Table of Contents
Table 1. CPS Coverage Ratios
Table 2. Parameters for Computation of Standard Errors for Labor Force Characteristics: October 2000
Table 3. Parameters for Computation of Standard Erros for School Enrollment Characteristics: October 2000
Table 4. Factors to Apply to Parameters Other than School Enrollment Prior to 2000
The data in this microdata file come from the October 2000 Current Population Survey (CPS). The Bureau of the Census conducts the survey every month, although this file has only October data. The October survey uses two sets of questions, the basic CPS and the supplement.
Basic CPS The basic CPS collects primarily labor force data about the civilian noninstitutional population. Interviewers ask questions concerning labor force participation about each member fifteen years old and over in every sample household.
Sample Design The present CPS sample was selected from the 1990 Decennial Census files with coverage in all fifty states and the District of Columbia. The sample is continually updated to account for new residential construction. The United States was divided into 2,007 geographic areas. In most states, a geographic area consisted of a county or several contiguous counties. In some areas of New England and Hawaii, minor civil divisions are used instead of counties. A total of 754 geographic areas were selected for sample. About 50,000 occupied households are eligible for interview every month. Interviewers are unable to obtain interviews at about 3,200 of these units. This occurs when the occupants are not found at home after repeated calls or are unavailable for some other reason.
Since the introduction of the CPS, the Bureau of the Census has redesigned the CPS sample several times. These redesigns have improved the quality and accuracy of the data and have satisfied changing data needs. The most recent changes were completely implemented in July 1995.
October Supplement In addition to the basic CPS questions, interviewers asked supplementary questions in October about school enrollment for all household members three years old and over.
Estimation Procedure This survey's estimation procedure adjusts weighted sample results to agree with independent estimates of the civilian noninstitutional population of the United States by age, sex, race, Hispanic/non-Hispanic origin, and state of residence. The adjusted estimate is called the post-stratification ratio estimate. The independent estimates are calculated based on information from four primary sources:
The independent population estimates include some, but not all, undocumented immigrants.
Since the CPS estimates come from a sample, they may differ from figures from a complete census using the same questionnaires, instructions, and enumerators. A sample survey estimate has two possible types of errors: sampling and nonsampling. The accuracy of an estimate depends on both types of errors, but the full extent of the nonsampling error is unknown. Consequently, one should be particularly careful when interpreting results based on a relatively small number of cases or on small differences between estimates. The standard errors for CPS estimates primarily indicate the magnitude of sampling error. They also partially measure the effect of some nonsampling errors in responses and enumeration, but do not measure systematic biases in the data. (Bias is the average over all possible samples of the differences between the sample estimates and the desired value.)
Nonsampling Variability There are several sources of nonsampling errors including the following:
For the October 2000 basic CPS, the nonresponse rate was 6.8% and for the school enrollment supplement the nonresponse rate was an additional 3.1% for a total supplement nonresponse rate of 9.7%.
CPS undercoverage results from missed housing units and missed persons within sample households. Overall CPS undercoverage is estimated to be about 8 percent. CPS undercoverage varies with age, sex, and race. Generally, undercoverage is larger for males than for females and larger for Blacks and other races combined than for Whites. As described previously, ratio estimation to independent age-sex-race-Hispanic population controls partially corrects for the bias due to undercoverage. However, biases exist in the estimates to the extent that missed persons in missed households or missed persons in interviewed households have different characteristics from those of interviewed persons in the same age-sex-race-origin-state group.
A common measure of survey coverage is the coverage ratio, the estimated population before post-stratification divided by the independent population control. Table 1 shows CPS coverage ratios for age-sex-race groups for a typical month. The CPS coverage ratios can exhibit some variability from month to month. Other Census Bureau household surveys experience similar coverage.
