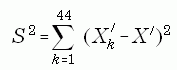
The quality of data collection and processing affects the accuracy of estimates based on a survey. All the statistics published in these tables are estimates of population values. These estimates are based on observations from randomly chosen sample of commercial buildings. As a result, the estimates always differ from the true population values.
Differences that would be expected to occur in all possible samples, or in the average of all estimates from all possible samples, are known as systematic errors, or biases. This appendix describes some of the sources of this nonsampling error in the CBECS, and how the survey was designed and conducted to minimize such errors. Random differences between the survey estimate and the population value, which occur because the particular sample was selected by chance, are known as sampling errors. Although the sampling error is unknown for the particular sample chosen, the sample design permits sampling errors to be estimated. The final section of this appendix, "Computation of Standard Errors," describes how the sampling errors are estimated for the Census Supplement. Estimates of standard errors are shown for all estimates shown in these tables.
Unlike the sampling error, the magnitude of biases cannot be estimated from the sample data. For this reason, avoiding biases is a primary objective of all stages of survey design, data collection, and data processing.
One potential source of bias is inaccuracy in the collection of the data, either because of poorly worded questions, interviewer error or respondent misunderstanding. The section "Data Collection Problems" discusses some of the difficulties encountered in trying to obtain meaningful data on questionnaire items in the 1992 survey.
Another potential source of bias is nonresponse, either for an entire sampled building (unit nonresponse) or for a particular question from a responding building (item nonresponse). Most unit nonresponse cases were caused by a building representative's refusal or unavailability. Item nonresponse resulted when the representative did not know, or, less frequently, refused to give, the answer to a particular question. The sections "Unit Nonresponse Adjustment" and "Census Supplement Nonresponse Adjustment" present in detail the procedures used to handle these two types of nonresponse.
Even though the interviewer was instructed to conduct the interview with the person most knowledgeable about the building, there was a great deal of variation in how much CBECS respondents knew about their buildings. Some respondents did not know some of the information requested and others were able to provide certain information only if the questions were expressed in the particular terms they understood. This presented a special challenge when designing the Construction Improvements and Maintenance and Repairs Supplement questionnaire.
The following is a summary of some difficulties identified with questions used in the tabulations for these tables. The extent of these comments should not be viewed as a failure of the questionnaire or the interview process; the data collection process worked well. Rather, these comments indicate areas that require further refinements to improve overall data quality.
Nearly one-fourth of the respondents did not know the square footage of their buildings. However, less than 3 percent were unable to place the building in a size range. For buildings with the range reported, but not the exact square footage, the range was used as a basis for imputing the exact value. For buildings with no range reported, the imputation was based on other building characteristics, such as the number of workers and building activity, and on rough estimates of building size used to draw the sample (see appendix A). The size ranges are used in the tabulations for these tables.
The principal building activity (PBA) refers to the primary function that takes place in the particular building sampled. In some cases, though, the respondent apparently reported the overall function of the facility or establishment to which the building belonged. For instance, a dormitory is a lodging building, but a dormitory on a university campus may have been reported instead as an educational building (academic or technical institution). Another difficulty with identifying principal activities is that buildings with the same title may, in fact, have different primary functions. For example, space in a courthouse may be devoted primarily to office space or to jail cells (public order and safety). The principal activities of respondent buildings were checked against interviewer observations, and recoded if obvious assignment errors were made. For some buildings, no one activity occupied 50 percent or more of the floorspace, but the activity occupying more space than any other was either industrial or residential. Since more than 50 percent of the floorspace was occupied by commercial activity, these buildings were retained in the sample, but were included in the "Other" category.
The CBECS respondents were asked to report on construction activity intended to improve or maintain the building. The respondent was the building manager or a person knowledgeable about the types of energy used in the building. The respondent was asked to report this information at the end of the CBECS interview or, if a few days were needed to compile the data, the respondent was called back. If the CBECS respondent was not knowledgeable about these expenditures, then the respondent was asked to provide a reference of a knowledgeable person. In situations where tenants occupied space in a building and no one person knew the total amounts, the CBECS respondent was asked to report the amount spent by the owner or provide a reference of someone who could report this expenditure, or to report the amount spent by the tenants.
