
SOURCE OF DATA
The data for this microdata file come from the August 2000 Current Population Survey (CPS). The August survey uses two sets of questions, the basic CPS and the supplement.
Basic CPS. The basic CPS collects primarily labor force data about the civilian noninstitutional population. Interviewers ask questions concerning labor force participation about each member 15 years old and over in every sample household.
August 2000 supplement. In August 2000, in addition to the basic CPS, interviewers asked supplementary questions on internet and computer use.
Sample Design. The present CPS sample was selected from the 1990 Decennial Census files with coverage in all 50 states and the District of Columbia. The sample is continually updated to account for new residential construction. To obtain the sample, the United States was divided into 2,007 geographic areas. In most states, a geographic area consisted of a county or several contiguous counties. In some areas of New England and Hawaii, minor civil divisions are used instead of counties. These 2,007 geographic areas were then grouped into 754 strata, and one geographic area was selected from each stratum. About 50,000 occupied households are eligible for interview every month out of these 754 areas. Interviewers are unable to obtain interviews at about 3,200 of these units. This occurs when the occupants are not found at home after repeated calls or are unavailable for some other reason.
Sample Redesign. Since the introduction of the CPS, the Census Bureau has redesigned the CPS sample several times. These redesigns have improved the quality and accuracy of the data and have satisfied changing data needs. The most recent changes were completely implemented in July 1995.
Estimation procedure. This survey's estimation procedure adjusts weighted sample results to agree with independent estimates of the civilian noninstitutional population of the United States by age, sex, race, Hispanic/non-Hispanic origin, and state of residence. This adjustment is called the post-stratification ratio estimate. The independent estimates are calculated based on information from four primary sources:
1) The 1990 Decennial Census of Population and Housing.
2) An adjustment for undercoverage in the 1990 census.
3) Statistics on births, deaths, immigration, and emigration.
4) Statistics on the size of the Armed Forces.
The independent population estimates include some, but not all, undocumented immigrants.
ACCURACY OF THE ESTIMATES
A sample survey estimate has two possible types of error: sampling and nonsampling. The accuracy of an estimate depends on both types of error. The nature of the sampling error is known given the survey design. The full extent of the nonsampling error, however, is unknown.
Sampling error. As with all surveys, CPS estimates come from a sample of the population. Therefore, they can differ from similar figures that could be collected from the whole population (a census). That difference is known as sampling error.
Consequently, one should be particularly careful when interpreting results based on a relatively small number of cases or on small differences between estimates. The standard errors for CPS estimates primarily indicate the magnitude of sampling error. They also partially measure the effect of some nonsampling errors in responses and enumeration, but do not measure systematic biases in the data. (Bias is the average over all possible samples of the differences between the sample estimates and the desired value.)
Nonsampling error. All other sources of error in the survey estimates are collectively called nonsampling error. Sources of nonsampling errors include the following:
1) Inability to get information about all sample cases (nonresponse)
2) Definitional difficulties
3) Differences in the interpretation of questions
4) Respondents' inability or unwillingness to provide correct information
5) Respondents' inability to recall information
6) Errors made in data collection such as recording and coding data
7) Errors made in processing the data
8) Errors made in estimating values for missing data
9) Failure to represent all units with the sample (undercoverage).
Two types of nonsampling error that can be examined to a limited extent are nonresponse and undercoverage.
Nonresponse. The effect of nonresponse cannot be measured directly, but one indication of its potential effect is the nonresponse rate. For the August 2000 basic CPS, the nonresponse rate was 7.04%. The nonresponse rate for the internet and computer use supplement was an additional 6.5%, for a total supplement nonresponse rate of 13.08%.
Undercoverage. The concept of coverage in the survey sampling process is the extent to which the total population that could be selected for sample covers the survey's target population. CPS undercoverage results from missed housing units and missed persons within sample households. Overall CPS undercoverage is estimated to be about 8 percent. CPS undercoverage varies with age, sex, and race. Generally, undercoverage is larger for males than for females and larger for Blacks and other races combined than for Whites. As described previously, ratio estimation to independent age-sex-race-Hispanic population controls partially corrects for bias due to undercoverage. However, biases exist in the estimates to the extent that missed persons in missed households or missed persons in interviewed households have different characteristics from those of interviewed persons in the same age-sex-race-origin-state group.
