Statistically-Based Validation of Computer Simulation Models in Traffic Operations
and Management
Jerome Sacks*
National Institute of Statistical Sciences
and Duke University
Nagui M. Rouphail
North Carolina State University
Byungkyu (Brian) Park
University of Virginia
Piyushimita (Vonu) Thakuriah
University of Illinois at Chicago
ABSTRACT
The process of model validation is crucial for the use of computer simulation models in transportation policy, planning, and operations. This article lays out obstacles and issues involved in performing a validation. We describe a general process that emphasizes five essential ingredients for validation: context, data, uncertainty, feedback, and prediction. We use a test bed to generate specific (and general) questions as well as to give concrete form to answers and to the methods used in providing them.
The traffic simulation model CORSIM serves as the test bed; we apply it to assess signal-timing plans on a street network of Chicago. The validation process applied in the test bed demonstrates how well CORSIM can reproduce field conditions, identifies flaws in the model, and shows how well CORSIM predicts performance under new (untried) signal conditions. We find that CORSIM, though imperfect, is effective with some restrictions in evaluating signal plans on urban networks.
INTRODUCTION
The validation of computer simulation models is a crucial element in assessing their value in transportation policy, planning, and operational decisionmaking. Often discussed and sometimes informally practiced, the process is conceptually straightforward. Data representing both the input and the output of the model are collected, the model is run with that input, and the output is compared to field data. In reality, complications abound: field data may be expensive, scarce, or noisy; the model may be so complex that only a few runs are possible; and uncertainty enters the process at every turn. Even though it is inherently a statistical issue, model validation lacks a unifying statistical framework.
The need to develop such a framework is compelling, even urgent. The use of computer models by transportation engineers and planners is growing. Costs of poor decisions are escalating, and increasing computing power, for both computation and data collection, is magnifying the scale of the issues. The opportunity is as great as the need. Advances in statistical techniques for incorporating multiple types of information, while managing the multiple uncertainties, enable progress in quantifying validation (Berliner et al. 1999; Lynn et al. 1998).
The purpose of this paper is to set out key issues faced in the validation of transportation models and to advance a research effort to address these issues. Many of the issues we describe are common to models and modelers in all areas of science and engineering:
- give explicit meaning to validation in particular contexts
- acquire relevant data
- quantify uncertainties
- provide feedback to model use and development
- predict performance under new (untried) conditions
While easily outlined, the challenge is to meet these issues. This can be achieved by describing and developing approaches and methods that are effective and can be implemented. That there are many obstacles to surmount is no surprise to those who have attempted exacting validations. However, there are tools capable of overcoming the impediments.
In order to make our points clear, we will use a test bed that generates the questions a validation must address and, at the same time, accommodates analyses that respond to the main issues. The test bed we use is the microscopic simulator CORSIM in an application to the assessment and selection of signal timing plans on an important street network in Chicago, Illinois.
Several research issues emerge from this investigation, indicating the following needs:
- to formulate evaluation functions that capture transportation needs and are amenable to either direct or indirect observation in the field
- to measure and assess the impact of data quality on evaluation functions and performance
- to develop methods for treating a variety of problems connected with the analysis of uncertainties, especially predictions
The general conclusion from the test bed is that, despite imperfections, CORSIM is effective as a model for evaluating signal plans on urban street networks under some restrictions. The basis of the statement is the validity of CORSIM prediction of performance under new conditions assessed by a second data collection, the gold standard of validation. The simplicity of the conclusion belies the complexity of the process, particularly evident in the feedback step of tuning the model to the specific network using an initial data collection.
We introduce the test bed example and simulator in the second section, along with the specific evaluation functions we use. Acquisition of data and the two field collections are described in the third section. Estimation of the input to the model is described in the fourth section. The fifth section covers the range of validation questions and the analyses relevant to them, including tuning, based on the initial data collection. The next section discusses the prediction of performance under new conditions and the subsequent validation. Questions about uncertainty are discussed in the following section, and our conclusions appear in the final section.
THE TEST BED: CORSIM AND SIGNAL TIMING ON AN URBAN STREET NETWORK
CORSIM is a computer simulation model of street and highway traffic. It is the quasi-official platform used by the U.S. Department of Transportation (USDOT) to gauge traffic behavior and compare competing strategies for signal control before implementing them in the field (USDOT
FHWA 1996).1 For
CORSIM to fulfill this purpose, two crucial questions must be addressed.
- How well does CORSIM reproduce field conditions?
- Can CORSIM be trusted to represent reality under new, untried
conditions, such as revised signal timing plans?