Total amounts for construction improvements and repairs were asked in two separate but identical batteries of questions. The respondent was asked to report the total amount of each of these for the calendar year 1992 after reviewing cards with definitions of them. The respondents to the Census Supplement were asked the question "Approximately, what is the total amount of money that will be spent in calendar year 1992 by all persons and businesses for ..." This question suggested to the respondent that it would be acceptable to estimate the amount. In fact, since the interviews were conducted before the end of the calendar year 1992 (i.e., August 24 - December 7), estimates were expected. The recall period was unbounded because a previous interview had not been conducted at the beginning of the 1992 calendar year. Unbounded interviews are subject to external telescoping (the tendency of respondents to shift expenditures reports into or out of the recall period) and recall loss (the tendency to omit expenditure reports distant from the date of interview). These data may be subject to these types of response errors. Respondents may underreport expenditures, primarily for smaller jobs, biasing the estimates downward. Converserly, expenditures may in net be telescoped into the unbounded recall period, biasing the estimates upward.
One indication of the degree of estimation is the amount of rounding in
the reported values of the 1,904 nonzero reported expenditures for
improvements and the 4,593 nonzero reported expenditures for repairs.
About 59 percent were reported to only one significant digit and about
29 percent to two significant digits. A number is reported to one
significant digit if only the left most reported digit is nonzero, for
example 200 or 200,000, and a number is reported to two significant
digits if the left two digits are nonzero, for example 230 or 230,000.
Only 4.3 percent of the nonzero reported expenditures for improvements
and 5.8 percent of those for repairs were reported to the dollar and
did not show any rounding. This amount of rounding in the data
indicates that most reported expenditures were estimates. Thus,
estimates in these tables are subject to response errors such as
omission of expenditures due to memory loss, inability to provide a
precise estimate for the remainder of the calendar year, misreporting
of expenditures as being done in 1992, and estimation and rounding
errors in the reported values. See Tables B-1 and B-2 for details.
The response rate for the 1992 CBECS was 91.1 percent. That is, of the 7,282 buildings eligible for interview, 8.9 percent did not respond at all to the Building Questionnaire. This rate was similar to that for the 1989 CBECS, and represents a low unit nonresponse rate for a survey of this length and complexity.
Weight adjustment was the method used to reduce unit nonresponse bias in the survey statistics. The CBECS sample was designed so that survey responses could be used to estimate characteristics of the entire stock of nonresidential buildings in the United States. The method of estimation was to calculate basic sampling weights (base weights) that related the sampled building to the entire stock of nonresidential buildings. In statistical terms, a base weight is the reciprocal of the probability of selecting a building into the sample. A base weight can be understood as the number of actual buildings represented by a sampled building: a sampled building that has a base weight of 1,000 represents itself and 999 similar (but unsampled) buildings in the total stock of buildings.
To reduce the bias for unit response in the survey statistics, the base weights of respondent buildings were adjusted upward, so that the respondent buildings would represent not only unsampled buildings but also nonrespondent buildings. The base weights of respondent buildings were multiplied by the adjustment factor A, defined as
A=W/R,
where W is the sum of the base weights over all buildings selected for the sample, and R is the corresponding sum over all respondent buildings. Respondent weights remained nonzero after weight adjustment. Nonrespondent weights were set to zero because they were accounted for by the upward adjustment of respondent weights.
Unit nonrespondents tended to fall into certain categories. For example, nonresponse tended to be higher in the Northeast than in the Midwest. To reduce nonresponse bias as much as possible, adjustment factors were computed independently within 119 subgroups created by sorting according to characteristics known for both responding and nonresponding buildings from the sampling stage. These characteristics included the general building activity, the rough size of the building, census region, and metropolitan location.