A common measure of survey coverage is the coverage ratio, the estimated population before post-stratification divided by the independent population control. Table A shows CPS coverage ratios for age-sex-race groups for a typical month. The CPS coverage ratios can exhibit some variability from month to month. Other Census Bureau household surveys experience similar coverage.
|
Table A. CPS Coverage Ratios |
|||||||
|
|
Non-Black |
Black |
All Persons |
||||
|
Age |
M |
F |
M |
F |
M |
F |
Total |
|
0-14 |
0.929 |
0.964 |
0.850 |
0.838 |
0.916 |
0.943 |
0.929 |
|
15 |
0.933 |
0.895 |
0.763 |
0.824 |
0.905 |
0.883 |
0.895 |
|
16-19 |
0.881 |
0.891 |
0.711 |
0.802 |
0.855 |
0.877 |
0.866 |
|
20-29 |
0.847 |
0.897 |
0.660 |
0.811 |
0.823 |
0.884 |
0.854 |
|
30-39 |
0.904 |
0.931 |
0.680 |
0.845 |
0.877 |
0.920 |
0.899 |
|
40-49 |
0.928 |
0.966 |
0.816 |
0.911 |
0.917 |
0.959 |
0.938 |
|
50-59 |
0.953 |
0.974 |
0.896 |
0.927 |
0.948 |
0.969 |
0.959 |
|
60-64 |
0.961 |
0.941 |
0.954 |
0.953 |
0.960 |
0.942 |
0.950 |
|
65-69 |
0.919 |
0.972 |
0.982 |
0.984 |
0.924 |
0.973 |
0.951 |
|
70+ |
0.993 |
1.004 |
0.996 |
0.979 |
0.993 |
1.002 |
0.998 |
|
15+ |
0.914 |
0.945 |
0.767 |
0.874 |
0.898 |
0.927 |
0.918 |
|
0+ |
0.918 |
0.949 |
0.793 |
0.864 |
0.902 |
0.931 |
0.921 |
A nonsampling error warning. Since the full extent of the nonsampling error is unknown, one should be particularly careful when interpreting results based on small differences between estimates. Even a small amount of nonsampling error can cause a borderline difference to appear significant or not, thus distorting a seemingly valid hypothesis test. Caution should also be used when interpreting results based on a relatively small number of cases. Summary measures probably do not reveal useful information when computed on a base smaller than 75,000.
For additional information on nonsampling error including the possible impact on CPS data when known, refer to Statistical Policy Working Paper 3, An Error Profile: Employment as Measured by the Current Population Survey, Office of Federal Statistical Policy and Standards, U.S. Department of Commerce, 1978 and Technical Paper 63, The Current Population Survey: Design and Methodology, Bureau of the Census, U.S. Department of Commerce.
Standard errors and their use. The sample estimate and its standard error enable one to construct a confidence interval. A confidence interval is a range that would include the average result of all possible samples with a known probability. For example, if all possible samples were surveyed under essentially the same general conditions and using the same sample design, and if an estimate and its standard error were calculated from each sample, then approximately 90 percent of the intervals from 1.645 standard errors below the estimate to 1.645 standard errors above the estimate would include the average result of all possible samples.
A particular confidence interval may or may not contain the average estimate derived from all possible samples. However, one can say with specified confidence that the interval includes the average estimate calculated from all possible samples.
Standard errors may also be used to perform hypothesis testing. This is a procedure for distinguishing between population parameters using sample estimates. The most common type of hypothesis is that the population parameters are different. An example of this would be comparing the number of men who were part-tome workers with the number of women who were part-time workers.
Tests may be performed at various levels of significance. A significance level is the probability of concluding that the characteristics are different when, in fact, they are the same. For example, to conclude that two parameters are different at the 0.10 level of significance, the absolute value of the estimated difference between characteristics must be greater than or equal to 1.645 times the standard error of the difference.
The Census Bureau uses 90-percent confidence intervals and 0.10 levels of significance to determine statistical validity. Consult standard statistical textbooks for alternative criteria.
For information on calculating standard errors for labor force data from the CPS which involve quarterly or yearly averages see "Explanatory Notes and Estimates of Error: Household Data" in Employment and Earnings published by the Bureau of Labor Statistics.
Standard errors of estimated numbers. The approximate standard error, sx, of an estimated number from this microdata file can be obtained by using this formula:
![]()
Formula (1)
Here x is the size of the estimate and a and b are the parameters in Tables B or C associated with the particular type of characteristic. When calculating standard errors from cross-tabulations involving different characteristics, use the set of parameters for the characteristic which will give the largest standard error.
