Estimation and Accuracy of Origin-Destination Highway Freight Weight and Value Flows
Paul Metaxatos
University of Illinois at Chicago
ABSTRACT
This paper proposes a spatial interaction modeling framework and implements a maximum likelihood estimation of highway freight weight and value flows using the gravity model. The computation of the standard error of the flow estimates provides the basis for measuring the level of accuracy of the estimates. The results provide evidence of the suitability of gravity models for freight forecasting given the excellent fit and the small variances.
INTRODUCTION
The measurement of freight movements requires tracking freight flows across geographic and political boundaries. This is a particularly challenging task given the current capabilities for state and regional data acquisition. Various mathematical approaches have been implemented (Memmot 1983; USDOT 1996; Cambridge Systematics 1997) to circumvent this problem, but none, to the best of this author's knowledge, proposes a measure to assess the accuracy of the computed flows.
This paper proposes to fill this gap using developments in spatial interaction modeling that have not been demonstrated on a large scale to date. The methodology computes maximum likelihood flow estimates and obtains their covariance matrices that, in turn, may be used to obtain confidence intervals and carry out certain tests of hypotheses. The approach can accommodate the large number of origins and destinations typically encountered in freight (and passenger) travel forecasting.
The methodology was applied to highway freight weight and value flows of international trade traffic between seaports or border ports and destination states (see Metaxatos (2002) for details). The variances of the flow estimates computed were remarkably small. The demand for freight transportation flows can then be estimated within a desired confidence level. Moreover, the empirical analysis undertaken provides evidence that the theoretical framework proposed in this paper is rich enough for freight demand forecasting applications.
THEORETICAL FRAMEWORK
Commodity shipments in this paper are thought to be realized patterns of spatial interactions that typically result from many independent decisions by individual firms, each constituting a relevant subsystem within the economy as a whole. Hence, if the travel behavior of each firm is modeled as a very small interaction process, the resultant interaction process can be taken to be the superposition of all these processes. It may be argued that for large collections of small frequency processes, the resulting superimposed process is approximately Poisson and, therefore, completely characterized by its associated mean interaction frequencies (Sen and Smith 1995).
In this light, assuming that the observations Nij
of shipment weight and value between origin seaports/border ports of entry i
and destination states j
can be described by the gravity model, then
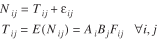 (1)
(1)
In this paper, Tij
's (the stochastic term) are interpreted as the expected international trade traffic flow (in terms of weight and value) carried by highway from external station i
to state j.
The Ai
's are factors related to the origin zone i
and the B
j
'
s are destination-related factors. The Fij
's are factors that reflect the separation between i
and j.
A common form that is general enough for most applications is
![uppercase F subscript {lowercase i j} = exp [summation over lowercase k lowercase theta subscript {lowercase k} lowercase c superscript {(lowercase k)} subscript {lowercase i j}] for all the lowercase i, j](https://webarchive.library.unt.edu/eot2008/20081012180425im_/http://www.bts.gov/publications/journal_of_transportation_and_statistics/volume_06_number_23/images/Metaxatos-2.gif) (2)
(2)
This form is called an exponential form and 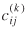 are different measures of separation, while θk 's are parameters to be estimated. Potential measures of separation include travel time, distance, generalized costs, etc.
are different measures of separation, while θk 's are parameters to be estimated. Potential measures of separation include travel time, distance, generalized costs, etc.
In the gravity model, observable quantities Ni* = Σj Nij,N*j = Σi Nij,Nij and their expected values Ti*, T*j, and Tij are described by means of an underlying structure consisting of unobservable quantities Ai, Bj, and Fij. Similar situations abound in statistics. In moving average models, for example, observations are described by means of unobservable parameters. A like situation exists in analysis of variance models.
Although the origin and destination factors are unobservable, they do have physical interpretations. For example, if for some origin i, there are two destinations j and j ' such that Fij = Fij', then Tij /Tij' = Bj /Bj '. Thus other factors being equal, Tij is proportional to Bj (but, in general, not proportional to T*j), and is called the attractiveness of j. Similarly, the origin factor Ai may also be called the emissiveness of i.
Clearly, BjFij
is the effect of the destination factor Bj
at i
, or the accessibility
of j
as perceived from i
. This is a spatial analogy of the temporal concept of present value in economics, where a dollar earned in n
years in the future is worth only (1 + σ)–n
now, where σ is the interest rate. Similarly, AiFij
is the effect of the origin factor Ai
at j
. The sum αi = ΣjBjFij
may be called the total accessibility of all destinations at i
, and the sum βj = ΣiAiFij
may be called the total accessibility of all origins at j
. If, for example, Ti* is kept fixed as αi increases, the push Ai
decreases. Thus, as the competition αi from the destinations increases, the push at i
decreases. From the point of view of someone at i
, αi measures accessibility; from the viewpoint at j
, it measures competition. Similar statements can be made about Bj.
Maximum Likelihood Estimation
The model (1) will be estimated using maximum likelihood (ML). Maximum likelihood estimates have desirable asymptotic properties (consistency, efficiency, and asymptotic normality) and are robust to distributional assumptions for realistic departures from the Poisson assumption (note that the multinomial distribution leads to identical estimates with the Poisson distribution). Furthermore, they are essentially unbiased even for a very small sample of flows (Sen and Smith 1995).