Any respondent who did not have access to the construction improvements data was asked the name, address, and telephone number of the person who would have them. These individuals were later contacted if the building was selected for the subsequent followup study. Before the followup study was conducted, item response on the key item concerning construction improvements was 93.8 percent, or 6,155 of the 6,561 buildings which had completed data for this item.
In the spring of 1993, a three-part followup study for the Census Supplement was conducted with 337 owner and tenant representatives. This followup was done to reduce both total and partial nonresponse to the supplement, as well as to verify independently the data that were obtained during the original interview. The building owners and tenant representatives were first sent a letter explaining the purpose of the survey, along with worksheets and definitions. The respondents were told to use the worksheets to calculate and record the amount of expenditures and to retain the worksheets pending a telephone call from the data collection contractor. Several weeks later, specially trained telephone interviewers called to obtain the data. The overall response rate for the followup was 79.2 percent.
In the first phase of the followup study, "Nonresponse Conversion" buildings were selected. These were buildings that failed to answer one or both questions in the Census Supplement during the building characteristics interview. There were 104 "Nonresponse Conversion" buildings. A total of 75 responses was obtained from the first-phase followup effort.
In the second phase of the followup, cases were selected for item nonresponse of "don't know" to the Census supplement construction improvements question. Cases were included if the respondent provided the name, address, and telephone number of the person or persons who would have the information. These referrals were often to management companies not located in the same city as the sampled buildings. There were a total of 146 item nonresponse buildings; and 120 or 82.2 percent provided additional information.
In the third and final phase of the followup, cases were selected to verify independently the data obtained in the original interview when the reported expenditures for one or both questions were $5 million or more. Packages of materials explaining the verification study and requesting the respondent to provide data on the two types of expenditures were mailed to the original respondents to the Census questions. The respondents were then telephoned to obtain the data. Of the original interviews, a sample of 92 buildings was selected and 76, or 82.6 percent, resubmitted the data.
Nonresponse to the Census Supplement was treated by a technique known as sequential hot-deck imputation. In sequential hot-decking, when a certain response is missing for a given building, another building, called a "donor," is sequentially chosen to furnish its reported value for that item. That value is then assigned to the building with item nonresponse (the nonrespondent or "receiver").
To serve as a donor, a building had to be similar to the nonrespondent in characteristics correlated with the missing item. This procedure was used to reduce the bias caused by different nonresponse rates for a particular item among different types of buildings. What characteristics were used to define "similar" depended on the nature of the item to be imputed. For the Census Supplement, the characteristics were PBA categories and square foot categories. To impute values for a particular item, all buildings were first grouped according to the values of the matching characteristics. Within each group (imputation cell) defined by the matching variables, donor buildings were assigned sequentially to receiver buildings.
The 1992 Census Supplement used a weighted sequential hot-deck procedure (Cox, 1980). With this procedure, sample weights were used in addition to the sequential approach to minimize imputation bias. First the data set was split into respondents and nonrespondents and grouped with respect to the matching variables. The ratio of the sum of respondents' weights to the sum of nonrespondents' weights was computed for each imputation cell. This ratio was used to scale each nonrespondent's weight so that their sum equals that of the respondents. The cumulative sum of the scaled nonrespondent weights was then used to define selection zones from which a donor (respondent) is selected for imputation.
To estimate the component of the variance due to nonresponse, the 1992 Census supplement used a method known as multiple imputation ( Rubin, 1987). For each missing value, 3 independent imputations were made, thus reflecting the range of values that could be obtained. The 3 sets of imputed values were used to create 3 versions of the completed data set for which estimates were calculated. The 3 estimates were then combined, yielding an overall point estimate which is the average of the 3. See Tables B-3 and B-4 for the percentage of cases that had imputed expenditures.