Illustration
Suppose there were 2,787,000 unemployed men in the civilian labor force. Use the appropriate parameters from Table B and Formula 1 to get
|
Number, x |
2,787,000 |
|
a parameter |
-0.000018 |
|
b parameter |
2,957 |
|
Standard error |
90,000 |
|
90% conf. int. |
2,639,000 to 2,935,000 |
The standard error is calculated as
![]()
The 90- percent confidence interval is calculated as 2,787,000 ± 1.645 x 90,000.
A conclusion that the average estimate derived from all possible samples lies within a range computed in this way would be correct for roughly 90 percent of all possible samples.
Standard errors of estimated percentages. The reliability of an estimated percentage, computed using sample data for both numerator and denominator, depends on both the size of the percentage and its base. Estimated percentages are relatively more reliable than the corresponding estimates of the numerators of the percentages, particularly if the percentages are 50 percent or more. When the numerator and denominator of the percentage are in different categories, use the parameter from Table B or C indicated by the numerator.
The approximate standard error, sx,p, of an estimated percentage can be obtained by using the formula
![]()
Formula (2)
Here x is the total number of people, families, households, or unrelated individuals in the base of the percentage, p is the percentage (0 £ p £ 100), and b is the parameter in Table B or C associated with the characteristic in the numerator of the percentage.
Illustration
Suppose that of approximately 105,710,000 households, 51.1 percent had a computer in the household. Use the appropriate parameter from Table C and Formula 2 to get
|
Percentage, p |
51.1 |
|
Base, x |
105,710,000 |
|
b parameter |
2,068 |
|
Standard error |
0.22 |
|
90% conf. int. |
50.7 to 51.5 |
The standard error is calculated as
![]()
The 90-percent confidence interval of the percentage of households with computers is calculated as 51.1 ± 1.645 x 0.22
Standard error of a difference. The standard error of the difference between two sample estimates is approximately equal to
![]()
![]()
Formula (3)
where sx and sy are the standard errors of the estimates, x and y. The estimates can be numbers, percentages, ratios, etc. This will represent the actual standard error quite accurately for the difference between estimates of the same characteristic in two different areas, or for the difference between separate and uncorrelated characteristics in the same area. However, if there is a high positive (negative) correlation between the two characteristics, the formula will overestimate (underestimate) the true standard error.
Illustration
Suppose there were 2,148,000 unemployed men 20 years of age or older and 2,539,000 unemployed women 20 years of age or older. Use the appropriate parameters from Table B and Formulas 2 and 3 to get
|
|
x |
y |
difference |
|
Number |
2,148,000 |
2,539,000 |
-391,000 |
|
a parameter |
-.000018 |
-.000018 |
- |
|
b parameter |
2,957 |
2,957 |
- |
|
Standard error |
79,000 |
86,000 |
117,000 |
|
90% conf. int. |
2,018,000 to 2,278,000 |
2,398,000 to 2,680,000 |
-583,000 to -199,000 |
The standard error of the difference is calculated as
![]()
The 90-percent confidence interval around the difference is calculated as -391,000 ± 1.645 x 117,000. Since this interval does not include zero, we can conclude with 90 percent confidence that the number of unemployed men is less than the number of unemployed women.
Accuracy of state estimates. The redesign of the CPS following the 1980 census provided an opportunity to increase efficiency and accuracy of state data. All strata are now defined within state boundaries. The sample is allocated among the states to produce state and national estimates with the required accuracy while keeping total sample size to a minimum. Improved accuracy of state data has been achieved with about the same sample size as in the 1970 design.
Since the CPS is designed to produce both state and national estimates, the proportion of the total population sampled and the sampling rates differ among the states. In general, the smaller the population of the state the larger the sampling proportion. For example, in Vermont approximately 1 in every 400 households was sampled each month. In New York the sample was about 1 in every 2,000 households. Nevertheless, the size of the sample in New York is four times larger than in Vermont because New York has a larger population.
Computation of standard errors for state estimates . Standard errors for a state may be obtained by computing national standard errors, using formulas described earlier, and multiplying these by the appropriate factor, f, from Table D. An alternative method for computing standard errors for a state is to multiply the a and b parameters in Table B or C by f 2 and then use these adjusted parameters in the standard error formulas.
