Estimating Commodity Inflows to a Substate Region Using Input-Output Data: Commodity Flow Survey Accuracy Tests
Louie Nan Liu*
Zhejiang University
Pierre Vilain*
The Louis Berger Group
ABSTRACT
This paper describes a methodology to estimate current U.S. commodity inflows to a substate region using a supply-side, commodity-by-industry, input-output model and commodity flow data for U.S. states. Because the 1993 Commodity Flow Survey does not capture data below the state level, the estimation of commodity flows to a particular substate region of the United States has always proven difficult. By combining state-level commodity flow data with the supply-side, commodity-by-industry, input-output model, an estimate of commodity flows to smaller regions can be carried out entirely based on the regional industrial structure. Since the actual substate flows are typically unobserved, the accuracy of the methodology is unknown. However, by applying the same methodology to larger regions, with actual states used as the forecast region, the estimates can be compared with actual flows while maintaining an acceptable level of accuracy.
INTRODUCTION
A typical problem faced by transportation planners is being able to anticipate the need for expanded or new transportation infrastructure, facilities, or services. Estimates of freight flows between regions can provide much-needed information for decisionmaking. In the United States, estimates of freight flows exist between individual states,1 but little data exist for flows between areas below the state level, which we refer to as substate regions. Estimates of freight flows between substate regions could be generated based on costly direct surveys or by using secondary sources of data to infer patterns based on characteristics of the areas in question (Holguín-Veras 2000; Ortúzar and Willumsen 1994). The approach described here falls into the second category, deriving estimated freight flows from secondary data on the region's industrial structure. As these data are often readily and cheaply available (e.g., in the United States down to the county level), this approach is both simple and cost-effective.
In general, the process of estimating freight
outflows from substate regions is fairly simple. Relatively accurate estimates can be produced based on data on the region's industrial structure and its state-to-state trade. By mechanically assigning freight commodity exports to the producing industries, estimates can be made of the share of a substate region's state exports based on the presence of these industries.
However, the estimation of the second category, freight inflows
, is considerably more complicated. While we can roughly assign the production of commodities to certain industries, the consumption of commodities by various industries requires far more detailed knowledge of their input use. Fortunately, this type of information is readily available in input-output models, and some simple manipulations of standard input-output data yield a tool that can then be used to assign state-level commodity inflows to any substate region.
In the following sections we outline a methodology to estimate commodity inflows to smaller regions, which was initially described in Vilain et al. (1999). The methodology was devised specifically to regionalize inflows to substate regions in the United States, but it has also been used in other countries. In general, the methodology can be used in any country or region, given the availability of the requisite data on input-output accounts described below.
Having proposed a methodology to estimate freight inflows that is simple to use, it is of interest to examine the accuracy of the technique. In this paper, we carry out a series of simulations that we then test for their predictive accuracy. The key to being able to determine the accuracy of simulations is to carry them out for states as if they were smaller substate regions. Since states are regions for which commodity flow data does exist, we can then compare the predicted inflows with the actual observed inflows. Our results show that, excluding inflows of mining, petroleum, or coal products, the methodology leads to relatively accurate forecasts. Total inflows of all commodities to a state are typically predicted within 10% error, but the accuracy of forecasts for individual commodities is far more variable. Despite the mixed results, we argue that the methodology described here is valid, yielding predictions of commodity inflows that have an acceptable level of accuracy. The relative accuracy of the methodology must also be considered keeping in mind that, in the absence of expensive origin-destination surveys, there are really no alternatives that yield reliable estimates of commodity inflows.
SUPPLY-SIDE INPUT-OUTPUT MODEL AND COMMODITY FORECASTING
The gravity model is a widely used technique for estimating commodity inflows to a region. In this approach, observed freight flows between areas are encouraged by demand factors (e.g., concentrations of population) and accessibility, while transportation costs between regions act to inhibit such flows. Gravity models have been applied extensively to the analysis of passenger trip generation, and examples exist of their application to freight demand modeling (Ortúzar and Willumsen 1994). In terms of our problem of predicting commodity inflows to a substate area, this model could be estimated at the state level and the estimated parameters used to predict inflows to a substate region. However, data requirements to calibrate such a model (notably transportation costs) are significant. This same conclusion applies to other, closely related models based on discrete choice analysis, including disaggregated freight generation models.