The largest weighted expenditure for repairs was identified as the only extreme value. It was one hundred fifty percent greater than the next largest weighted expenditure. The weighted expenditure for this case was reduced to equal the next largest weighted expenditure by reducing the weight. The extreme value for repairs was for a vacant building with 120,000 square feet, built in 1980-1986 in the West, and had its weighted expenditure reduced from $834 million to $338 million. No extreme values were observed for improvements.
Sampling error, as described in the introduction to this appendix, is the random difference between the survey estimate and the true population value. This difference arises because a random subset, rather than the whole population, is observed. The typical magnitude of the sampling error is measured by the standard error of the estimate. The standard error is the root-mean-square difference between the estimate based on a particular sample and the value that would be obtained by averaging estimates over all possible samples.
If the estimates are unbiased, meaning there is no systematic error, this average over all possible samples is the true population value. In this case, the standard error is simply the root-mean-square difference between the survey estimate and the true population value. If systematic error is present, however, this bias is not included in the error measured by the standard error. Thus, the standard error tends to understate the total estimation error if there are nonnegligible biases.
In principle, sources other than the sampling process can contribute random error to the estimate. Such additional sources of random error include random errors by respondents and by data entry staff, and random unit nonresponse. To recognize these additional sources of variation, the definition of the sampling process can be expanded to include not just the selection of buildings but all steps required to obtain a set of responses. Under this expanded definition, all random errors can be regarded as sampling errors. The procedures designed to estimate the sampling error must, therefore, incorporate all random components of the estimation process.
Throughout these tables, standard errors are given as percents of their estimated values, that is, as relative standard errors (RSE's). Computations of standard errors are more conveniently described, however, in terms of the estimation variance, which is the square of the standard error.
For some types of surveys, a convenient algebraic formula for computing variances can be obtained. However, the CBECS used a list-supplemented, multistage area sample design of such complexity that it is virtually impossible to construct an exact algebraic expression for estimating variances. In particular, convenient formulas based on an assumption of simple random sampling, typical of most standard statistical packages, are entirely inappropriate for the CBECS estimates. Such formulas tend to give severely understated standard errors, making the estimates appear much more accurate than is the case.
The method used to estimate sampling variances for the Census Supplement was a jackknife replication method (National Center for Health Statistics 1966, 1969). The idea behind replication method is to form several pseudoreplicates of the sample by selecting subsets of the full sample. The subsets are selected in such a way that the observed variance of estimates based on the different pseudoreplicates estimates the sampling variance in the overall estimate.
The replication method used begins by pairing first-stage sampling units, such that the two units in each pair represent two independent draws from the same pool of first-stage units, and draws for different pairs are also independent. This pairing of first-stage sampling units must be done in accordance with the way the sampling was actually conducted. For the 1992 Census Supplement, 22 pairs of first-stage sampling units were created in this way. The kth jackknife pseudoreplicate sample set is obtained by deleting all observations from one of the two members in the ith pair, and multiplying the weights on all cases in the other pair member by 2. Observations in all other pairs are unaffected.
The variances are estimated from the pseudoreplicate samples in the
following way. Let X' be a survey estimate (based on the full sample)
of characteristic X for a certain category of buildings. For example, X
may be the expenditure for improvements in office buildings. Let
X'k be the estimate of X based on the kth
pseudoreplicate sample. A biased estimate of the variance of the
full-sample estimate X' is then given by:
This estimate will underestimate the variance because it does not reflect the error due to imputation. To include the imputation component of the variance, estimates and estimates of variances were calculated from the 3 versions of the completed data set. Let X'm and S2m be the estimate and estimate of variance calculated from the mth completed data set, respectively (m=1,2,3). The combined overall estimate of X is obtained as the mean of the sample estimates from the three versions, X", as follows
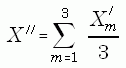
The combined overall variance of X" is estimated as the sum of two components: 1. a within-completed data set component, W', calculated as the mean of the full sample variances,
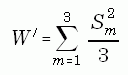
and 2. a between-completed data set component, B', estimated as the variance of the full sample estimates,
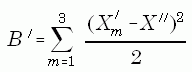
The total variance is given by:
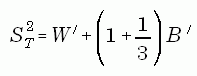
where the factor (1 + 1/3) is an adjustment for the use of a finite number of imputations (Burns, 1991). The standard error of X" is given by:
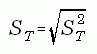
The relative standard error (percent) of X" is obtained from this standard error as:
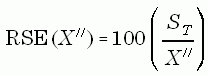
The preceding two sections of this appendix described the procedures used to adjust for unit and item nonresponse. Because the missing cases and the responding cases used to adjust for them arise randomly (within adjustment groups), nonresponse contributes to the estimation variance, even when appropriate adjustment procedures are used to remove the nonresponse bias. Replication- based estimates of variance account for this component of variance only if adjustments are made separately for each replicate.