The localized and complex behavior that signal plans induce on urban street networks makes answering these two questions a challenge. Flows on these networks, even on small sub-networks, are highly complex. They include a variety of vehicles, pedestrian-vehicle interactions, and driver behavior, as well as an assortment of network conditions, such as different lane arrangements, stop signs, parking lots, and one-way streets. Moreover, the traffic demands on the network are highly variable, changing month to month, day to day, hour to hour, and even minute to minute. Equally varied are the many movements (legal and otherwise) of vehicles and pedestrians.
Since no simulator can realistically capture behavior exactly, formulating appropriate performance measures or evaluation functions is fundamental to the validation process. Variability, inherent in real traffic and also present in the computer model, compounds matters. Choices of performance measures introduce subjective elements and, thereby, potential sources of contention in assessment of the computer model.
To focus the issues, we undertook a case study with the cooperation of the Chicago Department
of Transportation (CDOT) with the ultimate goal of optimizing the signal plans for a network
more extensive than the one here. The test bed for the study is the network depicted
in figure 1. The internal network (Orleans to LaSalle; Ontario to Grand) in figure 1 is the key part of a planned Real-Time Traffic Adaptive Control System (RT-TRACS) study to be carried out in the future. A different network was studied earlier (Park et al. 2001) and helped guide some of the decisions made in the
current test bed.
Traffic in the network depicted in figure 1 flows generally south and east during the morning peak and north and west in the evening peak. This demand pattern is accommodated by a series of high-capacity, one-way arterials such as Ohio (eastbound), Ontario (westbound), Dearborn (northbound) and Clark and Wells (southbound), in addition to LaSalle (north- and southbound). For reference purposes, the Chicago central business district (CBD) is located southeast of the network.
CORSIM Characteristics and Inputs
CORSIM is a microscopic and stochastic simulator. It represents single vehicles entering the road network at random times moving (randomly) second-by-second according to local interaction rules that describe governing phenomena such as car-following logic (rules for maintaining safe distances between cars), lane changing, response to traffic control devices, and turning at intersections according to prescribed probabilities. CORSIM can handle networks of up to 500 nodes and 1,000 links containing up to 20,000 vehicles at one time. The figure 1 network has 112 1-way links, 30 signalized intersections, and about 38,000 vehicles moving through it in 1 hour. Streets are modeled as directed links with intersections as nodes.
There are a variety of inputs or specifications that must be made, either directly or by default values provided in CORSIM. Input that must be made directly include the following.
- specification of the network via fixed inputs describing the geometry, such as distance between intersections, number of traffic lanes, and length of turn pockets; the placement of stop signs, bus stops, schedules, and routes; and parking conditions
- probability distributions of interarrival times governing the generation of vehicles at each entry node of the network; the choices in CORSIM of arrival-time distributions are limited, in essence, to Gamma (Erlang) densities, λ = average interarrival time or 1/λ is the expected number of vehicles arriving in 1 second; k determines the shape of the
Gamma density.
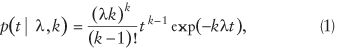
assumed independent (vehicle-to-vehicle, node-to-node) but allowed to be different for each entry node
- vehicle mix (auto or truck) through independent Bernoulli trials with probabilities that can differ from entry node to entry node
- probability distributions of turning movements, assumed to be independent, vehicle-to-vehicle and link-to-link and different from link-to-link
CORSIM provides several default inputs. The chief inputs relate to driver characteristics, such as car-following behavior (how closely drivers follow other vehicles), left turn “jumpers” (drivers who “jump the gun” ahead of oncoming traffic), acceptance of gaps between vehicles (before making turns or lane changes), and lane-changing maneuvers. For example, gap acceptance is governed by a discrete distribution with 10 mass points. The default distribution can be accepted or altered. Other inputs with default distributions that can be altered are dwell times for buses, effects of pedestrians on turning vehicles, and short-term incidents, such as an illegally parked delivery truck.
Although altering the default distributions through data use is possible in some cases, data that would better determine driver characteristics are too elusive. For the test bed study, we assumed no pedestrian traffic (normally light on this network) and no incidents.
Signal settings are direct inputs. We single them out as controllable factors since altering these inputs to produce improved traffic flow drives the study. Signal settings consist of a cycle common to all signals, green times for movements at each intersection, and offsets (time differences between beginnings of cycles at intersections).
For validation, the signal plan will be the one in the field. For finding optimal fixed-time
signal-timing plans2
or for comparing alternative plans, the signal parameters will necessarily be manipulated. Comparisons are best done through the simulator since field experiments are not feasible. Relying on CORSIM to select an alternative to an in-place plan then raises our earlier-posed questions.