| Table 1. CPS Coverage Ratios | |||||||
|---|---|---|---|---|---|---|---|
| Age | Non-Black | Black | All People | ||||
| Male | Female | Male | Female | Male | Female | Total | |
| 0-14 | 0.929 | 0.964 | 0.850 | 0.838 | 0.916 | 0.943 | 0.929 |
| 15 | 0.933 | 0.895 | 0.763 | 0.824 | 0.905 | 0.883 | 0.895 |
| 16-19 | 0.881 | 0.891 | 0.711 | 0.802 | 0.855 | 0.877 | 0.866 |
| 20-29 | 0.847 | 0.897 | 0.660 | 0.811 | 0.823 | 0.884 | 0.854 |
| 30-39 | 0.904 | 0.931 | 0.680 | 0.845 | 0.877 | 0.920 | 0.899 |
| 40-49 | 0.928 | 0.966 | 0.816 | 0.911 | 0.917 | 0.959 | 0.938 |
| 50-59 | 0.953 | 0.974 | 0.896 | 0.927 | 0.948 | 0.969 | 0.959 |
| 60-64 | 0.961 | 0.941 | 0.954 | 0.953 | 0.960 | 0.942 | 0.950 |
| 65-69 | 0.919 | 0.972 | 0.982 | 0.984 | 0.924 | 0.973 | 0.951 |
| 70+ | 0.993 | 1.004 | 0.996 | 0.979 | 0.993 | 1.002 | 0.998 |
| 15+ | 0.914 | 0.945 | 0.767 | 0.874 | 0.898 | 0.927 | 0.918 |
| 0+ | 0.918 | 0.949 | 0.793 | 0.864 | 0.902 | 0.931 | 0.921 |
For additional information on nonsampling error including the possible impact on CPS data when known, refer to Statistical Policy Working Paper 3, An Error Profile: Employment as Measured by the Current Population Survey, Office of Federal Statistical Policy and Standards, U.S. Department of Commerce, 1978 and Technical Paper 63, The Current Population Survey: Design and Methodology, U.S. Census Bureau, U.S. Department of Commerce, 2000.
Comparability of Data Data obtained from the CPS and other sources are not entirely comparable. This results from differences in interviewer training and experience and in differing survey processes. This is an example of nonsampling variability not reflected in the standard errors. Use caution when comparing results from different sources.
A number of changes were made in data collection and estimation procedures beginning with the January 1994 CPS. The major change was the use of a new questionnaire. The questionnaire was redesigned to measure the official labor force concepts more precisely, to expand the amount of data available, to implement several definitional changes, and to adapt to a computer-assisted interviewing environment. The supplemental questions were also modified for adaptation to computer-assisted interviewing, although there were no changes in definitions and concepts. Due to these and other changes, one should use caution when comparing estimates from data collected in 1994 and later years with estimates from earlier years. Caution should also be used when comparing estimates obtained from this microdata file (which reflects 1990 census-based population controls) with estimates from 1993 and earlier years (which reflect 1980 census-based population controls). This change in population controls had relatively little impact on summary measures such as means, medians, and percentage distributions. It did have a significant impact on levels. For example, use of 1990 based population controls results in about a 1-percent increase in the civilian noninstitutional population and in the number of families and households. Thus, estimates of levels for data collected in 1994 and later years will differ from those for earlier years by more than what could be attributed to actual changes in the population. These differences could be disproportionately greater for certain subpopulation groups than for the total population.
Since no independent population control totals for persons of Hispanic origin were used before 1985, compare Hispanic estimates over time cautiously.
Based on the results of each decennial census, the Bureau of the Census gradually introduces a new sample design for the CPS. During this phase-in period, CPS data are collected from sample designs based on different censuses. While most CPS estimates have been unaffected by this mixed sample, geographic estimates are subject to greater error and variability. Users should exercise caution when comparing estimates across years for metropolitan/ nonmetropolitan categories.
Note When Using Small Estimates Because of the large standard errors involved, summary measures (such as medians and percentage distributions) would probably not reveal useful information when computed on a smaller base than 75,000.
Take care in the interpretation of small differences. For instance, even a small amount of nonsampling error can cause a borderline difference to appear significant or not, thus distorting a seemingly valid hypothesis test.
Sampling Variability Sampling variability is variation that occurred by chance because a sample was surveyed rather than the entire population. Standard errors, as calculated by methods described later in "Standard Errors and Their Use," are primarily measures of sampling variability, although they may include some nonsampling error.
Standard Errors and Their Use A number of approximations are required to derive, at a moderate cost, standard errors applicable to all the estimates in this microdata file. Instead of providing an individual standard error for each estimate, parameters are provided to calculate standard errors for various types of characteristics. These parameters are listed in Tables 2 and 3. Also, tables are provided that allow the calculation of parameters for prior years and parameters for U.S. regions. Tables 4 and 4A provide factors to derive prior year parameters; Table 5 provides factors to derive U.S. regional parameters.