Illustration
Suppose there were 6,988,000 households in New York, 48.8 percent of which had a computer. Use the appropriate parameter from Table C and Formula (2) to get
|
Percentage, p |
48.8 |
|
Base, x |
6,988,000 |
|
b parameter |
2,068 |
|
Standard error |
0.86 |
|
Factor, f |
0.94 |
|
New York standard error |
0.81 |
Thus, the standard error on the estimate of the percentage of households in New York state with a computer is approximately 0.81 = 0.94 x 0.86.
To obtain state parameters, multiply the parameters in Table C by f 2 in Table D for the state of interest. The value of f 2 for New York is 0.89. Thus, for Total or White household characteristics, such as computer ownership, in New York this gives
a = -.000012 x 0.89 = -0.000011 and b = 2,068 x 0.89 = 1,841.
Computation of a factor for groups of states. The factor adjusting standard errors for a group of states may be obtained by computing a weighted sum of the squared factors for the individual states in the group and taking the square root of the result. Depending on the combination of states, the resulting figure can be an overestimate.
The squared factor for a group of n states is given by
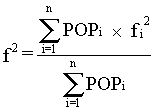
where POPi is the state population and f i5 is obtained from Table D. The 2000 civilian noninstitutionalized population from the CPS for each state is also given in Table D.
Illustration
Suppose a factor for the state group Illinois-Indiana-Michigan was required. The appropriate squared factor would be

Multiply the a and b parameters by f5, 1.06, to obtain parameters for the state group. Alternatively, calculate standard errors with unadjusted parameters and multiply the result by f, 1.03, to get standard errors for this state group.
|
Table B. Parameters for Computation of Standard Errors for Labor Force Characteristics August 2000 |
||
|
Characteristic |
a |
b |
|
Labor Force and Not In Labor Force Data Other than Agricultural Employment and Unemployment Total 1 Men 1 Women Both sexes, 16 to 19 years White 1 Men Women Both sexes, 16 to 19 years Black Men Women Both sexes, 16 to 19 years Hispanic origin |
-0.000018 -0.000033 -0.000030 -0.000172 -0.000020 -0.000037 -0.000034 -0.000204 -0.000125 -0.000302 -0.000183 -0.001295 -0.000206 |
2,985 2,764 2,530 2,545 2,985 2,767 2,527 2,550 3,139 2,931 2,637 2,949 3,896 |
|
Not In Labor Force (use only for Total, Total Men, and White) |
+0.000006 |
829 |
|
Agricultural Employment Total or White Men Women or Both sexes, 16 to 19 years Black Hispanic origin Total or Women Men or Both sexes, 16 to 19 years |
+0.000782 +0.000858 -0.000025
-0.000135
+0.011857 +0.015736 |
3,049 2,825 2,582
3,155
2,895 1,703 |
|
Unemployment Total or White Black Hispanic origin |
-0.000018 -0.000212 -0.000102 |
2,957 3,150 3,576 |
1
For not in labor force characteristics, use the Not In Labor Force parameters.|
Table C. Parameters for Computation of Standard Errors for Internet and Computer Use Estimates August 2000 |
||||||
|
Characteristic |
Total or White |
Black |
Hispanic |
|||
|
a |
b |
a |
b |
a |
b |
|
|
PEOPLE |
|
|
|
|
|
|
|
Educational Attainment |
-0.000011 |
2,369 |
-0.000103 |
2,680 |
-0.000132 |
3,052 |
|
People by Family Income |