CORSIM Output
CORSIM comes equipped with an animation package (TRAFVU) allowing visualization of traffic movements, valuable when exploring the characteristics of the model and detecting problems and flaws. In addition to the visual output, CORSIM provides aggregated (over selected time intervals, such as the signal cycle) numerical output for each link. The numerical outputs include the following.
- throughput (the number of vehicles discharged on each link)
- average link travel time
- link queue time (the sum over vehicles of the times, in minutes, during which the vehicles are stationary, or nearly so)
- link stop-time (sum over vehicles of stationary time)
- maximum queue length (on each lane in the link over the simulation time)
- link delays (simulated travel time minus free-flow travel time, summed over all vehicles discharging the link)
Most of these statistics can be attached to movements or lane levels within each link, but we do not do so. We will take CORSIM performance measures from this output.
One hour of simulation for the test bed network takes about 40 seconds on a Pentium III-850 MHz PC. During this time, approximately 38,000 vehicles are processed through the network. While each run is quick, the need for many runs to deal with the substantial variability induced by the stochastic assumptions lengthens experimental time considerably. A detailed uncertainty analysis greatly increases computational demands. An advanced computing environment (for example, distributing the simulations across a network of machines) could, of course, substantially reduce computing time.
DATA COLLECTION
A crucial element in validation is designing and carrying out data collection both for estimating input to the model and for comparing model output with field data. The challenge lies in managing costs while obtaining useful data relevant to both estimation and validation.
For our test bed example, initial field data for the network were collected on a single day (Thursday, May 25, 2000) for three hours in the morning (7:00 am to 10:00 am) and three hours in the afternoon (3:30 pm to 6:30 pm). The processing of the data and the analyses were limited to the three one-hour periods, 8 am to 9 am, 4 pm to 5 pm, and 5 pm to 6 pm. This covered the peak periods as well as a “shoulder” period.
Acquiring data for the input to CORSIM is a formidable task. Input such as driver characteristics is extremely difficult to gather, and in the test bed example we relied mostly on CORSIM default values. There were very few pedestrians, and they had no discernible effect on traffic, leading us to ignore the pedestrian input. Incidents were not included, despite the fact that there were illegally parked vehicles that did affect traffic flow. Because illegal parking was an endemic condition, we coded the network to account for its effect. Other parameters, such as free-flow speed, were selected on the basis of posted speed limits. Signal timing plans and bus routes and stations were collected directly in the field and entered into CORSIM.
Traffic volume data were collected manually by observers counting vehicles and by video recording. Human observation is notoriously unreliable, but cost considerations did not allow video coverage of the full network. However, the video information, covering all the links of the internal network of figure 1, was rich enough to allow adjustment of the observers’ counts that determined the flow rate of vehicles at entry nodes of the network. On the other hand, turning movements outside the internal network could neither be confirmed nor reliably adjusted by video information. Extracting the video information took a considerable investment of time and personnel, rivaling the cost of acquiring the raw video data.
Supplemental validation data were collected on a similar schedule on September 27, 2000. These were extracted primarily from video. The purpose was to answer our second question, if CORSIM accurately represents reality under new conditions, by analyzing its effectiveness of CORSIM in predicting traffic behavior under the September conditions.
It is most convenient to collect data for validation while collecting data for inputs. The use of the same or closely related data for both input and validation is an issue rarely confronted. The conventional wisdom says that such dual-use of the data is forbidden. In fact, it can be done but the attachment of computable uncertainties, essential to producing reliable results, is not straightforward. This issue is under study by a research team at the National Institute of Statistical Sciences (NISS) and Duke University. A Bayesian approach based on Bayarri and Berger (1999) holds promise for producing methodology to treat the issue.
A problem as yet not addressed is assessing the impact of data of inferior quality. The problem is complicated by the need to specify the brunt of the impact; to quantify scenarios of alternative collections of data; and to design, execute, and analyze computational experiments to measure the consequences, or sensitivities, of model output to wrong data input, including incorrect signal settings or drifts in signal timing. This issue is not unique to transportation studies and research; it permeates virtually all sciences.
ESTIMATION OF CORSIM INPUT FROM INITIAL (MAY) DATA COLLECTION
The direct, fixed input required for CORSIM to run, including signal timing plans for each of the three one-hour periods, was obtained from the field and entered into CORSIM. The direct input requiring estimation was treated as follows.
- Vehicle mix at each entry node was estimated from one-hour (human-observer) counts for autos and trucks.
- Turning probabilities (left turn, right turn, through) at each intersection were estimated from one-hour video counts (where available) and from human-observer counts at other intersections.
- Inter-arrival rates (see equation 1) were estimated with the assumption that k = 1. The λ for each entry node and each of the 3 one-hour time periods was estimated as the total number of vehicles entering the (entry) link divided by 3,600.