We propose an alternative approach here, one that bases estimates of actual commodity inflows to a substate region entirely on the region's industrial structure. The details of the industrial structure are themselves obtained from regional input-output data. The procedure can be carried out fairly easily, relying entirely on published national input-output data, existing state-level commodity flow data from the 1993 Commodity Flow Survey (USDOC 1993), and regional data on employment or earnings by industry.
The procedure involves two steps. First, using regional input-output data (USDOC 1997), we define the proportion of commodities used by various industries in a region of interest. Then we apply these proportions to existing state-level commodity inflow data from the 1993 Commodity Flow Survey to share down the state-level flows to the region. One significant advantage of the methodology is that it takes into account the possibility that the input needs of a regional industry are met, in whole or in part, by regional suppliers. By accounting for existing patterns of regional inter-industry freight flows, the accuracy of estimated regional freight inflows is presumably increased greatly.2
The procedure can be represented schematically. In essence, data on commodity inflows to a region (e.g., a state) are divided into the various industries (including households) that are the likely users of these commodities as inputs. Once the inflows have been divided among the various inflow-consuming industries, they are then disaggregated to the appropriate substate regions based on their industrial structure. Let us suppose there are three industries and two substate regions, called I and II. This would then produce an assignment of commodity inflows that would follow the pattern shown in figure 1.
To describe the supply-side, commodity-by-industry model, consider a set of accounts that details the sales of each commodity to the various industries that use it as inputs in production as well as sales of that commodity to final demand. (Details on the input-output accounts we describe are contained in the literature; see, e.g., Miller and Blair 1985.) For each of the commodities consumed in the economy we can write the following equation:
qi = ui1 + ui2 + ... + uin + ei (1)
Equation (1) defines an identity, namely that the total production of commodity i is equal to the sales of that commodity to each of the n industries in the economy (e.g., ui2 is sales of commodity i to Industry 2) and commodity sales to final demand, ei. In input-output accounts, final demand is consumption by households and governments as well as investment expenditures and the difference between imports and exports.
If there are m commodities being produced and consumed in the economy, we can represent all sales of commodities to industries as a matrix of dimensions m x n:
U = [ uij ] (2)
U is composed of commodity sales to industries, with each uij representing the amount of commodity i (expressed in monetary units) used by industry j as an input in its production. In other words, each of the m rows of U details the total industrial destinations of each of the m commodities represented in the accounts.
We then transform U into a matrix β whose elements are those in U divided by their row sum. Formally, this is defined as
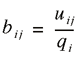 (3) (3)
where bij is equal to the share of commodity i sold to industry j. In matrix terms, the derivation of β is obtained with the following simple operation:
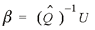 (4) (4)
where Q is an m by 1 vector of all commodity gross outputs as individually defined in equation (1), and ^ indicates a diagonalized matrix.
By dividing row elements by their total production for industrial or final demand uses, we obtain the commodity-by-industry equivalent of the "supply-side" input-output model (Augustinovics 1970). With each bij element of β representing the share of commodity i sold to industry j, the information in β will allow us to disaggregate state-level commodity inflows to the appropriate industries that use the commodities as inputs. Several further steps are required to do so.
The matrix β, which is a matrix representing national data, must be regionalized to the state level. In order to share commodity inflows to the regional level, a procedure based on location quotients is used.3 We define a simple state-level location quotient as the relative representation of a national commodity-producing industry in a particular state s:
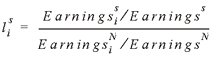 (5) (5)
Earningsi is earnings in the industry that produce commodity i in either state s (indicated by a superscript s) or in the nation (superscript N). Earningss is total regional earnings and EarningsN is total national earnings. Note that the location quotient could also be based on employment data.