Under some mild conditions (Sen and Smith 1995), the ML estimate of ζ
= (A
(1),...,A
(i
), B
(1),...,B
(J
), θ1
,...,θ Q
)´
exists and that of θ is unique. The estimates of A
and B
are not unique; however, if one A
(i
) or B
(j
) is chosen to be an arbitrary positive number, the remaining A
(i
)'s and B
(j
)'s are unique under the previous mild conditions. It can be proved that the ML estimate of ζ results in the solution to the following system of equations
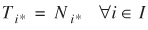 (3)
(3)
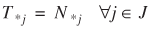 (4)
(4)
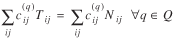 (5)
(5)
where the operator * indicates summation with respect to the subscript it replaces (e.g., Ti* = ΣjTij, T*j = ΣiTij
). A number of standard numerical methods or more specialized procedures can be used to solve equations (3) through (5). The three procedures adapted for the paper are the Deming-Stefan-Furness (DSF) procedure, the linearized DSF procedure, and the Modified Scoring procedure. An account of the development of the three procedures is given in Sen and Smith (1995). For completeness of the presentation, some of the details for each procedure follow.
The DSF Procedure for Parameters Ai
and Bj
The DSF procedure gives values of Tij
for any choice of (θ'
), and Ni*
,N*j
, with ΣiN i* = ΣjN*j
. Generally speaking, this procedure adjusts the rows (columns) of a two-dimensional table in each even (odd) iteration. After choosing an initial value for the column balancing coefficient, 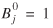 , say, the DSF procedure iterates as follows (the index r
denotes the iteration number):
, say, the DSF procedure iterates as follows (the index r
denotes the iteration number):
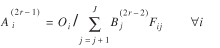 (6)
(6)
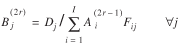 (7)
(7)
where Oi
= Ti*
, Dj
= T*j
, and Fij
is a function of the separation measures 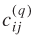 . Upon convergence (see Sen and Smith (1995) for a proof of convergence), the values of Tij
are given by
. Upon convergence (see Sen and Smith (1995) for a proof of convergence), the values of Tij
are given by
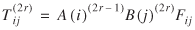 .
.
In this paper, we chose a fairly stringent criterion for convergence as follows
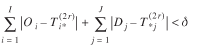 (8)
(8)
where δ
= 10–12
. The algorithm attained this criterion in less than 100 iterations.
The DSF procedure essentially expresses Tij
as a function of θ. These values of Tij
could then be used in equation (5) to solve for an updated value of θ. In general, however, as θ changes, equations (3) and (4) could be violated, unless these changes are very small. This is achieved by using a linearized version of the DSF procedure, called the LDSF procedure (Weber and Sen 1985), which is computationally very attractive.
The LDSF Procedure for Tij
Let us assume that we have run the DSF procedure and obtained a good set of Tij
that solves equations (3) and (4) for any given θ. This means that Oi
= Ti*
= Ni*
and Dj
= T*j
= N*j
. Define by ΔΟ = (ΔΟ1,...,ΔΟI)'
and ΔD = (ΔD1,...,ΔDJ)'
to be small changes in the values of Ο = (Ο1,...,ΟJ)'
and D = (D1,...,DJ)'
, respectively. Also, let ΔFij
, be a small change in Fij = exp[ θ'Cij]
. It can be proved (Sen and Smith 1995) that the corresponding small change, ΔTij
, in each Tij
, so that ΔTi* = ΔΟi
, and ΔT*j = ΔDj
can be obtained by the LDSF procedure, which iterates as follows
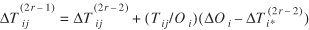 (9)
(9)
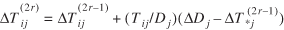 (10)
(10)
for 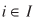 , ,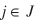 and r
= 0, 1, 2,..., with initial Tij
values given by and r
= 0, 1, 2,..., with initial Tij
values given by 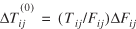 (11)
(11)
A proof for the convergence of the procedure is given in Weber and Sen (1985).
Changes in Tij
as a Function of a Change in θ
For a small change Δθ
in θ and a small change 0
so that ΔΟ = ΔD = 0, it can be proved (Yun and Sen 1994) that an approximation for the corresponding small change ΔTij
for each Tij
for all
and
is given by equation 12.
![uppercase Delta uppercase T subscript {lowercase i j} is approximately equal to uppercase Delta lowercase theta{lowercase c subscript {lowercase i j}times uppercase T subscript {lowercase i j} minus the summation from lowercase j times lowercase c subscript {lowercase i j} times uppercase T subscript {lowercase i j} times (uppercase T subscript {lowercase i j} divided by uppercase O subscript {lowercase i}) minus the summation from lowercase i times lowercase c subscript {lowercase i j} times uppercase T subscript {lowercase i j}(uppercase T subscript {lowercase i j} divided by uppercase D subscript {lowercase j}) + the summation from lowercase i times [the summation subscript {lowercase j} lowercase c subscript {lowercase i j} times uppercase T subscript {lowercase i j} times (uppercase T subscript {lowercase i j} divided by O subscript {lowercase i})] times (uppercase T subscript {lowercase i j} divided by uppercase D subscript {lowercase j})} = uppercase S subscript {lowercase i j} times uppercase Delta lowercase theta](https://webarchive.library.unt.edu/eot2008/20081012180425im_/http://www.bts.gov/publications/journal_of_transportation_and_statistics/volume_06_number_23/images/Metaxatos-56.gif) (12)
(12)
The 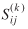 's are constants, and Oi
= Ti*
, Dj
= T*j
. Therefore, if Tij
's are known, the only unknown in equation (12) is the Δθ
. The solution for the Δθ
will be the topic of the next section.