Some λs were later adjusted to reduce discrepancies between downstream counts generated by CORSIM and those observed by video; the discrepancies were believed to be due to inaccuracy of human-observer counts and the effects of parking lots. Turning movements were left at their field estimates. Measuring the ultimate effect on uncertainty of these modifications is an issue that remains to be explored.
Validation Process
Validation without purpose has little utility. For example, our interest in CORSIM here is its value in assessing and producing good time-of-day signal plans. But, CORSIM could also be used to evaluate traffic operations under disruptions, such as a bridge closing, or to changes in the network, such as strict enforcement of parking laws or truck restrictions. A more subtle use could be in measuring the impact of driver decisions when faced with a network modification. Some objectives may only reflect changes in the network; others may also implicate induced changes in demand.
Navigating through this variety of issues requires multiple tools. For example, visualization and expert opinion give an overall assessment of whether the model output matches reality in a qualitative but highly subjective way. When video data are placed next to computer animations, discrepancies (and similarities) can be seen directly, particularly if viewers are experts familiar with the network and its characteristics.
However, the stochastic nature of CORSIM and of real traffic requires more than informal visualization. Questions remain, such as which random animation should be used to compare with the real traffic and is the single day of traffic recorded by video typical. More stringent comparisons based on a second tool, statistical analysis, become crucial in reducing the subjectivity, guiding the visualization through choices of animation, and pointing to model flaws responsible for aberrant behavior. The challenge is then to provide statistical analyses appropriate to the desired ends.
There can be many competing analyses, one for each evaluation criterion as defined in the following section. Treating the multiplicity of comparisons in a coherent way is often disregarded. Is the model flawed if it produces a poor match to reality at only one (five?) of one hundred links? Added complications come from comparisons based on evaluations of corridor and system characteristics as well as those of individual links.
Thus, the initial task is to select evaluation criteria. Comparison of the field and model through selected evaluation functions in the specific application of CORSIM to the network of figure 1 will touch on the concerns and issues raised.
Evaluation Functions
Selecting an evaluation function φ is crucial and sometimes complicated by competing practical and theoretical considerations. First, is φ relevant to the purpose? Choosing among many φs relevant is sometimes eased by requiring feasibility in both calculating model output for φ and collecting field data for calculating corresponding field value(s) of φ.
In our test bed example, a good criterion for judging a signal-timing plan may be average link travel time, complicated to obtain in CORSIM and costly to obtain in the field. The tactic of using probe vehicles, while possible in principle, is inhibited by the cost of using large numbers of vehicles and the need to account for the substantial variability connected with the use of probes. Computing vehicles’ travel time from video is highly labor-intensive; useful, automatic area-wide detection methods, such as Mobilizer (Lall et al. 1994), are neither widely available nor fully adequate.
The evaluation function φ is likely to have versions at multiple time scales and at different levels of spatial aggregation. For example, total queue-time per cycle per link could be aggregated over cycles and over links to form evaluations based on behavior over selected corridors, over the whole system, and over distinct time periods. The choice of levels of space-time resolution adds to the determination of relevance and can be complicated by questions of feasibility.
Statistical analyses of the φs must treat the variability arising from the
intrinsic stochastic structure of simulators such as
CORSIM.3
However, field variability is also consequential, and that cannot be so readily captured without elaborate and costly field-data collection. This is a confounding issue, partly addressed below.
Travel times are very hard to obtain in the field. Stop time per vehicle can be calculated for each link covered by video. Queue length per cycle can also be calculated, but queue time is very difficult to obtain in the field though a standard part of CORSIM output.
We chose stop time (stopped delay) on approaches to intersections as the primary evaluation
function. It has been the typical measure by which intersection level of service (LOS) is
evaluated (TRB 1994). The comparative ease of collecting stop time data from the video
strongly affected our choice, reinforced by the fact that other criteria such as throughput,
delay, travel time, and queue length are all highly correlated with stop
time.4
In addition, we believe that drivers on urban street networks are particularly sensitive to stop time, spurring traffic managers to seek its reduction. In fact, the Highway Capacity Manual’s selection of stopped delay for LOS designation is meant to reflect the user’s perception of the intersection’s quality of service. We used V (the number of vehicles leaving an intersection, particularly exit nodes) as an auxiliary evaluation function. V is readily calculated from video and is also needed to calculate stop time per vehicle discharged (STV) at a link. At
approach a,
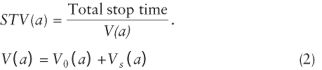
where V0 is the count of vehicles that do not stop on a, while Vs is the count of vehicles that do stop on a. This raises the question of whether STV is an adequate reflection of the characteristics of the network (and signal plan) compared to the pair
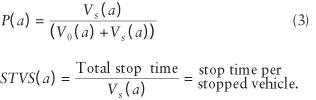
We will see that these quantities provide a sharper understanding of the comparison between CORSIM and the field.