The sample estimate and its standard error enable one to construct a confidence interval, a range that would include the average result of all possible samples with a known probability. For example, if all possible samples were surveyed under essentially the same general conditions and using the same sample design, and if an estimate and its standard error were calculated from each sample, then approximately 90 percent of the intervals from 1.645 standard errors below the estimate to 1.645 standard errors above the estimate would include the average result of all possible samples.
A particular confidence interval may or may not contain the average estimate derived from all possible samples. However, one can say with specified confidence that the interval includes the average estimate calculated from all possible samples.
Standard errors may also be used to perform hypothesis testing, a procedure for distinguishing between population parameters using sample estimates. One common type of hypothesis is that the population parameters are different. An example of this would be comparing the percentage of employed males 20 to 24 years old working part time to the percentage of employed females in the same age group who were part-time workers. An illustration of this is included in the following pages.
Tests may be performed at various levels of significance. A significance level is the probability of concluding that the characteristics are different when, in fact, they are the same. To conclude that two parameters are different at the 0.10 level of significance, the absolute value of the estimated difference between characteristics must be greater than or equal to 1.645 times the standard error of the difference.
The Census Bureau uses 90-percent confidence intervals and 0.10 levels of significance to determine statistical validity. Consult standard statistical textbooks for alternative criteria.
Standard Errors of Estimated Numbers The approximate standard error, sx, of an estimated number, with the exception of school enrollment estimates, from this microdata file can be obtained using the following formula:
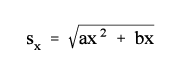 |
(1) |
Here x is the size of the estimate and a and b are the parameters in Table 2 associated with the particular type of characteristic. When calculating standard errors from cross-tabulations involving different characteristics, use the set of parameters for the characteristic which will give the largest standard error.
Illustration
In October 2000, there were 2,800,000 unemployed men in the civilian labor force. Use the appropriate parameters from Table 2 and formula (1) to get the following:
| Number, x | 2,800,000 |
| a parameter | -0.000018 |
| b parameter | 2,957 |
| Standard error | 90,214 |
| 90% conf. int. | 2,650,000 to 2,950,000 |
The standard error is calculated as follows:
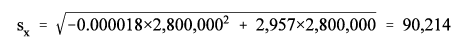
The 90-percent confidence interval is calculated as 2,800,000 ± 1.645 90,214.
A conclusion that the average estimate derived from all possible samples lies within a range computed in this way would be correct for roughly 90 percent of all possible samples.
Standard Errors of Estimated School Enrollment Numbers The approximate standard error, sx, of an estimated school enrollment number from this microdata file can be obtained using the following formula:
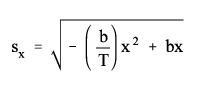 |
(2) |
Here x is the size of the estimate, T is the total number of persons in a specific age group and b is the parameter in Table 3 associated with the particular type of characteristic. If T is not known, for Total or White use 100,000,000; for Blacks and Hispanic use 10,000,000. When calculating standard errors for numbers from cross-tabulations involving different characteristics, use the set of parameters for the characteristic which will give the largest standard error.
Illustration
There were 4,100,000 three and four year olds enrolled in school and 7,870,000 children in that age group in October 2000. Use the appropriate b parameter from Table 3 and formula (2) to get the following:
| Number, x | 4,100,000 |
| Total, T | 7,870,000 |
| b parameter | 2,727 |
| Standard error | 73,184 |
| 90% conf. int. | 3,980,000 to 4,220,000 |
The standard error is calculated as follows:

The 90-percent confidence interval for this estimate is approximately 3,980,000 to 4,220,000 (i.e., 4,100,000 + 1.645 73,184). Therefore, a conclusion that the average estimate derived from all possible samples lies within a range computed in this way would be correct for roughly 90 percent of all possible samples.
Standard Errors of Estimated Percentages The reliability of an estimated percentage, computed using sample data for both numerator and denominator, depends on the size of the percentage and its base. Estimated percentages are relatively more reliable than the corresponding estimates of the numerators of the percentages, particularly if the percentages are 50 percent or more. When the numerator and denominator of the percentage are in different categories, use the parameter from Table 2 or 3 indicated by the numerator.