Since unit nonresponse adjustment factors were not recomputed for each pseudoreplicate sample, the effect of the Census Supplement unit nonresponse is not fully captured in this variance estimator.
The method known as multiple imputation as described above was used to account for the effect of random item nonresponse on the variance of the estimates.
Space limitations prevent publication of the complete set of RSEs for Tables 1 through 5. Instead, a generalized technique is provided by which the reader can compute an approximate RSE for the estimates in these tables. To obtain the relative standard error two steps are required. First, linearly interpolate in Table B-5 to obtain the Base Relative Standard Error. Second, determine the factors in Table B-6 corresponding to the estimate of interest and multiply these factors times the base RSE to obtain the RSE for the estimate. These steps will be illustrated by an example.
Table 4 shows an estimate of $198 million for expenditures for repairs to state and local office buildings with 50,001 to 100,000 square feet in 1992. In Table B-5 the lower bound estimate is $100 million with a 60% RSE and the upper bound estimate is $500 million with a 40% RSE. The formula to obtain the base RSE is:
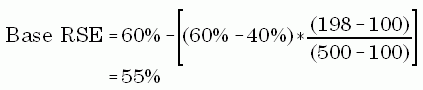
From Table B-6, the factors for this estimate are
Thus the RSE for this estimate is given by:
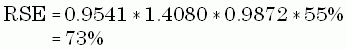
Let X and Y be two different survey estimates and rho the correlation between them and r = 100 * X/(X+Y), the percentage X of the sum. The formula for the relative standard error of the sum X + Y is
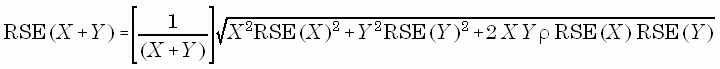
and the formula for the relative standard error of r is
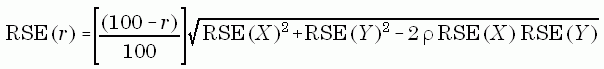
The correlation (rho) between statistics from two different surveys is 0. The correlation between the residential improvements and repairs estimates is .20 and the correlation between nonresidential improvements and repairs estimates is .23.
The sample estimate and an estimate of its standard error
allow us to construct interval estimates with prescribed confidence that the
interval includes the average result of all
possible samples with the same size and design. A 90-percent confidence
interval is defined to be from 1.6 standard errors below the estimate
to 1.6 standard errors above the estimate. If all possible samples were
selected and surveyed under essentially the same conditions and all the
respective 90-percent confidence intervals were generated, then
approximately nine-tenths of the intervals would include the average
value of all sample estimates and approximately one-tenth would not
include this estimate. For example, Table 1 shows that the expenditures
for improvements for private nonresidential buildings in 1992 was
$37.212 billion and the relative error as shown above is 8 percent.
