Borderplex Bridge and Air Econometric Forecast Accuracy
Thomas M. Fullerton, Jr.
Department of Economics & Finance
University of Texas at El Paso,
El Paso, TX 79968-0543
Email: tomf@utep.edu
ABSTRACT
El Paso, Texas, and Ciudad Juárez, Mexico, jointly comprise a large cross-border metropolitan economy. El Paso is an important port-of-entry for international cargo, as well as a key transit point for regional trade flows in the southwestern United States. Reflective of those traits, the borderplex econometric forecasting system includes two blocks of transportation equations. One subsystem models northbound surface traffic across the international bridges from Ciudad Juárez. The other deals with passenger, cargo, and mail flows at El Paso International Airport. To gauge model reliability, an analysis of borderplex transportation variable forecast accuracy relative to a random walk benchmark is completed. Empirical evidence is mixed with respect to model precision for the 1998 to 2003 sample period for which data are currently available.
INTRODUCTION
Given the historical importance of regional and international trade flows through El Paso, Texas, transportation variables have formed part of the borderplex econometric model from its inception in 1997. Currently comprising 218 individual equations, two sets of transportation equations are included in the borderplex model (Fullerton 2001). One block of transportation equations is for northbound traffic categories on the international bridges connecting El Paso with Ciudad Juárez, Mexico. Another subsystem models passenger, cargo, and mail flows at El Paso International Airport.
Fullerton and Tinajero (2003) and others generated short-term cyclical forecasts of borderplex business and economic conditions using the model from 1998 forward. The three-year out-of-sample forecast period for transportation variables is included in these publications. For some other variables, the effective simulation period is longer due to lags in data collection and dissemination. When missing values for the last historical period of any series occur, a model simulation provides estimates of the missing observations. Data release delays occasionally contribute to that circumstance. To date, formal prediction accuracy assessments have not been conducted for the transportation variables included in the border region system of simultaneous equations.
This paper first examines the accuracy of the borderplex transportation variable forecasts published for 1998 through 2003. Predictive accuracy is assessed relative to a random walk benchmark. Subsequent sections of the paper include discussions of regional econometric forecasting research, borderplex model attributes, and an empirical analysis of transportation forecast accuracy between 1998 and 2003. A summary and suggestions for future research are provided in the conclusion.
REGIONAL AND BORDER ECONOMETRIC FORECASTING RESEARCH
Structural model forecasting analysis for regional and national economies can be traced back to 1936 (Dhane and Barten 1989). Overall design flexibility makes it a widely used tool for corporate planning efforts and public policy analysis. Structural models have been applied to a wide variety of regional and metropolitan economies in the United States, Europe, and Asia (Klein 1969; Bolton 1985; Kim 1995; Hunt and Snell 1997). Since 1997, one such model has been utilized to simulate economic and business conditions in the cross-border regional economy comprised by El Paso, Texas; Las Cruces, New Mexico; Ciudad Juárez, Mexico; and Ciudad Chihuahua, Mexico (Fullerton 2001).
Several authors have suggested that out-of-sample forecasting accuracy and simulation analyses can be important tools for assessing econometric model reliability (Leamer 1983; West 1995; Granger 1996; McCloskey and Ziliak 1996). Out-of-sample forecasts are model simulations that go beyond the end of the sample period for which historical data are available. A growing number of studies have used these forecasts for the regional class of structural equation models (West and Fullerton 1996; Fullerton and West 1998; Fullerton et al. 2000; Lenze 2000; Fullerton et al. 2001; West 2003). Those studies indicate that regional forecasts for many variables, such as employment, income, and population, are relatively accurate. However, the track records for regional housing activity are less successful.
Infrastructure planning has long required systematic forecasting efforts for transportation systems. Numerous methodologies have been examined over the years (Schneider 1975; Beenstock and Vergottis 1989; Matthews 1995; Caves 1997; Dennis 2002). However, to date, relatively few regional transportation forecasting programs have been examined for historical accuracy. This gap in the literature is partially addressed in this paper by examining the accuracy of borderplex air and bridge traffic forecasts published between 1998 and 2003.