The approximate standard error, sx,p, of an estimated percentage can be obtained by use of the following formula:
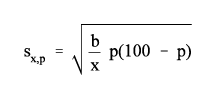 |
(3) |
Here x is the total number of persons, families, households, or unrelated individuals in the base of the percentage, p is the percentage (0 ≤ p ≤ 100), and b is the parameter in Table 2 or 3 associated with the characteristic in the numerator of the percentage.
Illustration
In October 2000, there were 15,550,000 persons aged 18 to 21, and 44.0 percent were enrolled in college. Use the appropriate parameter from Table 3 and formula (3) to get the following:
| Percentage, p | 43.5 |
| Base, x | 15,550,000 |
| b parameter | 2,369 |
| Standard error | 0.6 |
| 90% conf. int. | 42.5 to 44.5 |
The standard error is calculated as follows:
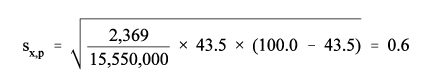
The 90-percent confidence interval for the estimated percentage of persons aged 18 to 21 in October 2000 enrolled in college is from 42.5 to 44.5 percent (i.e., 43.5 + 1.645 0.6).
Standard Error of a Difference The standard error of the difference between two sample estimates is approximately equal to the following:
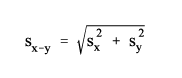 |
(4) |
where sx and sy are the standard errors of the estimates, x and y. The estimates can be numbers, percentages, ratios, etc. This will result in accurate estimates of the standard error of the same characteristic in two different areas, or for the difference between separate and uncorrelated characteristics in the same area. However, if there is a high positive (negative) correlation between the two characteristics, the formula will overestimate (underestimate) the true standard error.
Illustration
Suppose that of the 7,150,000 employed men between 20-24 years of age in October 2000, 20.8 percent were part-time workers, and of the 6,450,000 employed women between 20-24 years of age, 33.2 percent were part-time workers. Use the appropriate parameters from Table 2 and formulas (3) and (4) to get the following:
| x | y | difference | |
| Percentage, p | 20.8 | 33.2 | 12.4 |
| Number, x | 7,150,000 | 6,450,000 | - |
| b parameter | 2,764 | 2,530 | - |
| Standard error | 0.8 | 0.9 | 1.2 |
| 90% conf. int. | 19.5 to 22.1 | 31.7 to 34.7 | 10.4 to 14.4 |
The standard error of the difference is calculated as follows:
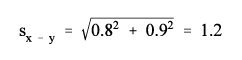
The 90-percent confidence interval around the difference is calculated as 12.4 ≤ 1.645 1.2. Since this interval does not include zero, we can conclude with 90 percent confidence that the percentage of part-time women workers between 20-24 years of age is greater than the percentage of part-time men workers between 20-24 years of age.
| Table 2. Parameters for Computation of Standard Errors for Labor Force Characteristics: October 2000 |
||
|---|---|---|
| Characteristic | a | b |
| Civilian Labor Force, Employed, and Not in Labor Force |
||
| Total or White | -0.000008 | 1,586 |
| Men | -0.000035 | 2,927 |
| Women | -0.000033 | 2,693 |
| Both sexes, 16 to 19 years | -0.000244 | 3,005 |
| Black | -0.000154 | 3,296 |
| Men | -0.000336 | 3,332 |
| Women | -0.000282 | 2,944 |
| Both sexes, 16 to 19 years | -0.001531 | 3,296 |
| Hispanic ancestry | -0.000187 | 3,296 |
| Men | -0.000363 | 3,332 |
| Women | -0.000380 | 2,944 |
| Both sexes, 16 to 19 years | -0.001822 | 3,296 |
| Unemployment | ||
| Total or White | -0.000017 | 3,005 |
| Men | -0.000035 | 2,927 |
| Women | -0.000033 | 2,693 |
| Both sexes, 16 to 19 years | -0.000244 | 3,005 |
| Black | -0.000154 | 3,296 |
| Men | -0.000336 | 3,332 |