's are constants, and Oi
= Ti*
, Dj
= T*j
. Therefore, if Tij
's are known, the only unknown in equation (12) is the Δθ
. The solution for the Δθ
will be the topic of the next section.
Estimation of θ Using the Modified
Scoring (MS) Procedure
So far, for an initial value for θ, we obtained Tij
(θ) by using the DSF procedure to solve equations (3) and (4). We then changed θ to θ + Δθ and computed, using the LDSF procedure, with Δ0 = ΔD = 0, the corresponding change, ΔTij(θ, Δθ)
in Tij
(θ) as a function of Δθ.
We are ready now to insert the [Tij(θ) + ΔTij(θ, Δθ)]'s into the left side of equation (5) and solve the resultant equation for Δθ. Inserting Tij
+ ΔTij
in place of Tij in (5) and using (12), equations (3) and (4) would remain approximately satisfied, while obtaining the following system of Q
linear equations with Q
unknowns (the Δθq's):
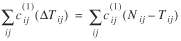
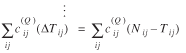 (13)
(13)
This system of equations can be solved by any standard solution method such as Gaussian elimination.
The current solution for θ at iteration r
is updated next using the formula
θr = θr-1 + Δθr-1
(14)
If the corrections Δθr-1
have become negligible, the values of θ have been stabilized and the MS procedure terminates. Otherwise, new Tij
's are obtained from the DSF procedure and the MS procedure continues. There is no guarantee that the MS procedure always converges (Sen and Smith 1995), although our computational experience is positive.
Goodness of Fit
Under the previous assumption that observations Nij
are independently Poisson distributed, the (Pearson) X2
statistic,
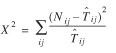 (15)
(15)
where 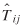 is an estimate of Tij
, is an appropriate measure of the overall fit of a model. Moreover, when
is an estimate of Tij
, is an appropriate measure of the overall fit of a model. Moreover, when 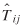 is obtained using maximum likelihood, equation (15) has a X2
distribution with df = ij
– i
–J
– K
+ 1 degrees of freedom (Bishop et al. 1975; Rao 1973).
is obtained using maximum likelihood, equation (15) has a X2
distribution with df = ij
– i
–J
– K
+ 1 degrees of freedom (Bishop et al. 1975; Rao 1973).
If 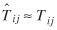 , then X2
= Z2
, where
, then X2
= Z2
, where
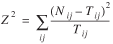 (16)
(16)
Since E
(Nij
) = Tij
and because Nij
have the Poisson distribution,
var(Nij) = E(Nij – Tij)2 = Tij (17)
Therefore, E
(Z2)
= IJ
, where I
is the number of origin zones i,
and J
the number of destinations j
. Equivalently, E
(Z2
/IJ
) = 1. Thus, the so-called "X2
-ratio," X2
/df
, has an expectation that is asymptotically 1. It can be shown (Sen and Smith 1995) that the variance of the X2
-ratio is
![var [uppercase Z superscript {2}/(uppercase I J) is approximately equal to the summation over lowercase i j times [(uppercase T subscript {lowercase i j} times uppercase I superscript {2} times uppercase J superscript {2}) subscript {minus 1}) + 2 times(uppercase I J) superscript {minus 2}]](https://webarchive.library.unt.edu/eot2008/20081012180425im_/http://www.bts.gov/publications/journal_of_transportation_and_statistics/volume_06_number_23/images/Metaxatos-85.gif) (18)
(18)
Hence, if Tij
's are bounded away from zero (which is the case in exponential gravity models with finite parameters θ), the variance of Z2/IJ→0, as IJ→∞. It follows that when 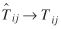 and Tij
's are bounded away from zero, the variance of X2/df→0.
and Tij
's are bounded away from zero, the variance of X2/df→0.
In practical applications, since the Poisson assumption seldom holds perfectly (as is the case here, where every pound or dollar value of shipment does not travel independently of each other pound or dollar value), an X2
ratio less than 2 is a good indication that the gravity model fits the data well (Sen and Smith 1995).
Covariance of Maximum Likelihood Estimates
Covariance of 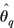 `s
`s
Let small case letters stand for the logarithms of corresponding capital letters (e.g., tij
= log
[Tij
], a
(i
) = log
[A
(i
)], b
(j
) = log
[B
(j
)]. The model (1) may be written as
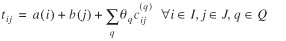 (19)
(19)
Let M
denote the coefficient matrix of the right side of the system of equations (19). The matrix M
is not of full rank (Sen and Smith 1995). However, the matrix M(2)
obtained by deleting one of the first I
+ J
columns of M
is of full rank and has dimension IJ ×
(I + J +
Q
– 1). Let diag( · ) stand for a diagonal matrix, the diagonal elements of which are given within the parentheses. Then compute the matrix M'(2) · diag(T) · M(2) from the equation
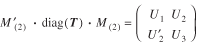 (20)
(20)
where
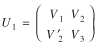 (21)
(21)
 (22)
(22)
U3
= ((upq
)) with 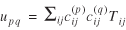 ,
,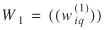 with
with 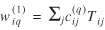 ,
, 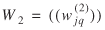 with
with 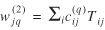 , V1 = diag(T1*,...,TI*)
, V2 = ((Tij))
and V3 = diag(T*1,...,T*j – 1). Notice that the subscript j
in each of the matrices above goes only up to J
– 1.