Figure 1 depicts the basic strategy deployed in the borderplex system of simultaneous equations. In addition to being affected by national economic trends in the United States, El Paso feels the effects of the national business cycle fluctuations in Mexico, as well as regional business cycles in Ciudad Juárez. The reverse circumstance also holds true for Ciudad Juárez. Consequently, individual equation specifications in the model may contain national macroeconomic, domestic regional, international macroeconomic, and/or cross-border metropolitan variables (Fullerton 2001).
Recent economic history along the Mexican border in Texas succinctly reflects the attributes shown in figure 1. The "Tequila Effect" peso devaluation of December 1994 precipitated a severe loss in Mexican consumer purchasing power that led to a decline in international bridge crossings and a reduction in retail sales in El Paso (Fullerton 1998; Fullerton 2000). Macroeconomic shocks on the north side of the border also affect the local economy. The 2001 U.S. recession hurt manufacturing plants throughout the borderplex. In response to that, plus a changed inspection environment subsequent to September 11, 2001, cargo vehicle traffic from Mexico sagged (Fullerton and Tinajero 2002).
The borderplex model is used for a variety of purposes, with the most important being regional business trend monitoring and econometric forecasting analysis. While there are a small number of commercially available forecasts for El Paso County (Leppold 2002; Shankar 2003), those efforts generally ignore cross-border business conditions and omit transportation flows. The model is also used in a variety of public policy analysis exercises, such as the provision of simulation data utilized in testimony provided to Texas State Senate committees regarding local income trends and North American Free Trade Agreement (NAFTA) adjustment efforts. Local governmental units and public utilities have engaged a series of annual contracts with the University of Texas at El Paso Border Region Modeling Project for special simulation exercises designed to assist infrastructure planning efforts. Access to comprehensive forecasts involving both sides of the border using a common set of exogenous variable assumptions are critical to those endeavors.
To accomplish the model's goals, sectoral coverage is necessarily broad. Twelve separate equation blocks are utilized: demographics, employment, personal income, labor earnings, disaggregated retail sales, residential real estate, nonresidential construction, maquiladora activity, northbound international border crossings, air transportation, water consumption, and regional bankruptcy trends. The structure of the model contains numerous direct and indirect feedback loops connecting the various equation blocks (Fullerton 2001). Because annual data are used, lag structures are fairly short in all of the different blocks. They are confirmed every year via goodness-of-fit tests.
The 218 equations in the current version of the border forecasting system offer at least partial detail for each of the 12 blocks of endogenous equations.1 The 218 equations contain 40 identities and 178 stochastic equations. Over the years, some equation specifications have remained unchanged, while multiple variations have been tested for others. Specification updates occur due to new data acquisitions, alternative possibilities identified in the literature, and/or as a consequence of previous relationships not performing well following the annual data bank updates and parameter re-estimation exercises. Heightened security inspection efforts and post-9/11 travel disruptions also caused equation modifications in both 2002 and 2003. Of the 178 fitted results ultimately selected every year, most exhibit good statistical traits, but nearly all contain at least partial design and/or empirical flaws.
Of the 178 regression equations, 51 required serial correlation correction techniques. Three categories of data generating processes can be seen in the affected residual series: 18 autoregressive, 28 moving average, and 5 mixed autoregressive-moving average sets of parameters. Given the variety of autocorrelation processes involved, parameter estimation was accomplished using a nonlinear ARMAX procedure (Pagan 1974). That more than one-fourth of all the border model stochastic specifications required serial correlation correction in part reflects widespread data constraints that have long affected regional econometric modeling efforts. Unavailable data series occasionally prevent some systematic variation in dependent variables from being handled as satisfactorily as they can be in macroeconometric models (Fullerton and West 1998). As with national econometric models, persistence effects probably also contribute to the prevalence autocorrelation in borderplex equation residuals (Fair 1984; Campbell and Mankiw 1987).