Multiplying $37.212 billion by .08 yields $2.977 billion as the
standard error. To obtain a 90-percent confidence interval, multiply
$2.977 by 1.6 and add and subtract the result from $37.212, yielding
limits of $32.449 billion and $41.975 billion. The average value of the
estimate of 1992 private nonresidential improvements may or may not be
contained in this interval, but one can say that the average is
included in the constructed interval with a specified confidence of 90
percent.
| Number of significant digits |
$10 -99 |
$100 -999 |
$1,000 -9,999 |
$10,000 -99,999 |
$100,000 -999,999 |
$1,000,000 -9,999,999 |
$10,000,000 -99,999,999 |
Total | Percent |
|---|---|---|---|---|---|---|---|---|---|
| Total | 1 | 99 | 510 | 627 | 427 | 216 | 24 | 1904 | 100 |
| Percent | 0.1 | 5.2 | 26.8 | 32.9 | 22.4 | 11.3 | 1.3 | 100 | |
| 1 | 1 | 81 | 332 | 328 | 210 | 108 | 10 | 1070 | 56.2 |
| 2 | - | 14 | 144 | 258 | 129 | 74 | 8 | 627 | 32.9 |
| 3 | 4 | 10 | 20 | 51 | 9 | 3 | 97 | 5.1 | |
| 4 | 24 | 5 | 7 | 10 | 1 | 47 | 2.5 | ||
| 5 | 16 | 6 | 1 | - | 23 | 1.2 | |||
| 6 | 24 | 2 | 1 | 27 | 1.4 | ||||
| 7 | 12 | - | 12 | 0.6 | |||||
| 8 | 1 | 1 | 0.1 |
| Number of significant digits |
$1 -9 |
$10 -99 |
$100 -999 |
$1,000 -9,999 |
$10,000 -99,999 |
$100,000 -999,999 |
$1,000,000 -9,999,999 |
$10,000,000 -99,999,999 |
Total | Percent |
|---|---|---|---|---|---|---|---|---|---|---|
| Total | 1 | 59 | 802 | 1758 | 1230 | 586 | 154 | 3 | 4593 | 100.0 |
| Percent | 0.1 | 1.3 | 17.5 | 38.3 | 26.8 | 12.8 | 3.4 | 0.1 | 100.0 | |
| 1 | 1 | 46 | 652 | 1213 | 573 | 225 | 63 | 1 | 2774 | 60.4 |
| 2 | 13 | 116 | 440 | 461 | 163 | 61 | 1 | 1255 | 27.3 | |
| 3 | 34 | 38 | 85 | 116 | 10 | 1 | 284 | 6.3 | ||
| 4 | 67 | 30 | 16 | 7 | - | 120 | 2.6 | |||
| 5 | 81 | 6 | - | - | 87 | 1.9 | ||||
| 6 | 60 | 1 | - | 61 | 1.3 | |||||
| 7 | 12 | - | 12 | 0.3 |
| Building characteristics | Improvements | Repairs |
|---|---|---|
| All buildings | 3.7 | 10.2 |
| PRINCIPAL ACTIVITY | ||
| Office | 3.9 | 8.0 |
| Mercantile/service (nonfood) | 6.2 | 11.9 |
| Food sales/service | 3.3 | 8.4 |
| Warehouse | 1.2 | 8.3 |
| Religious assembly | 0.5 | 1.7 |
| Educational | 1.2 | 4.1 |
| Health care | 1.9 | 10.9 |
| Lodging | 6.5 | 19.5 |
| Other | 2.1 | 8.0 |
| Vacant | 4.1 | 19.9 |
| YEAR CONSTRUCTED | ||
| 1919 or before | 0.4 | 8.0 |
| 1920 - 1945 | 4.8 | 13.5 |
| 1946 - 1959 | 1.2 | 4.4 |
| 1960 - 1969 | 1.0 | 6.8 |
| 1970 - 1979 | 6.4 | 9.7 |
| 1980 - 1989 | 4.2 | 12.5 |