, V1 = diag(T1*,...,TI*)
, V2 = ((Tij))
and V3 = diag(T*1,...,T*j – 1). Notice that the subscript j
in each of the matrices above goes only up to J
– 1.
Matrix M'(2) · diag(T) · M(2)
, a square matrix of dimension
(I + J + Q – 1), is the covariance matrix of M'(2) · diag(N). This is because the Nij's have independent Poisson distributions and the covariance matrix Cov(N
) of N
is diag(T
). It can be shown (Sen and Smith 1995) that the covariance matrix of 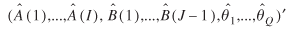 is
is
Φ-1 · M'(2) · diag(T) · M(2) · (Φ-1)'
(23)
where
Φ = M'(2) · diag(T) · M(2) · diag(1/A(1),...,1/A(I), 1/B(1),...,1/B(J – 1), 1,...,1)
(24)
and
Φ-1 = diag(1/A(1),...,1/A(I), 1/B(1),..., 1/B(J – 1), 1,...,1) · (M'(2) · diag(T) · M(2))-1
(25)
Notice that using equations (23) through (25), another expression for the covariance matrix of 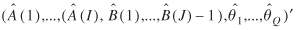 can be written by as follows
can be written by as follows
diag(1/A(1),...,1/A(I), 1/B(1),..., 1/B(J–1),1,...1) ·
(M'(2) · diagT · M(2))-1 · diag(1/A(1),...,1/A(I), 1/B(1),..., 1/B(J–1), 1,...,1)
(26)
The bottom right Q
× Q
submatrix of matrix (26) is the estimated covariance matrix of 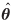 . The bottom right Q ×
Q
submatrix of the inverse of (20) is (Rao 1973)
. The bottom right Q ×
Q
submatrix of the inverse of (20) is (Rao 1973)
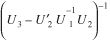 (27) (27)
From equation (26), it follows that equation (27) is the covariance matrix of 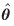 .
.
Covariance of 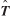 ij
's ij
's
Having obtained Cov(A
,B
,θ) from equation (23) or using equation (26), and since B
(J
) is set equal to a constant, and its variance and covariances involving it are zeros, it can readily be seen that the covariance matrix of , denoted by the symbol Cov() , is
Cov() = Ψ1 · Cov(A,B,θ) · Ψ'1 (28)
with
Ψ1 = diagT · M(2)(1/A(1),...,1/A(I), 1/B(1),..., 1/B(J), 1,...,1)
(29)
and M
the coefficient matrix of the right side of the system of equations (19).
Short-Term Forecasting
The shipment of goods is affected by a multitude of factors (USDOT 1996, table 2.1). The weight and value of commodities shipped, characteristics of immediate concern in this study in particular, may be affected by the economy as a whole, globalization of business, international trade agreements, just-in-time inventory practices (weight only), packaging materials (weight only), economic regulation/deregulation, publicly provided infrastructure (weight only), user charges and other taxes, changes in truck size and weight limits (weight only), and technological advances. The discussion below is based on the assumption that, in the short term (e.g., three to five years) the compound effect of these factors on the size of the weight and value characteristics of commodity shipments is consistent with Poisson randomness.
Let the random variable 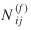 be a future observation1 of the flow from i
to j
. In the short run, under the assumption that the separation configuration will not change during the forecast period, we may conjecture that
be a future observation1 of the flow from i
to j
. In the short run, under the assumption that the separation configuration will not change during the forecast period, we may conjecture that 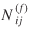 and Nij
will be highly (serially) correlated. Thus, we may then argue that the variance of the difference of future and present observations will be smaller than the variance of future observations alone. Hence,
and Nij
will be highly (serially) correlated. Thus, we may then argue that the variance of the difference of future and present observations will be smaller than the variance of future observations alone. Hence,
var( − Nij) = var() + var(Nij) − 2Cov(Nij) (30)
where var(·) stands for the "variance of" and Cov(·) for the "covariance of," will be small. In such cases, especially if Nij
's are known, Sen and Smith (1995, chapter 5) suggest that it would be preferable to predict ( − Nij)'s and add the predictions to the Nij
's. A possible set of predictions for ( − Nij)'s are (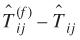 )'s. Thus, if the future is not too far off, )'s. Thus, if the future is not too far off,
Nij + ()
(31)
may yield a better prediction than 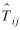 . The computation of
. The computation of 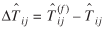 can be made easily using the LDSF procedure described earlier.
can be made easily using the LDSF procedure described earlier.