Table 1 lists and describes the variables included in the transportation blocks of the border model and empirical summaries for all of the air and bridge equation parameter estimates. Table 2, which reports Border Region Modeling Project historical data used to estimate those blocks of equations, can be accessed via the University of Texas at El Paso College of Business Administration website (www.utep.edu). The statistical diagnostics for these two groups of equations worsened notably once 2001 observations were included in the historical sample set in 2002. That circumstance continued in 2003 even after 2002 data became available. Most notably, the 18 stochastic equations include 22 separate slope coefficients that fail to satisfy the 5 percent significance criterion. This development is most likely temporary and is expected to fade eventually as the aftermath of the post-September 11, 2001, air travel and border disruptions dissipates.
Multi-equation regional econometric forecasting systems usually omit air transportation activities. The borderplex model partially overcomes this customary gap with a 12-equation subsystem encompassing air passenger, freight, and mail flows through the El Paso International Airport. Domestic passenger arrivals and departures are modeled as functions of metropolitan real wage and salary disbursements and a real price variable for air travel (Howry 1969). International passenger traffic flows are dependent on the inflation-adjusted value of the peso and the relative price index for air transportation (González and Moral 1995). Equations 1 through 12 in table 2 show that a combination of national and border region variables are used to model both freight and airmail shipments and deliveries.
International bridge traffic from Mexico is modeled with a block of 11 equations, 8 of which are stochastic. Coverage in this portion of the model is confined to northbound border commuting across the three bridges within the El Paso city limits and excludes other regional crossings data as a consequence of time series information constraints. Merchandise trade statistics for El Paso extend back only to 1993, precluding the estimation of trade flow equations that might otherwise be of interest to policy analysts and corporate planners. Three categories of traffic flows are included in the current version of the border model: pedestrians, personal automobiles, and cargo vehicles. More than 9 million pedestrians, 11 million light vehicles, and 700,000 cargo vehicles crossed the border using these arteries in 2001 (Fullerton and Tinajero 2003). Not surprisingly, a mixture of national and international exogenous variables, plus border region endogenous data, is used in the specifications shown in equations 13 through 23 in table 2 (Sawyer and Sprinkle 1986; Cobb et al. 1989; Fullerton 2001).
In addition to the transportation endogenous variables that are analyzed for historical predictive accuracy, air travel and air mail price indices are also included in the borderplex model. Similar to other equations in the transportation blocks of the model, their respective empirical traits continued to be acceptable in both 2002 and 2003. Curiously, however, the estimated parameter for the autoregressive lag of the mail price index is not statistically significant. Given the nature of postal service price increases, the partial adjustment specification is probably correct. Prior to 2003, it obtained better estimation results for the lagged dependent variable regression coefficient.
HISTORICAL ACCURACY ASSESSMENT: 1998–2003
The preceding section provides descriptive insights with respect to the overall structure of the borderplex model. It does not shed any light on its general forecast reliability for the transportation equations. To examine this question, a straightforward accuracy assessment was devised along the regional modeling guidelines proposed by West (1995). Historically, extrapolations from univariate ARIMA equations are regarded as the most reliable benchmarks against which structural model performance should be measured (Granger 1996). Because annual data are used in the border model, small sample sizes preclude estimating ARIMA equations.
To circumvent that obstacle, random walk projections were used to provide the backdrop against which a comparison can be made with the previously published structural model forecasts. Figures 2 and 3 illustrate the variable growth rates observed for many borderplex transportation series. Given that variability, the random walks utilized only the last historical observation available for each variable. While apparently simple, this type of benchmark has proven surprisingly effective in other regional forecasting contexts where sawtooth growth patterns occur (Fullerton et al. 2001). The 1998 to 2003 outlook publications allow assembling the original data for each dependent variable, thus avoiding the common problem of inadvertently handicapping the structural simulations when revised data must be used to generate the random walk forecasts (West and Fullerton 1996).