Location quotients are calculated for each of the n industries producing the m commodities in β. These are then used to regionalize the elements of β. Generating a vector of n state-level location quotients for state s, Ls, the following multiplication is carried out:
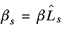 (6) (6)
where ^ again indicates the diagonalized matrix formed from the vector Ls. Each element of βs adjusts the national values of β downward if the state contains a presence of the industry that is less than the national average. Specifically, each element of βs is equal to
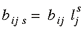 (7) (7)
A final adjustment is then carried out. The row sums of βs (as opposed to each bij s element of βs) should then be adjusted to equal 1. The reason for this is simple. Because the matrix will be used to apportion freight flows to different industries, we are interested in the relative values of the elements of βs rather than their absolute values. To ensure that row sums equal 1, we carry out a balancing procedure:
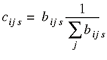 (8) (8)
This balancing procedure now ensures that the row sums of a new matrix, Cs, sum to 1. This procedure is necessary in order to ensure that all commodity inflows to state s can be assigned an end user. It essentially reflects the following assumption: if an industry, say industry j, is not present in state s, the inflows of any commodity that it uses as an input are simply assumed to be used by other industries that are both present in the state and use the commodity as an input.
This same procedure is also carried out if industry j is present in the state but its presence is below the national average; whatever inputs are not used by industry j are simply allocated to all the other industries that use the commodity and are present in state s.
Each cij s element of matrix Csnow can be said to approximate the proportion of commodity i that is shipped to state s that will be used by industry j. In other words, Cs directs the commodities entering state s to the industries that can be expected to use the commodities as inputs. Mathematically, the operation involves a simple post-multiplication of the state-level commodity inflows by Cs, resulting in a disaggregation of these inflows into the industries that use them as inputs. If we define the vector φs that contains the inflows of the m commodity to state s, we perform the following matrix multiplication:
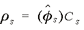 (9) (9)
Again, ^ indicates the vector φs is converted to a diagonalized matrix. The operation produces the matrix ρs of dimension m x n, which apportions freight inflows among the state industries that will use them as inputs. Specifically, each ρij s element of matrix ρs details the amount of commodity i flowing to industry j in state s.
To further regionalize these flows to the substate level, another procedure needs to be carried out. In a manner similar to the previous regionalization, we calculate a matrix of regional earnings shares, Lregion, which measures the relative representation of each industry in the substate region. Multiplying ρs by a matrix produced from diagonalizing the vector Lregion produces the matrix ρreg.
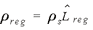
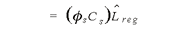 (10) (10)
Each ρij reg element of the matrix ρreg gives an approximation of the amount of a commodity shipped to state sthat is used by a regional industry.4 The state-level commodity inflows are, thus, directed to a substate region, depending on the location of industries using the commodities as inputs. Any row sum of ρreg gives an estimate of the total amount of a given commodity that is shipped to the region. The resulting vector of estimated regional inflows is denoted as φreg and the total inflow of any given commodity as φi reg.
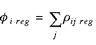 (11) (11)
An important assumption embodied in the use of ρreg is that each regional industry that uses a given commodity as an input will use it in the same proportions as the industry nationally. In other words, it is assumed that local industries use commodity inputs in relation to the relative proportions in β, a standard assumption when regionalizing national input-output flows with location quotients.
Another assumption implicit in the methodology is that all firms purchase locally produced commodity inputs in the same proportions. For example, if commodity i is produced in the state and satisfies 10% of local state needs, it is assumed that all firms that use commodity i will purchase 10 of their input needs locally. This assumption can presumably create bias in estimates of regional inflows. To the degree that the local production of i is concentrated in certain substate regions, some local industries might purchase more than 10% of their needs from the local state suppliers. Finally, in addition to assuming that all firms purchase locally produced inputs in the same proportions, the methodology further assumes that industries purchase their extra-regional inputs from any given region in the same proportion.