Other Forecasts
Four separate cases are discussed here. The first case assumes that 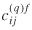 would be available exogenously, θƒ
would be the estimate
would be available exogenously, θƒ
would be the estimate 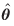 from the base period assumed to remain unchanged into the forecast period, and the estimates Af
(i
) and Bf
(j
) could be base period estimates assumed to remain unchanged into the forecast period, or one or both of them could be exogenous. Then, Tij
for the forecast period may be estimated by
from the base period assumed to remain unchanged into the forecast period, and the estimates Af
(i
) and Bf
(j
) could be base period estimates assumed to remain unchanged into the forecast period, or one or both of them could be exogenous. Then, Tij
for the forecast period may be estimated by
![uppercase T superscript {lowercase f} subscript {lowercase i j} = uppercase A superscript {lowercase f} times (lowercase i) times uppercase B superscript {lowercase f} times (lowercase j) exp[(lowercase theta superscript {lowercase f})’times lowercase c superscript {lowercase f} subscript {lowercase i j}]](https://webarchive.library.unt.edu/eot2008/20081012180425im_/http://www.bts.gov/publications/journal_of_transportation_and_statistics/volume_06_number_23/images/Metaxatos-143.gif) (32)
(32)
The calculation of Cov(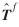 ) requires the computation of the covariance matrices of the Af
(i
)'s, Bf
(j
)'s, and θƒ. For those estimates that remain unchanged from the base period, the appropriate covariance matrix is the one for the base period. For estimates obtained exogenously, the covariance matrix needs to be supplied exogenously. Covariances of estimates obtained from different independent data are usually assumed to be zeros.
) requires the computation of the covariance matrices of the Af
(i
)'s, Bf
(j
)'s, and θƒ. For those estimates that remain unchanged from the base period, the appropriate covariance matrix is the one for the base period. For estimates obtained exogenously, the covariance matrix needs to be supplied exogenously. Covariances of estimates obtained from different independent data are usually assumed to be zeros.
The second case assumes that and θƒ would be available as before and the estimates Bf
(j
) and 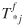 could be base period estimates assumed to remain unchanged into the forecast period or could be obtained exogenously. Then, Tij
for the forecast period may be estimated by
could be base period estimates assumed to remain unchanged into the forecast period or could be obtained exogenously. Then, Tij
for the forecast period may be estimated by
![uppercase T superscript {lowercase f} subscript {lowercase i j} = uppercase T superscript {lowercase f} subscript {asterisk lowercase j} times uppercase B superscript {lowercase f} times (lowercase j) exp[(lowercase theta superscript {lowercase f})’lowercase c superscript {lowercase f} subscript {lowercase i j}] divided by summation subscript {lowercase j} times uppercase B superscript {lowercase f} times (lowercase j) exp[(lowercase theta superscript {lowercase f})’ lowercase c superscript {lowercase f} subscript {lowercase i j}]](https://webarchive.library.unt.edu/eot2008/20081012180425im_/http://www.bts.gov/publications/journal_of_transportation_and_statistics/volume_06_number_23/images/Metaxatos-149.gif) (33)
(33)
The second case assumes that and θƒ would be available as before and the estimates Af
(i
) and could be base period estimates assumed to remain unchanged into the forecast period or could be obtained exogenously. Then, Tij
for the forecast period may be estimated by
![uppercase T superscript {lowercase f} subscript {lowercase i j} = uppercase T superscript {lowercase f} subscript {asterisk lowercase j} times uppercase A superscript {lowercase f} times (lowercase i) exp[(lowercase theta superscript {lowercase f)’ lowercase c superscript {lowercase f} subscript {lowercase i j}] divided by summation subscript {lowercase j} times uppercase A superscript {lowercase f} times (lowercase j) exp[(lowercase theta superscript {lowercase f})’lowercase c superscript {lowercase f} subscript {lowercase i j}]](https://webarchive.library.unt.edu/eot2008/20081012180425im_/http://www.bts.gov/publications/journal_of_transportation_and_statistics/volume_06_number_23/images/Metaxatos-153.gif) (34)
(34)
The computation of the covariance matrices for the second and third cases is similar to the first case once the appropriate Jacobians with respect to Af
(i
)'s, Bf
(j
)'s and θƒ have been obtained. Recall that equation (29) is the respective Jacobian for the first case.
A fourth case, arising when , θƒ, 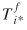 , and are available, requires the use of the DSF procedure to generate the Aƒ
(i
) and Bƒ
(j
). Then, Tij
for the forecast period may be estimated by equation (32). The computation of the covariance matrices for this case is treated in detail by Sen and Smith (1995, p. 440).
, and are available, requires the use of the DSF procedure to generate the Aƒ
(i
) and Bƒ
(j
). Then, Tij
for the forecast period may be estimated by equation (32). The computation of the covariance matrices for this case is treated in detail by Sen and Smith (1995, p. 440).
It is interesting to observe at this point that origin-destination travel times and/or costs (which depend on routes chosen and traffic congestion on the routes) usually become available only after the gravity model has been applied to forecast flows. This difficulty affects only the forecasting phase (not the estimation phase, when we use base period data for which travel times can be observed or computed using available information) and can be alleviated by combining the distribution and assignment stages of the process into a single stage.
EMPIRICAL ANALYSIS
Data Issues
Freight Shipments
Oak Ridge National Laboratory (ORNL) provided two sets of origin-destination flow data for freight shipment weight and value between origin seaports/border ports of entry i
and destination states j
from the following sources:
-
The Transborder Surface Freight Database.
This database (http://www.bts.gov/transborder/prod.html) is distributed by the Bureau of Transportation Statistics and contains freight flow data by commodity type and surface mode of transportation (rail, truck, pipeline, or mail) for U.S. exports to and imports from Canada and Mexico.
-
The Port Import Export Reporting Service (PIERS) Database.
This commercial database (http://www.piers.com/about/default.asp), offered by the Journal of Commerce
, offers statistics on global cargo movements transiting seaports in the United States, Mexico, and South America to companies around the globe.