Using borderplex model data for 1998 to 2003, three-year forecasts are shown for selected transportation variables (see table 3). The forecasts are ex ante dynamic simulations and do not employ historical data for the right-hand-side variables. National consultant service subscriptions provide forecast data for U.S. and Mexico macroeconomic variables used as exogenous regressors (Alemán 2003; Behravesh et al. 2003; Zandi 2003). For the 1998 to 2003 sample period, this allows 15 observations to be assembled for each of the air and bridge dependent variables of interest.
The previously published forecasts for each transportation variable are compared with random walk benchmarks. As shown for four representative variables in table 3, both sets of three-year forecasts are listed in order of publication. Accordingly, prediction data for 1998, 1999, and 2000 are followed by similar numbers for 1999, 2000, and 2001, next, and so forth. For the last two sets of previously published forecasts, only two and one historical data points are currently available for accuracy comparisons. Accuracy measures applied to the data include root mean square error statistics (RMSEs) and Theil inequality coefficients, also known as U-statistics (Pindyck and Rubinfeld 1998). U-statistics can take values between 0 and 1. A value of 0 indicates a perfect fit. For the covariance proportions of the prediction error second moments, the optimal values are 0, 0, and 1. See the appendix for specific information on the calculation of those measures.
Table 4 summarizes predictive accuracy results for air passenger traffic, air freight, and airmail flows in and out of El Paso International Airport. Passenger traffic variables analyzed for out-of-sample forecast precision include inbound passengers from domestic flights, inbound passengers from international flights, outbound passengers to domestic destinations, and outbound passengers to international destinations. The other stochastic equation series examined include inbound freight, outbound freight, inbound mail, and outbound mail.
In table 4, the first row for each variable contains the structural model predictive summary statistics and the second row reports the same estimates for the random walk extrapolations. With the exception of the airmail series, U-statistics close to 0 are obtained for both sets of airport activity forecasts. Examination of the second moment prediction error proportions reveals that the passenger variable structural model forecasts tend to be biased, but the same problem afflicts the random walk counterparts for those series. Similar to the regional housing starts results obtained for Florida (Fullerton and West 1998; Fullerton et al. 2000), the borderplex model passenger forecasts obtain higher U-statistic values than do their respective random walk alternatives.
In contrast, the structural model air cargo and airmail variables also analyzed in table 4 obtain U-coefficients that are lower than those of their respective random walk counterparts. Those outcomes are more in line with regional results previously obtained for variables such as employment, population, or personal income (West and Fullerton 1996; Lenze 2000). Interestingly, the distributions of the inequality coefficient second moment proportions (U-bias, U-variance, and U-covariance) are much closer to the optimum 0, 0, 1 distribution for the nonpassenger variables. However, those improvements are observed for the structural model and the random walk data.
Table 5 reports the accuracy estimates for the international bridge data included as part of the borderplex modeling system. For the eight series modeled, results point to superior accuracy by the random walk benchmarks in only two cases. Both of those cases, however, involve cargo vehicle traffic, an increasingly important traffic category as trade liberalization occurs under the auspices of NAFTA (Orrenius et al. 2001; Fullerton and Tinajero 2002). Table 5 indicates that bias is a problem for both sets of cargo vehicle structural forecasts. Additional testing is obviously warranted for the specifications associated with both of the bridge cargo econometric specifications.