| 1990 - 1992 | 5.5 | 12.3 |
| Not reported | 13.7 | 27.8 |
| CENSUS REGION | ||
| Northeast | 3.4 | 10.8 |
| Midwest | 4.9 | 8.3 |
| South | 3.9 | 10.3 |
| West | 2.2 | 11.0 |
| BUILDING SIZE | ||
| 1,001 to 10,000 | 1.1 | 8.4 |
| 10,001 to 25,000 | 1.4 | 5.0 |
| 25,001 to 50,000 | 3.3 | 14.2 |
| 50,001 to 100,000 | 4.8 | 9.2 |
| 100,001 to 200,000 | 1.8 | 12.2 |
| 200,001 to 500,000 | 4.0 | 12.3 |
| Over 500,000 | 8.9 | 11.4 |
| Building characteristics | Improvements | Repairs |
|---|---|---|
| All buildings | 5.9 | 21.1 |
| PRINCIPAL ACTIVITY | ||
| Educational | 8.4 | 28.2 |
| Health care | 0.1 | 4.5 |
| Office/professional | 2.4 | 7.7 |
| Public order and safety | 13.8 | 36.0 |
| Other | 3.2 | 5.7 |
| Vacant | 0.0 | 0.0 |
| YEAR CONSTRUCTED | ||
| 1919 or before | 4.1 | 4.2 |
| 1920 - 1945 | 3.8 | 17.9 |
| 1946 - 1959 | 3.3 | 51.9 |
| 1960 - 1969 | 12.1 | 13.3 |
| 1970 - 1979 | 0.5 | 13.0 |
| 1980 - 1989 | 8.7 | 17.1 |
| 1990 - 1992 | 0.0 | 4.2 |
| Not reported | 0.0 | 0.2 |
| CENSUS REGION | ||
| Northeast | 8.9 | 15.5 |
| Midwest | 5.1 | 34.3 |
| South | 7.5 | 11.1 |
| West | 2.7 | 13.3 |
| BUILDING SIZE | ||
| 1,001 to 10,000 | 4.7 | 10.9 |
| 10,001 to 25,000 | 0.6 | 7.0 |
| 25,001 to 50,000 | 0.2 | 13.0 |
| 50,001 to 100,000 | 5.7 | 9.2 |
| 100,001 to 200,000 | 8.7 | 13.0 |
| 200,001 to 500,000 | 11.2 | 40.8 |
| Over 500,000 | 5.2 | 4.3 |
| Expenditure (millions) |
Improvements (percent) |
Repairs (percent) |
|---|---|---|
| 10 | 80 | 107 |
| 50 | 58 | 71 |
| 100 | 51 | 60 |
| 500 | 37 | 40 |
| 1,000 | 32 | 34 |
| 2,500 | 27 | 27 |
| 5,000 | 23 | 23 |
| 10,000 | 20 | 19 |
| 25,000 | 17 | 15 |
| 50,000 | 15 | 13 |
| Characteristics | Improvements | Repairs |
|---|---|---|
| SQUARE FEET | ||
| All buildings | 0.7476 | 0.8958 |
| 1,001 to 10,000 | 0.8426 | 0.7433 |
| 10,001 to 50,000 | 0.9984 | 0.7492 |
| 50,001 to 100,000 | 1.1390 | 0.9541 |
| 100,001 to 200,000 | 1.2693 | 1.2067 |
| 200,001 or more | 0.9520 | 1.1110 |
| TYPE OF BUILDING | ||
| Total nonresidential | 1.0000 | 1.0000 |
| Private | 1.4797 | 1.0117 |
| State and local | 2.1491 | 1.4080 |
| PRINCIPAL ACTIVITY | ||
| All private buildings | 0.7009 | 0.7327 |
| Specified private buildings | 1.0819 | 1.0226 |
| All state and local buildings | 0.8503 | 1.0056 |
| Specified state and local buildings | 0.9693 | 0.9872 |
| REGIONS | ||
| All regions | 0.7792 | 0.8602 |
| Specified regions | 1.0046 | 0.9332 |
| YEAR CONSTRUCTED | ||
| All categories | 1.0000 | 1.0000 |