Two matrices, Nij
, were developed: one for shipment weight and one for shipment value for each of the two databases with dimensions 128 × 50 and 144 × 50 for the Transborder and PIERS databases, respectively.
The limitations of these two data sources are well documented (Meyburg and Mbwana 2002). A caveat for the Transborder Database is that it is a customs, not a transportation, dataset, resulting in inconsistencies between U.S. and Canadian data and issues related to the accuracy of transshipment data.2 One caveat for using PIERS is that reported origins and destinations may be billing addresses rather than shipment points.
Separation Measures
In identifying specific types of spatial separation that tend to impede or enhance the likelihood of interactions between points of entry and destination sites, the most obvious type involves physical space, as exemplified by travel distance and travel time, which are quantifiable in terms of meaningful units of measurement. ORNL provided two sets with separate impedance matrices, 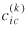 , k
= 1, 2 from origin point i
to destination county c
.
, k
= 1, 2 from origin point i
to destination county c
.
The first dataset included impedances between origin seaports and destination counties, the second set between origin border ports and destination counties. Both measures were computed from ORNL's National Highway Network (NHN). The first of the two measures is the route (network) distance in miles; the second computes a function of travel time for different functional classifications of highway segments and adds these time penalties together while tracing the previous network routes. The previous impedance matrices presented two problems: 1) more than 50% of the cells were empty because not all seaports/border ports of entry are connected to each county through the NHN; and 2) occasionally, freight shipments moved between origin-destination pairs with a missing connection (separation measure).
In order to deal with both problems, we devised and implemented the following stepwise procedure for the distance matrix (the first separation measure, 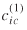 ).
).
1. Centroid coordinates were computed for all counties nationwide.
2. Spherical distances in miles from each county to every other county.
3. For every destination county with a missing connection to an origin point (seaport/border port of entry), the closest county with an existing connection to an origin point was estimated based on the previous county-to-county distances.
4. The missing connection from an origin point to a destination county was finally computed to be the distance between the same point of origin and the closest destination county augmented by 130% the (airline) distance between the two destination counties (as a proxy to the actual road distance). This simplification was made under the assumption that a missing connection would imply that the destination county is off the NHN and thus would require additional time to be accessed from its closest county on the NHN.
The above procedure resulted in the construction of a synthesized separation measure comprising both route distance (the ORNL estimate) and multiples of airline distance (our estimate). It is important to take a closer look at those two components of the (re-estimated) first separation measure .
The airline distance between origin point i
and destination county c
, even augmented by 30%, is only an approximation of the actual miles traveled and represents a surrogate for the complex set of factors that express the difficulty of overcoming separation. On the other hand, the route distance for the same origin-destination pair is the total over-the-road distance on a realistic route. As a measure of separation, the route distance provides better accuracy for the eastern half of the limited access highway system of the United States, which has a higher level of complexity resulting in less circuitous routes than in the western half.
Whereas the distance measure developed above is a measure that depends more or less on the physical characteristics of the road link, the impedance measure, a function of link travel time as estimated by ORNL, depends on the special roadway type or certain conditions encountered on the link. ORNL's estimating procedure could not be replicated in this paper for the missing impedances. A surrogate value was computed based on the average speed obtained by ORNL's distance and time estimates, and the synthesized distances.
The procedure classified ORNL's distance and time estimates into 10 deciles. The stratum average speed was computed by the ratio of the average distance and time for that stratum (table 1). Each missing time impedance was then estimated by the ratio of its corresponding distance estimate and the average speed of the stratum to which the distance estimate belongs.
Clearly, this procedure imposes some inconsistency in the imputation of travel times, because the average speed estimate is based on decile groupings of the initial estimates. The consistency of the procedure could be improved if in a second iteration the decile groupings are based on all distances (initial and imputed), but I did not attempt this for this paper.
The previous steps resulted in two re-estimated sets of separation measures: 1) a distance matrix and a travel time matrix between origin seaports and destination counties; and 2) a distance matrix and a travel time matrix between origin points of entry and destination counties. The final step in preparing the separation measures for model estimation was to estimate these measures between origin points and destination states rather than counties. This was made possible simply by computing for each origin point i
and all destination counties 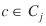 in state j
the average distance and travel time. That is,
in state j
the average distance and travel time. That is,
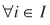 ,
, 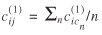 ,
,
and
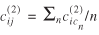 ,
, 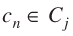
where n
is the cardinality of Cj
. Note that had we avoided the intermediate step of origin-to-destination county distance estimation, say, by computing distances to state geographical centers, origin-destination pairs with both ends in the same state would have been indistinguishable in terms of their separation.
Other Relevant Variables
As mentioned earlier, the weight and value of commodities shipped may be affected by a nexus of factors that are either origin-specific, destination-specific, or solely dependent on separation between an origin and a destination. Although study resources did not permit the collection of pertinent data on these factors, it could be interesting to observe how such factors can be accommodated in the proposed theoretical framework for future
reference.
For origin-specific and destination-specific factors, Sen and Smith (1995) propose the following exploratory analysis: estimate Ai
's and Bj
's first using the maximum likelihood procedure described earlier, and then use these estimates as the dependent variable values in a model fitting procedure. Thus, the estimates of the Ai
's can be associated with the origin-specific factors, while the estimates of the Bj
's can be associated with the destination-specific factors.