STV or STVS for aggregations of approaches (routes or corridors) is very difficult to obtain, requiring the tracking of individual vehicles. But some concept of performance on aggregation could be important. For example, a long delay on one link may be compensated by a short delay on the next link downstream, leaving the corridor and the system as a whole unaffected. By summing over the individual links forming a corridor, we create a “pseudo stop time” for the corridor. This will be close to a real stop time, provided vehicles turning off of or on to the corridor exhibit little or no difference from those traveling straight through. However, the value of such “pseudo stop times” is unclear, and here we only deal with individual links and approaches.
Multiplicity questions begin with the selection of links or approaches for comparison. We selected links on corridors that contained the heaviest traffic during the main peak period directions, east and south in the morning and west and north in the evening. A full treatment of multiplicity questions will not be presented here.
Tuning
Tuning and calibrating a model are general terms, often used interchangeably, sometimes yielding confusion. In the previous major section, we treated estimation of input to the model directly from field data. When model output data are used, either alone or with field data, to determine input parameters, the process is often called calibration. Tuning is a term commonly associated with adjusting input parameters to match model output. As in the usage of “calibration,” the term tuning is frequently reserved for cases where the input parameters are unobservable or represent physical and other processes the model does not (or cannot) adequately incorporate.
The practice of tuning is not only common but often essential, especially for a long-range study of the model and its associated phenomena. Some input parameters may be neither well-specified nor capable of being estimated from the field data. One example is driver aggressiveness in our test bed. Some assumptions about input parameters may be found erroneous after viewing the data, and their modification may produce better simulations. Ultimately, the validation accompanying such tuning becomes problematic.
Two types of tuning were done in the test bed example. The first addressed the blockage of turns at two intersections and the subsequent gridlock. We altered the network by introducing sinks and sources that allowed the bypass of the blockage without affecting throughput. The second was stimulated by a substantial difference on one link (at the LaSalle/Ontario intersection in figure 1) between the field and CORSIM stop times. This difference was largely resolved by changing the free flow speed from 30 miles per hour (mph) to 20 mph. The input of 30 mph was induced by the speed limit; its revision to 20 mph is consistent with the observed (from video) speed of vehicles on the corridor (LaSalle Street).
Visual Validation
Where visualization is available, as it is with CORSIM animation and with video field data, a compelling approach to validation is visually comparing the two to see if traffic in CORSIM behaves like traffic in reality. To a great extent, this is a highly informal and subjective approach. Nonetheless, it is of great value in assessing CORSIM’s capability to emulate reality as well as identifying sources of trouble or flaws in CORSIM, flaws that can sometimes be corrected by intervention in the coding.
The utility of visualization depends on the specifics of each application. What may be learned from the CORSIM example may pertain to other microsimulators but not necessarily to other computer models.
A sign of problems in an application of CORSIM is the presence, in several of the replicate simulation runs, of spillback and gridlock in situations where these do not occur in reality. Spillback will occur on networks such as in figure 1, where near saturation conditions are present during peak periods; however, recovery in the field usually takes place reasonably quickly. A difficulty with CORSIM is its apparent inability to recover readily from spillback, often resulting in gridlock. The effect on performance measures is usually to produce large outliers in a repeated set of simulations, sometimes indicated by large run-to-run variance. A histogram of outputs can identify large outliers. Following up with examination of the corresponding animations can often identify causes.
In two instances, it was apparent that the cause was an inability of CORSIM to allow driver adjustment to left (or right) turn blockage, resulting in a spillback that would never clear up.
Numerical Comparisons
Throughput Comparison
In table 1, we present test bed results on throughput for internal network. The net change indicates discrepancies showing less output in the morning and more output in the evening. This is due to the garage effect: vehicles disappear to the parking lots in the morning and reappear from them in the evening.
The means of 100 replicated CORSIM runs are close to the observed counts in
table 2, except for eastbound Ohio/LaSalle in the morning and westbound Grand/Wells in the evening. The first can be explained in large part by the disappearance of vehicles in the morning into parking lots along Ohio Street, a major one-way, eastbound corridor. The second, correspondingly, can be attributed to the appearance of vehicles from parking lots on Grand during the evening. In addition, there is a high enough variability in CORSIM runs to account for a considerable part of the apparent discrepancy
(see figures 2 and
3).