Results shown in table 5 for pedestrian and personal vehicle traffic flows from Ciudad Juárez to El Paso all point to relatively better simulation precision by the econometric model. Those outcomes are encouraging, because both categories influence retail sales performance in El Paso in noticeable ways and represent key indicators for the regional economy (Fullerton 2001). Personal vehicles are also important in terms of emissions impacts on the environment (Roderick 1993; Funk et al. 2001). As with earlier documented regional employment and income results (West and Fullerton 1996; Fullerton et al. 2004), outcomes shown in table 5 indicate that borderplex model forecasts of automobile and pedestrian categories of northbound bridge traffic are accurate relative to random walk benchmarks. These results are encouraging, because simulations from the model are being used in transportation planning exercises conducted by the El Paso Metropolitan Planning Organization. The presence of bias in two of the pedestrian and two of the automobile sets of forecasts indicates, however, that even these equations experience simulation flaws.
Due to the small numbers of similar studies for regional transportation forecasting efforts and for other border economies, it is hard to assess whether the outcomes shown in tables 4 and 5 are unique to the borderplex economy. Given their relatively high U-coefficients, caution should be exercised with respect to using the out-of-sample air passenger and bridge cargo forecasts published using the borderplex model. At a minimum, subscribers and other users should use the latest available historical observations as "sanity checks" for those extrapolations (Fullerton and West 1998). Although the random walk approach using the latest historical observations has been presented here as a competitive benchmark, practice has shown that the information content of random walk forecasts frequently complements that contained in structural model counterparts (Granger 1996). Over time, it will become possible to assess whether structural model simulation reliability improves for these variable categories.
CONCLUSION
Transportation variables have formed integral components of the borderplex econometric forecasting effort from its inception in 1997. Included among the 218 equations in the border model are 2 blocks of transportation equations. The latter cover international bridge crossings from Ciudad Juárez as well as air traffic activity at El Paso International Airport. To examine out-of-sample forecast reliability, extrapolation accuracy is examined for those variables between 1998 and 2003.
Results indicate that the air freight, airmail, bridge auto, and bridge pedestrian series forecasts are somewhat more accurate than random walk benchmarks over the course of the sample period. Outcomes for the air passenger and bridge cargo simulations are less encouraging. In each of those cases, the random walk benchmarks obtain lower root mean square error statistics and Theil inequality coefficients. Care should be exercised when assessing the usefulness of forecasts for those variables. Future forecasts for those variables should probably be compared with the last available historical observations. That step can potentially help ensure that the model simulations do not stray too far what might be reasonably expected during multi-step prediction periods.
Border region econometric forecasting analysis is still a relatively new endeavor. As additional outlooks are published, greater numbers of observations will eventually permit more formal testing to be engaged. The sample used here is also geographically limited in scope. Replication for other border areas such as San Diego-Tijuana and Laredo-Nuevo Laredo would be helpful. Should similar efforts be carried out for other international metropolitan economies, evidence obtained for the borderplex indicates that transportation forecasting accuracy can be achieved in some cases. Because accuracy relative to random walk benchmarks is not achieved for all of the variables examined, evidence from other regions will help document whether that is a problem specific to the borderplex or one that is general in nature.
ACKNOWLEDGMENTS
Partial funding support for this research was provided by El Paso Electric Company, El Paso Metropolitan Planning Organization, Wells Fargo Bank of El Paso, National Science Foundation Grant SES-0332001, and the University of Texas at El Paso College of Business Administration. Helpful comments were provided by Peg Young, Keith Ord, Roberto Tinajero, Marsha Fenn, and three anonymous referees. Econometric research assistance was provided by Armando Aguilar and Brian Kelley.
REFERENCES
Alemán, E. 2003. Síntesis. Global Insight Perspectivas Económicas de México. Marzo:1.1–1.10.
Beenstock, M. and A. Vergottis. 1989. An Econometric Model of the World Market for Dry Cargo Freight and Shipping. Applied Economics 21:339–356.
Behravesh, N., A. Hodge, and C. Latta. 2003. So Far, So Good. Global Insight U.S. Economic Outlook April:1–14.
Bolton, R. 1985. Regional Econometric Models. Journal of Regional Science 25:130–165.