Factors that can be solely attributed to the separation between an origin and destination can be accommodated in a deterrence function, an example of which is indeed the most general exponential function in equation (2). Openshaw and Connolly (1977) have compiled a list of possible functions and empirically compared several of them.
Results
The only decision necessary to apply the procedures described above (i.e., DSF, LDSF, and MS) is the choice of the flow unit. In the case of passenger transportation, a flow unit of 1 (consistent with a Poisson or multinomial distribution assumption) would be reasonable. In the case of freight shipments of goods, a basic unit of flow would appear to be a trainload (for shipments by rail) or a truckload (for shipments by truck). In the absence of mode-specific information as well as information related to the variation in modal size, we experimented with different values and determined an "optimal" (with regard to providing the best model fit) basic unit of flow of 100,000 pounds or dollars. This is not surprising given that the bulk of flows are long-distance shipments usually performed by large3 trucks or rail (on a limited scale for the particular data) with an average shipment value of $2.03 per pound for the Transborder data and $1.39 per pound for the PIERS data. Interestingly, our results appeared to be quite insensitive to the choice of the flow unit, primarily because the flows were inordinately large. This is in agreement with previous work (Sen and Pruthi 1983).
The procedures described above were run to a tight convergence. For each iteration of the MS procedure, the DSF procedure attained a 10E
–12 convergence as defined by equation (8) in less than 100 iterations. The MS procedure itself attained a 10E
–06 convergence as defined by the right-hand side of equation (13) in less than 20 iterations.
Parameter Estimates and Model Fit
for PIERS Data
Separate gravity models were estimated for both seaport-to-state (seaport data) and border port-to-state (transborder) weight and value flows. In particular, for the seaport data, several model specifications were tested based on transformations of the distance and time separation measures, 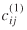 and
and 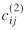 , respectively, after a careful examination of residuals that showed the presence of outliers.
, respectively, after a careful examination of residuals that showed the presence of outliers.
In the analysis of residuals, two difficulties were addressed. The first difficulty is the unequal variances of residuals, a consequence of the Poisson distribution. This problem was handled by considering, as Cochran suggests (Rao 1973, p. 393), instead of the plain residuals 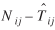 , the components
, the components
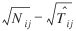 (35)
(35)
The second difficulty stems from the very large number of residuals (the number is I
× J
, the number of all origin-destination pairs). To tackle this concern, we followed a procedure described in Sen and Smith (1995, p. 456) consisting of drawing normal (rankit) plots of residuals. If the residuals are normal, such a plot would lie approximately on a straight line. Points that deviate sharply near the ends were tagged as outliers. Unusual jumps in the plots or other strongly nonlinear shapes could signal the need for transformations of the 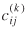 's or for additional
's or for additional 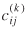 's. There are clearly other ways of examining residuals. It is important to note here that the effort to conduct residual analysis in the gravity model case should not be seen as less than that for linear models where residual analysis is routinely carried out.
's. There are clearly other ways of examining residuals. It is important to note here that the effort to conduct residual analysis in the gravity model case should not be seen as less than that for linear models where residual analysis is routinely carried out.
Indeed, the examination of residuals signaled the need for transformation of the 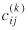 's. We found the square root transformation provided adequate fit for both weight flow and value flow estimates (table 2). The model provides an excellent fit for the data, because the Chi-square statistic hovers around its expected value of 1. In addition, the cell-to-cell weight flow estimates correlate very well with the data (Pearson correlation coefficient, r
= 0.89, p
< 0.01. The cell-to-cell value flow estimates also correlate very well with the data (r
= 0.98, p
< 0.01). Moreover, the weight and value length distributions in figure 1 (1% corresponds to 2,292,872,822 pounds) and figure 2 (1% corresponds to $3,198,123,011), respectively, seem to corroborate the previous results.
's. We found the square root transformation provided adequate fit for both weight flow and value flow estimates (table 2). The model provides an excellent fit for the data, because the Chi-square statistic hovers around its expected value of 1. In addition, the cell-to-cell weight flow estimates correlate very well with the data (Pearson correlation coefficient, r
= 0.89, p
< 0.01. The cell-to-cell value flow estimates also correlate very well with the data (r
= 0.98, p
< 0.01). Moreover, the weight and value length distributions in figure 1 (1% corresponds to 2,292,872,822 pounds) and figure 2 (1% corresponds to $3,198,123,011), respectively, seem to corroborate the previous results.
Of interest in table 2 is the appearance of 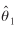 with a positive value. This is due to collinearity between the used impedances, distance and travel time, a phenomenon that is known to adversely affect the sign of parameter estimates. Dropping one of the impedances would bias the parameter estimates left in the model. Given the robustness of the maximum likelihood procedure above in collinearity situations, all available impedance measures were retained (Sen and Smith 1995, chapter 5). After all, the sign of would have changed to a negative value had we reparameterized the model and considered instead of travel time as the first impedance measure, the difference between distance and travel time (in appropriate units).
with a positive value. This is due to collinearity between the used impedances, distance and travel time, a phenomenon that is known to adversely affect the sign of parameter estimates. Dropping one of the impedances would bias the parameter estimates left in the model. Given the robustness of the maximum likelihood procedure above in collinearity situations, all available impedance measures were retained (Sen and Smith 1995, chapter 5). After all, the sign of would have changed to a negative value had we reparameterized the model and considered instead of travel time as the first impedance measure, the difference between distance and travel time (in appropriate units).