It would be incautious to view the similarity of real data to the model runs as evidence of the model’s validity. Whether these internal throughputs are good evaluation functions is unclear. They are, however, relevant to STV and STVS because they determine the denominators of those measures. Not taken into account is the tuning of the model to help match inputs to the model with the flows observed in the video. How to achieve this formally is a matter of some delicacy and is a research issue currently under investigation in a National Science Foundation sponsored research project at NISS.
Though field variability cannot be adequately captured, we produced CORSIM and field time
series of throughputs to examine whether CORSIM shows a degree of variability (over time)
characteristic of the field data.
Figure 4 presents such time series, obtained as follows. There are 48 signal cycles during the 8 am to 9 am morning peak, and we combined throughputs over every 2 cycles, equal to 150 seconds of elapsed time in the 1-hour period. This leads to a time series at 24 time points. CORSIM was run 100 times, and the variation of each time
series was computed as
![[{the summation from lowercase t equals 1 to 23} [uppercase y times (lowercase t plus 1) minus uppercase y times (lowercase t)] superscript {2}] divided by 23](https://webarchive.library.unt.edu/eot2008/20081025220635im_/http://www.bts.gov/publications/journal_of_transportation_and_statistics/volume_05_number_01/images/equ_01_04.gif)
where Y(t) represents throughput during time interval t. We selected the representative CORSIM time series variation as the median of the 100 variations.
CORSIM variability, as shown in figure 4 (as well as on the link southbound LaSalle at Ohio), is close to that of the field. Indeed, the variation of the field series is 116 and is at the 30th percentile of the CORSIM distribution, as shown in
figure 5.
Stop Time Comparisons
The distribution of stop time at each approach has some probability at zero (the proportion
of vehicles that do not stop); this is singled out in the first part of
table 3. Characteristics of the conditional distribution of stop
time (given that a vehicle stops) are given in
table 4. There are definite discrepancies on southbound LaSalle at Ohio during the morning, where CORSIM generates fewer stops but longer stop times for its stopped vehicles. On eastbound Ohio at LaSalle, a similar (though somewhat reduced) discrepancy is apparent. While there appear to be differences on some of the other approaches, none appear very significant. For example, CORSIM stops fewer vehicles on northbound LaSalle at Ontario in the 5 pm to 6 pm period, but the stop times are close.
These differences call for an explanation. Examination of video and CORSIM animation exposes the key cause: CORSIM does not fully reflect driver behavior. In particular, lane utilization in CORSIM is not consistent with lane utilization in the field. On some links, vehicles in the field more often join long queues where they are briefly stopped. These vehicles typically do not appear in CORSIM simulation as having stopped. This accounts for smaller STVS in the field than in CORSIM. So, even though CORSIM does not fully reflect the field, the key measure of how long truly stopped vehicles are delayed appears to match what is seen in the field quite reasonably.
PREDICTION AND VALIDATION
The most compelling form of validation is through confirmation by predictions in new circumstances. In the test bed example, a plan, different from the one in the field in May, was put in place in September 2000. Under these new circumstances (a new signal plan) predictions were to be made and data collection designed for September 27, 2000, a day expected to be similar to the date of the first data collection, May 25, 2000.
The simulator’s performance prediction requires specification of the input expected at the time of the new data collection. Believing that the conditions in the field for the September data collection would be the same as in May, we ran CORSIM with the May input, except for signals.
After the data were collected in September, we compared the results, first for
throughput (table 5) on several key links. Except for the 13% disparity on southbound LaSalle,
the throughputs were close. Whether or not the disparity in demand on southbound LaSalle
mattered awaited further analysis of stop time. The predictions of September stop time performance
with the May input are in
tables 6 and
7 (see also
figures 6 and
7). Except for northbound Orleans to the freeway, the STVSs are reasonably close. For the reasons discussed earlier, we have several
disparities on stop rates.
To clarify these matters, we first checked the effect of change in demand on southbound LaSalle during the morning peak. We decreased the input demand there by 10%, reran CORSIM 100 times, and obtained essentially no change in output. The stop rate on southbound LaSalle at Ohio went from 30.3% to 30.9%, while STVS went from 22.0 to 22.3 seconds per vehicle (sec/veh).
Next we explored the disparity on northbound Orleans at the freeway in the afternoon peak and observed, through video, that drivers effectively used green time of 20 seconds instead of the displayed green time of 16 seconds. Introducing this modification changed stop rates from 74% to 65%, and average STVS changed from 51.9 to 40.8 sec/veh with a standard deviation of 6.8. The difference between 31.4 (the field STVS) and CORSIM’s average of 40.8 is neither statistically significant (within 2 standard deviations) nor practically significant (same level of service; see table 9). Nonetheless, we examined the northbound Orleans link more carefully. We noted that CORSIM has difficulty dealing with storage of vehicles on short, congested links just downstream of a wide intersection, exactly the characteristics of northbound Orleans at the freeway (the intersection at Ohio is 60 feet; the entire link is 240 feet; and the link is highly congested). We could have brought the CORSIM predictions more closely in line with the numbers in the field by altering the length of the link, but we regarded such tuning as potentially misleading.