ACCURACY TESTS
Having described a relatively simple methodology to estimate freight inflows to a substate region, we want to determine its accuracy. As mentioned previously, the approach suggested here is intended for estimates of freight flows to substate regions where, by definition, little or no data exist to permit validation of the estimates. This would imply that validating the results of the methodology would require actual survey data on freight inflows to the region. The lack of such surveys for small regions is precisely what motivated the elaboration of the supply-side, commodity-by-industry methodology.5
An alternative approach to determining the accuracy of the methodology is possible, however. This involves treating states as if they were substate regions and creating larger regions comprised of a series of individual states. Then, the total freight inflows to these several states can be used as if they were inflows to an individual state. In so doing, one must be careful to remove the freight flows between the various states that make up the larger region. The result is data detailing all inflows of commodities to the larger region from outside this region.
It should be pointed out that the Commodity Flow Survey is comprehensive in that all modes are covered. For the 1993 Commodity Flow Survey, the U.S. Census Bureau used a sample of 200,000 establishments in manufacturing, mining, wholesale, and retail.6 Each establishment was asked to report shipments for two-week periods in each of the four calendar quarters identifying domestic origin and destination, commodity type, weight, value, and mode of transport. The Commodity Flow Survey does exclude certain commodities, notably crude petroleum. Also, while imports and exports are included, commodities shipped from a foreign location through the United States to another destination are excluded.
In carrying out our tests, we selected four large regions in the United States that each contain a number of states. The regions are as follows:
- Northeast Region: Connecticut, Maine, Massachusetts, New Hampshire, Rhode Island, and Vermont;
- Middle Atlantic Region: Delaware, Maryland, New Jersey, New York, and Pennsylvania;
- Great Lakes Region: Illinois, Indiana, Michigan, Ohio, and Wisconsin; and
- West Coast Region: California, Nevada, Washington, Oregon, Alaska, and Hawaii.
We applied the procedure to seven states: Massachusetts, New York, Pennsylvania, Ohio, Illinois, California, and Washington.
For each of these four regions, we estimated a measure equivalent to ρs for the entire group of component states, as defined in equation (9). For the purposes of this analysis, the seven states we analyzed were treated as if they were substate regions. For each of these states, both ρreg and φreg were calculated according to the definitions of equations (10) and (11), as if the detailed state-level data in the Commodity Flow Survey did not exist.
How do these estimates compare with actual freight inflows to the states? Details of the estimates and the actual observed inflows for each of the seven states are reported in appendix tables A1, A2, A3, A4, A5, A6, and A7, along with the percentage error of the forecasts. In general, the methodology performs well for total forecasts of different commodities, but the forecast of specific commodities is variable. Total commodity inflows to a state are forecast within 10% accuracy for all states except California and Ohio. For example, in the case of Massachusetts, the forecast error for total commodity inflows is 9.6% below the actual observed inflow. This figure, however, obscures the fact that while some commodities are forecast with less than 5% error, others are forecast with as much as 56% error (e.g., transportation equipment). This is due to the fact that a simple summation of the percentage error of individual commodities will see negative and positive forecast errors canceling each other.
Two commodities, mineral products and petroleum and coal products, tended to predict very poorly (in the case of New York, e.g., the forecast was off by over 800%) and were not included in tables A2 through A7. This can be partly explained by the different patterns of energy consumption in various regions of the United States. In particular, the use of such energy sources as oil, coal, hydroelectric, and nuclear power can vary across regions regardless of industries.7 Because of the consistently large error in predicting these commodities, we do not include them in our discussion and note that our methodology is inappropriate to forecast them.
In general, simply averaging the percentage error of individual commodities will be a poor measure of overall accuracy that will tend to overstate the accuracy of the methodology. Because individual commodities will generate both negative and positive forecast error, these will tend to cancel each other in a simple averaging over the sample. To account for the presence of both negative and positive forecast error, we relied on weighted average error (WAE) and mean absolute error (MAE). The definitions of the measures for the m commodities are:
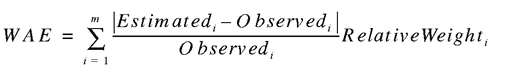
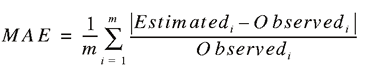
Tables A1 through A7 report these measures. The WAE ranged from 16.8% to 29.1%, depending on the state. The MAE ranged from 15.6% to 71%, with the latter a relatively extreme result for the state of Washington and uncharacteristic of the sample.