| Women | -0.000282 | 2,944 |
| Both sexes, 16 to 19 years | -0.001531 | 3,296 |
| Hispanic ancestry | -0.000187 | 3,296 |
| Men | -0.000363 | 3,332 |
| Women | -0.000380 | 2,944 |
| Both sexes, 16 to 19 years | -0.001822 | 3,296 |
| Agricultural Employment | 0.001345 | 2,989 |
| Notes: | These parameters are to be applied to basic CPS monthly labor force estimates. For foreign-born and noncitizen characteristics for Total and White, the a and b parameters should be multiplied by 1.3. No adjustment is necessary for foreign-born and noncitizen characteristics for Blacks and Hispanics. |
| Table 3. Parameters for Computation of Standard Errors for School Enrollment Characteristics: October 2000 |
|||
|---|---|---|---|
| Characteristics | Total or White b |
Black b |
Hispanic b |
| People | |||
| Persons Enrolled in School: | |||
| Total | 2,369 | 2,680 | 3,051 |
| Children 13 and under | 2,727 | 3,085 | 3,512 |
| Marital Status, Household and Family Characteristics, Health Insurance |
|||
| Some household members | 5,211 | 7,486 | 12,616 |
| All household members | 6,332 | 11,039 | 18,604 |
| Families, Households, or Unrelated Individuals | |||
| Income, Earnings | 2,241 | 2,447 | 4,124 |
| Marital Status, Household and Family Characteristics, Educational Attainment, Population by Age and/or Sex |
2,068 | 1,871 | 3,153 |
| Notes: | The b parameters should be multiplied by 1.5 for nonmetropolitan residence categories. The b parameters should be multiplied by the factors in Table 5 for regional data. |
Recently, we produced updated March 1994 educational attainment parameters directly from the March 1994 data. Using the updated March 1994 educational attainment parameters as a base, we also updated the October 1995-2000 school enrollment parameters.
Table 4 shows the prior year factors to apply to parameters Other than School Enrollment while
Table 4A shows prior year factors to apply to School Enrollment parameters.
| Table 4. Factors to Apply to Parameters Other than School Enrollment Prior to 2000 |
|||
|---|---|---|---|
| Year | Total or White | Black | Hispanic |
| 1996-1999 | 1.00 | 1.00 | 1.00 |
| 1994-1995 | 0.93 | 0.93 | 0.92 |
| 1990-1993 | 0.92 | 0.92 | 0.82 |
| 1988-1989 | 1.02 | 1.01 | 1.07 |
| 1985-1987 | 0.83 | 0.83 | 0.77 |
| 1982-1984 | 0.83 | 0.83 | 0.64 |
| 1977-1981 | 0.75 | 0.75 | 0.56 |
| 1967-1976 | 0.73 | 0.73 | 0.55 |
| 1957-1966 | 1.12 | 1.12 | X |
| Before 1956 | 1.67 | 1.67 | X |
| (X) Not applicable |
| Note: Apply the appropriate factor to the b parameter for estimates Other than Persons Enrolled in School for October 2000. |
| Table 4A. Factors to Apply to Parameters for School Enrollment Prior to 2000 |
|||
|---|---|---|---|
| Year | Total or White | Black | Hispanic |
| 1996-1999 | 1.00 | 1.00 | 1.00 |
| 1994-1995 | 0.92 | 0.92 | 0.92 |
| 1990-1993 | 1.07 | 1.28 | 1.89 |
| 1988-1989 | 1.15 | 1.38 | 2.46 |
| 1985-1987 | 0.97 | 1.16 | 1.76 |
| 1982-1984 | 0.97 | 1.16 | 1.46 |
| 1977-1981 | 0.88 | 1.05 | 1.29 |
| 1967-1976 | 0.86 | 1.02 | 1.27 |
| 1957-1966 | 1.30 | 1.56 | X |
| Before 1956 | 1.96 | 2.34 | X |
| (X) Not Applicable |
| Note: Apply the appropriate factor to the School Enrollment b parameter for October 2000. |
Table 5 provides the U.S. regional factors to apply to parameters in order to calculate standard errors for U.S. regional estimates.
| Table 5. Regional Factors to Apply to 2000 Parameters |
|||
|---|---|---|---|
| Type of Characteristic | factor | ||
| U. S. Totals: | 1.00 | ||
| Regions: | |||
| Northeast | 0.85 | ||
| Midwest | 1.03 | ||
| South | 1.08 | ||
| West | 1.09 | ||