A highly informative evaluation function of CORSIM is the change in CORSIM predictions,
Δ CORSIM (September STVS – May STVS), compared to the corresponding change
in the field values, Δ Field. Even though the CORSIM predictions were not always accurate,
the Δs are close and of the same
sign (table 8). This is particularly important for comparing the performance of competing signal plans: predictions of improvements (in two links), no change (in two links), and degradation (on one link) in CORSIM jibes with the changes in reality.
ANALYSIS OF UNCERTAINTY
A more exacting treatment of validation requires closer attention to the following.
- uncertainties inherent to the simulator as well as from parameter estimates used to define input distributions
-
multiplicity questions arising from the use of multiple evaluation functions (for
example, the multiple link/approaches in
tables 1 and
2)
The first item can be addressed through a Bayesian analysis. For instance, in the test bed
example, the uncertainty question can be dealt with by specifying prior distributions for
the λs in equation (1) as well as for the probabilities p of turning movements.
Posterior distributions of λ,p can then be computed given field data. Before each
CORSIM run, a draw from the posteriors can be made, leading to a selection of λ,p, which then provides the needed input for the run. The resulting variability in 100 runs, for example, will then incorporate both the inherent CORSIM variability as well as the uncertainty stemming from the use of the field data in estimating λ,p.
Bayarri, Berger, and Molina (2001) are carrying out such a Bayesian analysis. Preliminary results indicate that while the variability of STVS may increase, the qualitative behavior of CORSIM remains the same. Complications in the analysis derive from the complexity of the network and its impact on computing the posterior distribution. These results will appear elsewhere.
A fuller Bayesian treatment of uncertainty of prediction, now under study, can incorporate questions of systematic bias in CORSIM predictions of reality. One aspect of such an inquiry is the potential use of a “CORSIM adjusted by bias” predictor in place of CORSIM itself.
The treatment of multiplicity requires appropriate formulation. Methods described in Westfall and Young (1992) and Williams et al. (1999), as well as False Discovery Rate approaches (Benjamini and Hochberg 1995), are not clearly applicable due to the high level of dependence among evaluation functions.
Last, we note that the effect of the uncertainties will be felt in the evaluation functions
or, equivalently, through loss structures that take practical significance into account. For
example, a difference of 5 seconds in stop time can be minor, but a difference of 15 seconds
may be major. One starting point may be a comparison of the field and CORSIM-predicted LOS.
Table 9 shows criteria for LOS based on stopped time in the 1994 Highway Capacity Manual.
CONCLUSIONS
We present conclusions about the validation process and the specific test bed model, CORSIM. The validation process has five key elements: context, data, uncertainty, feedback, and prediction. Context is critical. It drives the formulation of evaluation functions or performance measures that are ultimately the grounds on which validation must take place and affect interpretations of uncertainty. For example, statistically significant disparities may, in the context of an application, be practically insignificant. In addition, context and the specified evaluation functions can affect the selection or collection of data, both field and model output, to be used for evaluation. Conversely, the availability or feasibility of data collection can determine the choice of evaluation functions. These factors may then converge in the calculation of uncertainties stemming from noisy data and model imperfections. The outcome of the evaluations and the associated uncertainties points to possible flaws in the models and feedback to model adjustments that correct or, perhaps, circumvent the flaws. Ultimately, it is through prediction that validation of a model is reached.
The process we described is effective and generally applicable. Of course, implementing the particulars, done for the most part in the test bed example, will require filling in a number of gaps, most specifically in determining uncertainties but also in designing data collection, assessing the impact of data quality, and detecting flaws.
Test bed conclusions derive from the two questions we posed: Does CORSIM mirror reality when properly calibrated for field conditions? Does CORSIM adequately predict traffic performance under revised signal plans?
Comprehensive calibration of CORSIM is infeasible; there are too many parameters that can (and some that cannot) be calibrated with field data. Our approach was to focus on key input parameters, such as external traffic demands, turning proportions at intersections, and effective number of lanes (for example, due to illegal parking), using CORSIM default values for other inputs.