The tables include a measure of the relative distance the commodity is being shipped (distance ratio) derived from data in the Commodity Flow Survey. The measure relates the average shipping distance for a commodity to a state relative to the average shipping distance for that commodity nationally. In other words, if commodity i when shipped to Massachusetts travels an average of 500 miles and the national average for the commodity is 250 miles, the distance ratio will be equal to 2.
One reason for measuring the distance ratio is that geography may well play a role in the export activity of firms. Specifically, as mentioned earlier, we assumed by necessity that firms all purchase locally produced commodity inputs in the same proportions. But geography may encourage different patterns of local versus nonlocal sales: if the transportation costs to the next largest concentrations of potential purchasers are great, firms may be particularly oriented to their local market. If the costs to potential nonlocal purchasers are not high, firms may be shipping outside the immediate region to a greater degree.
A cursory glance at the results in tables A6 and A7 suggests that states with larger distance ratios, in this case California and Washington, tend to have greater commodity forecast errors. In order to test for the effect of distance on shipments, and potentially on the accuracy of our method, we included distance ratio in a simple regression that measured the explanatory power of this variable on the accuracy of forecasts. In essence, we wanted to find out if a large deviation of the distance ratio from one is associated with an increased forecast error.8
Similarly, we were also interested in the effect of commodity volume on forecast accuracy. If the actual volume of a specific commodity shipped to a particular state is low, will this lower the forecast accuracy? We tested for both effects in a multivariate regression where observed tonnage shipped and distance ratio by commodity were regressed on the forecast error of the particular commodity. Table 1 presents the results of this regression. While the coefficients show the expected signs, both are only significant at the 15% confidence level. We interpreted this result to mean that there is no significant inherent bias in the forecast method due to the distance of shipments or the actual tonnage of commodities shipped.9
CONCLUSIONS
The procedure described above offers a relatively easy tool to estimate substate commodity inflows, one that can be used by transportation planners for relatively accurate "back of the envelope" predictions of aggregate commodity inflows to smaller regions. Further, the procedure has the important advantage of using the appropriate observed state-level commodity inflows as a starting point to estimate substate flows, something that cannot be claimed by econometric or gravity models that generalize inflow patterns observed in one region to another region. Though somewhat laborious, the calculations are relatively simple, using data that are widely available and low cost, at least in the United States and European Union countries.
While estimates of total freight inflows were in some cases surprisingly accurate, the estimate errors of individual commodities were often significantly greater. In particular, commodities, such as energy inputs, whose use could vary significantly across regions in the United States, were predicted very poorly. Excluding these commodities, the MAE for all commodities to all states is 31% while the corresponding WAE is 21%, arguably acceptable imprecision for the suggested uses of the approach.
As discussed, the method entails two crucial assumptions. First, all firms at the state and regional level are assumed to display the same input use as their counterparts nationally, a necessary assumption in nonsurvey regional input-output modeling. This assumption appears to be a significant flaw in the estimate of inflows of energy inputs, as mentioned. Second, all firms in a regional industry are assumed to purchase locally produced commodity inputs in the same proportions. This could introduce bias, particularly in the case of large states where firms located near a local supplier of a given commodity could consume significantly more inputs produced locally than those located farther away from the supplier.
Our method cannot differentiate these differences among firms in the same industry. This could in turn lead to overestimates of inflows of a given commodity to regions with an important local producer of that commodity. Conversely, it could also lead to underestimates of inflows to the other regions. As opposed to gravity models, for example, our approach does not incorporate distance as a potential influence on trade flows. The econometric analyses reported in tables 1 and 2 indicate distance may affect our model's accuracy, although the significance of this bias appears modest in our accuracy tests.
Despite this imperfection, it is argued that the method of estimating substate inflows using input-output data is sound. We further argue that, in the absence of detailed and costly surveys, our approach estimates the most elusive component of regional trade, commodity inflows, with acceptable levels of accuracy.
REFERENCES
Augustinovics, M. 1970. Methods of International and Intertemporal Comparisons of Structure. Contributions to Input-Output Analysis. Edited by A.P. Carter and A. Brody. Amsterdam, The Netherlands: North Holland.