-0.000023 |
4,901 |
-0.000217 |
5,611 |
-0.000410 |
9,456 |
|
Income |
-0.000011 |
2,454 |
-0.000109 |
2,810 |
-0.000205 |
4,736 |
|
Marital Status, Household & Family Characteristics |
-0.000019 |
5,211 |
-0.000211 |
7,486 |
-0.000380 |
12,616 |
|
Poverty |
-0.000038 |
10,380 |
-0.000292 |
10,380 |
-0.000527 |
17,493 |
|
FAMILIES, HOUSEHOLDS, OR UNRELATED INDIVIDUALS |
|
|
|
|
|
|
|
Income |
-0.000010 |
2,241 |
-0.000094 |
2,447 |
-0.000179 |
4,124 |
|
Marital Status, Household & Family Characteristics, Educational Attainment, Population by Age or Gender |
-0.000010 |
2,068 |
-0.000072 |
1,871 |
-0.000137 |
3,153 |
|
Poverty |
0.000102 |
2,442 |
0.000102 |
2,442 |
0.000102 |
4,115 |
|
Table D. Factors for State Standard Errors and Parameters and State Populations: 2000 |
|||
|
State |
f |
f2 |
Population |
|
Alabama |
1.00 |
1.01 |
3,409,000 |
|
Alaska |
0.39 |
0.15 |
431,000 |
|
Arizona |
0.98 |
0.97 |
3,619,000 |
|
Arkansas |
0.77 |
0.59 |
1,955,000 |
|
California |
1.14 |
1.29 |
25,355,000 |
|
Colorado |
0.96 |
0.93 |
3,131,000 |
|
Connecticut |
1.00 |
1.00 |
2,498,000 |
|
Delaware |
0.47 |
0.22 |
585,000 |
|
District of Columbia |
0.40 |
0.16 |
417,000 |
|
Florida |
0.98 |
0.97 |
11,913,000 |
|
Georgia |
1.18 |
1.40 |
5,958,000 |
|
Hawaii |
0.59 |
0.35 |
891,000 |
|
Idaho |
0.52 |
0.27 |
956,000 |
|
Illinois |
1.00 |
1.00 |
9,204,000 |
|
Indiana |
1.17 |
1.38 |
4,524,000 |
|
Iowa |
0.84 |
0.71 |
2,195,000 |
|
Kansas |
0.81 |
0.65 |
1,997,000 |
|
Kentucky |
0.96 |
0.92 |
3,084,000 |
|
Louisiana |
0.97 |
0.95 |
3,289,000 |
|
Maine |
0.61 |
0.37 |
995,000 |
|
Maryland |
1.17 |
1.38 |
3,981,000 |
|
Massachusetts |
0.90 |
0.81 |
4,785,000 |
|
Michigan |
0.96 |
0.93 |
7,512,000 |
|
Minnesota |
1.05 |
1.11 |
3,623,000 |
|
Mississippi |
0.80 |
0.64 |
2,091,000 |
|
Missouri |
1.17 |
1.37 |
4,165,000 |
|
Montana |
0.45 |
0.20 |
689,000 |
|
Nebraska |
0.65 |
0.42 |
1,251,000 |
|
Nevada |
0.66 |
0.44 |
1,394,000 |
|
New Hampshire |
0.62 |
0.38 |
929,000 |
|
New Jersey |
0.91 |
0.82 |
6,294,000 |
|
New Mexico |
0.63 |
0.40 |
1,314,000 |
|
New York |
0.94 |
0.89 |
14,165,000 |
|
North Carolina |
0.97 |
0.94 |
5,818,000 |
|
North Dakota |
0.40 |
0.16 |
477,000 |
|
Ohio |
1.01 |
1.02 |
8,610,000 |
|
Oklahoma |
0.85 |
0.73 |
2,542,000 |
|
Oregon |
0.93 |
0.86 |
2,602,000 |
|
Pennsylvania |
0.98 |
0.96 |
9,269,000 |
|
Rhode Island |
0.55 |
0.30 |
749,000 |
|
South Carolina |
1.00 |
1.01 |
3,018,000 |
|
South Dakota |
0.41 |
0.17 |
549,000 |
|
Tennessee |
1.16 |
1.34 |
4,283,000 |
|
Texas |
1.10 |
1.21 |
15,028,000 |
|
Utah |
0.66 |
0.43 |
1,516,000 |
|
Vermont |
0.42 |
0.18 |
470,000 |
|
Virginia |
1.22 |
1.48 |
5,263,000 |
|
Washington |
1.21 |
1.47 |
4,424,000 |
|
West Virginia |
0.62 |
0.39 |
1,447,000 |
|
Wisconsin |
1.11 |
1.23 |
4,018,000 |
|
Wyoming |
0.35 |
0.12 |
369,000 |
NOTE: For foreign-born characteristics for Total and White, the a and b parameters should be multiplied by 1.3. No adjustment is necessary for foreign-born characteristics for Blacks and Hispanics.
 CPS Computer Ownership Supplement - 2000 Internet Methodology and Documentation Page
CPS Computer Ownership Supplement - 2000 Internet Methodology and Documentation Page CPS Main Page
CPS Main Page