We found that CORSIM was effective but flawed. A major difficulty is CORSIM’s propensity to turn spillback into gridlock; inadequately modeled driver behavior led to intersection blockage far too frequently. CORSIM does not accurately model lane distribution of traffic. Lane selection in reality was much more skewed than in CORSIM. CORSIM tends to stop more vehicles than indicated in the field. In reality, drivers coast to a near stop then slowly accelerate through the signal, but the behavior is much more abrupt in CORSIM.
The first of these flaws was corrected by modifying the network. The second flaw had some effect but was relatively minor. The third flaw manifested itself in disparate stop rates but did not seriously affect stopped time per vehicle stopped (STVS).
Overall, despite its shortcomings, CORSIM effectively represented field conditions. Even when the field observations lie outside the domain of the CORSIM distributions, as in figures 2 and 3, there is virtually no difference in the estimated levels of service (table 9) between the field and CORSIM, practically insignificant even if statistically
significant.5
The predictability of CORSIM was assessed by applying revised (September) signal plans to the May traffic network. CORSIM estimates of STVS were reasonably close to field estimates, and the CORSIM LOSs were, for the most part, similar to those observed in the field. More importantly, CORSIM successfully tracks changes in traffic performance over time: on five links for which field data were available, two links exhibited a reduction in STVS, one link an increase, and two had no significant change; CORSIM’s predictions were the same.
In summary, a candid assessment of CORSIM is that with careful calibration and tuning, CORSIM output will match field observations and be an effective predictor.
ACKNOWLEDGMENTS
The authors are very grateful for the support and assistance of Mr. Christopher Krueger and Mr. Thomas Kaeser of the Chicago Department of Transportation. We also thank the Urban Transportation Center at the University of Illinois at Chicago for their help in the data collection. This research was sponsored in part by grants DMS-9313013 and DMS-9208758 from the National Science Foundation to the National Institute of Statistical Sciences.
REFERENCES
Bayarri, M.J. and J.O. Berger. 1999. Quantifying Surprise in the Data and Model Verification. Bayesian Statistics 6. London, England: Oxford University Press.
Bayarri, M.J., J.O. Berger, and G. Molina. 2001. Fast Simulators for Assessment and Propagation of Model Uncertainty. Proceedings of the Third International Symposium on Sensitivity Analysis and Model Output.
Benjamini, Y. and Y. Hochberg. 1995. Controlling the False Discovery Rate: A Practical and Powerful Approach to Multiple Testing. Journal of the Royal Statistical Society B 57(1):289–300.
Berliner, L.M., J.A. Royle, C.K. Wikle, and R.F. Milliff. 1999. Bayesian Methods in the Atmospheric Sciences. Bayesian Statistics 6. London, England: Oxford University Press.
Lall, B., K. Dermer, and R. Nasburg. 1994. Vehicle Tracking in Video Image: New Technology for Traffic Data Collection, in Proceedings of the Second International Symposium on Highway Capacity, Sydney, Australia, 365–83.
Lynn, N., N. Singpurwalla, and A. Smith. 1998. Bayesian Assessment of Network Reliability. SIAM Review 40:202–27.
Park, B., N. Rouphail, J. Hochanadel, and J. Sacks. 2001. Evaluating the Reliability of TRANSYT-7F Optimization Schemes. Journal of Transportation Engineering 127(4):319–26.
Transportation Research Board (TRB). 1994. Highway Capacity Manual. Washington, DC: National Research Council.
U.S. Department of Transportation (USDOT), Federal Highway Administration (FHWA). 1996. CORSIM User Manual. Washington, DC.
Westfall, P.H. and S. Young. 1992. Resampling-Based Multiple Testing. New York, NY: Wiley-Interscience.
Williams, V.S.L., L.V. Jones, and J.W. Tukey. 1999. Controlling Error in Multiple Comparisons, with Examples from State-to-State Differences in Educational Achievement. Journal of Educational and Behavioral Statistics 24(1):42–69.
Address for Correspondence and End Notes
Jerome Sacks, National Institute of Statistical Sciences, Research Triangle Park, NC 27709-4006. Email: sacks@niss.org.
1 CORSIM version 4.32 is used in this paper.
2 Adaptive plans are under consideration as part of the RT-TRACS program and require extensive sensor capabilities to capture dynamic traffic conditions; models accommodating such plans are themselves subject to validation study.
3 Deterministic models will not have intrinsic randomness but will be exposed to variability either in assumptions about input parameters or from data used to estimate input parameters.
4 Rejection of delay was also affected by CORSIM calculations that fail to include vehicles left in the system at the end of the one-hour simulation period, potentially resulting in misleading numbers under congested conditions.
5 The CORSIM distribution does not reflect the additional uncertainty induced by the field data estimates of model input parameters. Therefore, statistical significance here is overstated.
|