Campbell, J.Y. and N.G. Mankiw. 1987. Permanent and Transitory Components in Macroeconomic Fluctuations. American Economic Review Papers and Proceedings 77:111–117.
Caves, R.E. 1997. European Airline Networks and Their Implications for Airport Planning. Transport Reviews 17:121–144.
Cobb, S.L., D.J. Molina, and K. Sokulsky. 1989. The Impact of Maquiladoras on Commuter Flows on the Texas-Mexico Border. Journal of Borderlands Studies 4:71–88.
Dennis, N.P.S. 2002. Long-Term Traffic Forecasts and Flight Schedule Patterns for a Medium-Sized European Airport. Journal of Air Transport Management 8:313–324.
Dhane, G. and A.P. Barten. 1989. Where It All Began: The 1936 Tinbergen Model Revisited. Economic Modelling 6:203–219.
Fair, R.C. 1984. Specification, Estimation, and Analysis of Macroeconometric Models. Cambridge, MA: Harvard University Press.
Fullerton, T.M., Jr. 1998. Cross Border Business Cycle Impacts on Commercial Electricity Demand. Frontera Norte 10:53–66.
______. 2000. Currency Movements and International Border Crossings. International Journal of Public Administration 23:1113–1123.
______. 2001. Specification of a Borderplex Econometric Forecasting Model. International Regional Science Review 24:245–260.
Fullerton, T.M., Jr., M.M. Laaksonen, and C.T. West. 2001. Regional Multi-Family Housing Start Forecast Accuracy. International Journal of Forecasting 17:171–180.
Fullerton, T.M., Jr., J. Luevano, and C.T. West. 2000. Accuracy of Regional Single-Family Housing Start Forecasts. Journal of Housing Research 11:109–120.
Fullerton, T.M., Jr., and R. Tinajero. 2002. Cross Border Cargo Vehicle Flows. International Journal of Transport Economics 29:201–213.
______. 2003. Borderplex Economic Outlook: 2003–2005. Business Report SR03-2. El Paso, TX: University of Texas at El Paso, Border Region Modeling Project.
Fullerton, T.M., Jr., R. Tinajero, and L. Waldman. 2004. Regional Econometric Income Forecast Accuracy. Journal of Forecasting (forthcoming).
Fullerton, T.M., Jr., and C.T. West. 1998. Regional Econometric Housing Start Forecast Accuracy in Florida. Review of Regional Studies 28:15–42.
Funk, T.H., L.R. Chinkin, P.T. Roberts, M. Saeger, S. Mulligan, V.H.P. Figueroa, and J. Yarbrough. 2001. Compilation and Evaluation of a Paso del Norte Emission Inventory. Science of the Total Environment 276:135–151.
González, P. and P. Moral. 1995. An Analysis of the International Tourism Demand in Spain. International Journal of Forecasting 11:233–251.
Granger, C.W.J. 1996. Can We Improve the Perceived Quality of Economic Forecasts? Journal of Applied Econometrics 11:455–473.
Howry, E.P. 1969. On the Choice of Forecasting Models for Air Travel. Journal of Regional Science 9:215–224.
Hunt, L.C. and M.C. Snell. 1997. Comparative Properties of Local Econometric Models in the UK. Regional Studies 31:891–901.
Kim, C.H. 1995. Regional Forecasting Analysis for the Kyunggi Province. Korean Economic Journal 11:147–162.
Klein, L.R. 1969. The Specification of Regional Econometric Models. Papers of the Regional Science Association 23:105–115.
Leamer, E.E. 1983. Let's Take the Con Out of Econometrics. American Economic Review 73:31–43.
Lenze, D.G. 2000. Forecast Accuracy and Efficiency: An Evaluation of Ex Ante Substate Long-Term Forecasts. International Regional Science Review 23:201–226.
Leppold, K. 2002. El Paso, TX. Global Insight U.S. Markets Metro Economies—South. Fall:67–72.
