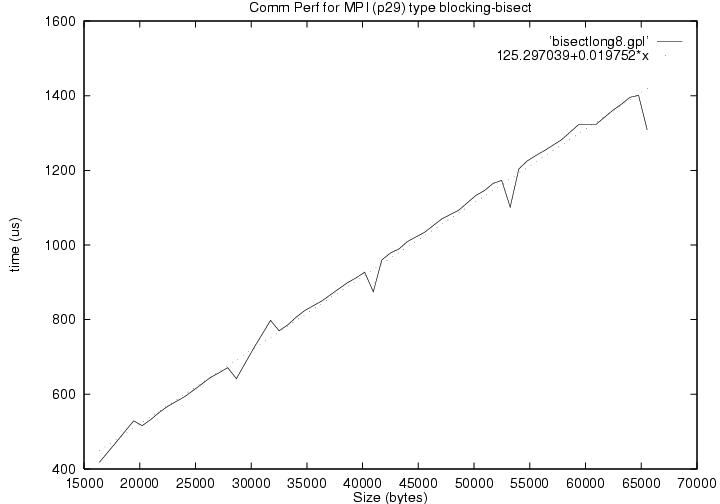
| bisectlong8 | bisectional bandwidth message sizes 16k - 32k bytes 8 procs on 8 nodes |
125.30 | 50.63 | 0.001646 |
CHARMM MPICH/GM Benchmarks (10/20/99)
These benchmarks are described in /usr/local/src/mpich-1.1.2..7/examples/perftest.- 2 x 450 MHz Pentium II, 512k secondary caches, 256MB memory
- Myricom Myrinet PCI32C (1MB)
- RedHat Linux 6.0/2.2.12 kernel
- MPICH-GM 1.1.2..7
- GM-1.086 for Linux-2.2.12smp
| latency (uS) |
transfer rate (Mbytes/s) |
variance in fit |
||
| pt2ptshort | blocking point-to-point message sizes 0 - 1k bytes |
32.05 | 24.47 | 0.000043 |
| pt2ptlong | blocking point-to-point message sizes 16k - 64k bytes |
143.91 | 50.73 | 0.001593 |
| nbpt2ptlong | non-blocking point-to-point message sizes 16k - 64k bytes |
147.85 | 51.02 | 0.001584 |
| bisectshort16 | bisectional bandwidth message sizes 0 - 1k bytes 16 procs on 16 nodes |
32.06 | 24.37 | 0.000043 |
| bisectlong16 | bisectional bandwidth message sizes 16k - 32k bytes 16 procs on 16 nodes |
132.76 | 49.83 | 0.001622 |
| bisectshort32 | bisectional bandwidth message sizes 0 - 1k bytes 32 procs on 16 nodes |
32.06 | 24.37 | 0.000043 |
| bisectlong32 | bisectional bandwidth message sizes 16k - 32k bytes 32 procs on 16 nodes |
142.69 | 50.73 | 0.001593 |
| bandwidth | latency | ||
| blocking | 50.85 Mbytes/s | 32.11 usec | |
| non-blocking | 50.47 Mbytes/s | 33.34 usec |
Benchmarks published by Myricom for 64-bit and 32-bit interfaces.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}