Holguín-Veras, J. 2000. A Framework for an Integrative Freight Market Simulation, paper presented at the IEEE/ITSC Conference, Dearborn, MI. October.
Memmott, F.W. 1983. Application of Statewide Freight Demand Forecasting Techniques, National Cooperative Highway Research Program Report 260. Washington, DC: Transportation Research Board and National Research Council.
Miller, R.E. and P. D. Blair. 1985. Input-Output Analysis: Foundations and Extensions. Englewood Cliffs, NJ: Prentice-Hall.
Ortúzar, J.D. and L.G. Willumsen. 1994. Modelling Transport. Chichester, England: John Wiley & Sons.
U.S. Department of Commerce (USDOC), Census Bureau. 1993. 1993 Commodity Flow Survey, CD-CFS-93-1. Washington, DC. December.
_____. Bureau of Economic Analysis. 1997. Input-Output Accounts of the US Economy, 1992 Benchmark. Washington, DC. November.
Vilain, P., L.N. Liu, and D. Aimen. 1999. Estimation of Commodity Inflows to a Substate Region: An Input-Output Based Approach. Transportation Research Record 1653. Washington, DC: Transportation Research Board and National Research Council.
ADDRESS FOR CORRESPONDANCE AND END NOTES
Authors' Addresses:
Corresponding Author: Pierre Vilain, The Louis Berger Group, 199 Water Street, New York, NY 10038. Email: pvilain@louisberger.com
Louie Nan Liu, College of Management,
Zhejiang University,
Hangzhou 310027,
People's Republic of China. Email: nliu@mail.hz.zj.cn
KEYWORDS: Estimating commodity flows, freight planning, input-output model applications.
1. The U.S. Department of Commerce's 1993 Commodity Flow Survey contains state-level data on commodity flows.
2. This aspect of the methodology contrasts with the approach suggested by Memmott (1983). While also based on input-output models, his suggested procedure for estimating regional freight flows does not account for the possibility of freight inflows being supplied regionally. As a result, the applicability of the approach for accurately estimating inflows from outside the region is limited.
3. Location quotients are widely used as a method of regionalizing national data, in particular input-output data. The measure indicates the relative concentration of an industry in a region, where values for equation (5) that are larger than 1 indicate a greater than average concentration and values less than 1 the opposite.
4. Note that because Lreg contains simple regional shares of an industry, no balancing procedure is required. Our procedure differs from previous regionalizations in that we have already apportioned commodities to industries in state s and only need to share the flows between regions in the state based on the presence of the industry.
5. An exception is the for-fee Transearch® freight data provided by Reebie Associates for the United States (available at www.reebie.com, as of Sept. 27, 2004). Future research could carry out accuracy tests based on this data.
6. We rely on the older 1993 Commodity Flow Survey rather than the more recent 1997 Commodity Flow Survey, because the sample size was twice as large in the earlier survey, which we believe increases its reliability.
7. The bias of assuming national patterns of energy use or production to regions has been discussed by other authors, in particular Miller and Blair (1985) wrote: "Electricity produced in Eastern Washington by water power (Coulee Dam) represents quite a different mix of inputs from electricity that is produced from coal in the greater Philadelphia area or by means of nuclear power elsewhere." They allude to a problem inherent in using national input-output data regionalized on the basis of nonsurvey techniques. This issue also affects the procedure we have suggested for estimating commodity flows. Because the methodology presented here relies on national input-output data, it will tend to assume that energy sources reflect the national "average."
8. We thank an anonymous referee for suggesting a test for the effect of distance on forecast accuracy. Note that the Commodity Flow Survey does not allow us to calculate distance ratios for all commodities forecast, as distance estimates are not always reported for all commodities shipped to all states.
9. It should be pointed out that the relatively aggregated commodity classifications dealt with here result in very few commodity shipments of small tonnage. Forecast error may be significantly related to commodity tonnage below certain thresholds. We also regressed the forecast error for a commodity on a variable that represents the importance of that commodity in total inflows to the state. The results, in table 2, are again of the expected sign, with the relative importance of a commodity as a percentage of shipments reducing error.
|