Matthews, L. 1995. Forecasting Peak Passenger Flows at Airports. Transportation 22:55–72.
McCloskey, D.N. and S.T. Ziliak. 1996. The Standard Error of Regressions. Journal of Economic Literature 34:97–114.
Orrenius, P.M., K. Phillips, and B. Blackburn. 2001. Beating Border Bottlenecks in U.S.-Mexico Trade. Federal Reserve Bank of Dallas Southwest Economy. September/October: 1–8.
Pagan, A.R. 1974. A Generalised Approach to the Treatment of Autocorrelation. Australian Economic Papers 13:260–280.
Pindyck, R.S. and D. L. Rubinfeld. 1998. Econometric Models and Economic Forecasts. Boston, MA: Irwin/McGraw-Hill.
Roderick, L.M. 1993. A Computer Simulation of the Impact of the Cordova Bridge Traffic Delays on the Environment. Journal of Environmental Science & Health, Part A 28:1927–1946.
Sawyer, W.C. and R.L. Sprinkle. 1986. The Effects of Mexico's Devaluations and Tariff Changes on U.S. Exports. Social Science Journal 23:55–62.
Schneider, J.B. 1975. Self-Fulfillment of Long-Range Transportation Forecasts. Traffic Quarterly 29:555–569.
Shankar, R. 2003. El Paso. Economy.com Précis: METRO. March:1–3.
Theil, H. 1961. Economic Forecasts and Policy, 2nd edition. Amsterdam, Netherlands: North-Holland.
West, C.T. 1995. Regional Economic Forecasting: Keeping the Crystal Ball Rolling. International Regional Science Review 18:195–200.
______.2003. Structural Regional Factors that Determine Absolute and Relative Accuracy of U.S. Regional Labor Market Forecasts. Journal of Agricultural & Applied Economics 35 (Supplement):121–135.
West, C.T. and T.M. Fullerton, Jr. 1996. An Assessment of the Historical Accuracy of Regional Economic Forecasts. Journal of Forecasting 15:19–36.
Zandi, M.M. 2003. Reasons for Optimism. Economy.com Regional Finance Review 14:11–16. April.
APPENDIX
Equation (A1) shows how the RMSEs are computed. In (A1), Y s is the forecast value for variable Y , Y a is

the actual historical value for Y, and T is the total number of forecasts for Y .
Equation (A2) provides the details for calculating the U-statistics. The

denominator in (A2) causes inequality coefficients to vary between 0 and 1. When U = 0,  for all t and a perfect fit is obtained. At the other extreme, if U = 1, the predictive performance of the model cannot be any worse (Pindyck and Rubinfeld 1998). for all t and a perfect fit is obtained. At the other extreme, if U = 1, the predictive performance of the model cannot be any worse (Pindyck and Rubinfeld 1998).
Equation (A3) illustrates the formulae for the second moment inequality proportions. U M , U S , and U C represent bias, variance, and covariance proportions,
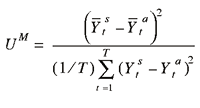 , ,
 , ,
and

respectively, of the second moment of the prediction errors (Theil 1961). The bias proportion measures the extent to which the average values of the simulated and actual series deviate from each other. It thus provides an indication of systematic error. Optimally, the bias proportion will approach zero. The variance proportion indicates the ability of the model to replicate the degree of variability in the variable of interest. Again, as simulation performance improves, the variance proportion approaches 0. The covariance proportion measures unsystematic error. As simulation accuracy improves, the covariance proportion approaches 1. As noted by Theil (1961), the optimal distribution of the second moment inequality proportions is U M = 0, U S = 0, and U C = 1.
END NOTES
KEYWORDS: Econometric forecasts, air transportation, border economics. JEL Category R15: Regional Econometrics
1 Statistical output for the econometric equations currently comprising the borderplex model are available from the author.
|