In the end, the model specifications for the weight and value flows, respectively, are
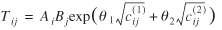
![uppercase T subscript {lowercase i j} = uppercase A subscript {lowercase i} times uppercase B subscript {lowercase j} exp(lowercase theta subscript {1} times lowercase c superscript {(1)} subscript {lowercase i j}] + lowercase theta subscript {2} times square root of lowercase c superscript {(2)} subscript {lowercase i j})](https://webarchive.library.unt.edu/eot2008/20081012180425im_/http://www.bts.gov/publications/journal_of_transportation_and_statistics/volume_06_number_23/images/Metaxatos-179.gif) (36)
(36)
Parameter Estimates and Model Fit for Transborder Data
In the case of Transborder data, we conducted a similar investigation of residuals (as above with the PIERS data) and observed the presence of a few remaining outliers, despite using transformed 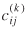 's. These outliers were mainly states receiving an unusually large share of shipments compared with other states. The discovery was made after squaring the residuals in equation (35) and adding them together for all origin points of entry for each destination state. Destination states with a large share of shipments had a much larger sum of squares of residuals than other destinations. This was understandable, because these large destination states attract more shipments from longer distances and suggest the use of an additional impedance variable
's. These outliers were mainly states receiving an unusually large share of shipments compared with other states. The discovery was made after squaring the residuals in equation (35) and adding them together for all origin points of entry for each destination state. Destination states with a large share of shipments had a much larger sum of squares of residuals than other destinations. This was understandable, because these large destination states attract more shipments from longer distances and suggest the use of an additional impedance variable
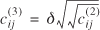
for the weight flows, and
![lowercase c superscript (3) subscript {lowercase i j} = lowercase delta log[c superscript (2) subscript {lowercase i j}]](https://webarchive.library.unt.edu/eot2008/20081012180425im_/http://www.bts.gov/publications/journal_of_transportation_and_statistics/volume_06_number_23/images/Metaxatos-182.gif)
for the value flows, where δ
is 1 for destinations with more than a 10% share in weight (4% in value) and 0 otherwise. In effect, we sought a different parameter estimate for the square root/log of distance for destination states with large shares.
The previous use of the indicator (dummy) variable δ is typical in spatial analysis for the treatment of residuals (Sen and Smith 1995) and introduces the effects of spatial structure on flow patterns (Gensler and Meade 1988; Fotheringham and O'Kelly 1989; Lo 1991), which is not the primary intent of this paper. More complex measures of relative location have been developed and tested empirically (Boots and Kanaroglou 1988; Lowe and Sen 1996). In the end, the model specifications for the weight and value flows, respectively, are
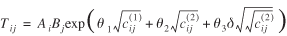
![uppercase T subscript {lowercase i j} = uppercase A subscript {lowercase i} times uppercase B subscript {lowercase j} exp(lowercase theta subscript {1} times lowercase c superscript {(1)} subscript {lowercase i j} + lowercase theta subscript {2} times lowercase c superscript {(2)} subscript {lowercase i j} + lowercase theta subscript {3} times lowercase delta log[lowercase c superscript {(2)} subscript {lowercase i j}])](https://webarchive.library.unt.edu/eot2008/20081012180425im_/http://www.bts.gov/publications/journal_of_transportation_and_statistics/volume_06_number_23/images/Metaxatos-186.gif) (37)
(37)
The previous steps removed all remaining outliers. Parameter estimates and goodness-of-fit statistics are shown in table 3. The previous observation regarding the sign of 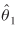 applies. The model fits the data very well, as the Chi-square ratios for both weight and value remain under 2. In addition, the cell-to-cell weight flow estimates correlate very well with the data (Pearson correlation coefficient, r
= 0.91, p
< 0.01). The cell-to-cell value flow estimates also correlate very well with the data (r
= 0.94, p
< 0.01). Moreover, the weight and value length distributions in figure 3 (1% corresponds to 767,519,815 pounds) and figure 4 (1% corresponds to $1,565,313,371), respectively, seem to corroborate the previous results.
applies. The model fits the data very well, as the Chi-square ratios for both weight and value remain under 2. In addition, the cell-to-cell weight flow estimates correlate very well with the data (Pearson correlation coefficient, r
= 0.91, p
< 0.01). The cell-to-cell value flow estimates also correlate very well with the data (r
= 0.94, p
< 0.01). Moreover, the weight and value length distributions in figure 3 (1% corresponds to 767,519,815 pounds) and figure 4 (1% corresponds to $1,565,313,371), respectively, seem to corroborate the previous results.
Computation of Covariance of Estimates
for PIERS Data
The previous point estimates of the 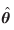 parameters and the flows
parameters and the flows 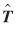 were used in the methodology described earlier to obtain the covariance of these estimates. The procedure can accommodate any reasonable number of separation measures,
were used in the methodology described earlier to obtain the covariance of these estimates. The procedure can accommodate any reasonable number of separation measures, 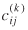 , and the large number of origins and destinations typically encountered in practice.
, and the large number of origins and destinations typically encountered in practice.
The computational requirements of the procedure are no longer prohibitive. We were able to obtain the covariance matrix of a 144 × 50 flow matrix, a 7200 × 7200 matrix, in a little more than an hour on a Pentium III, 800 MHz, 512MB RAM laptop computer running a FORTRAN 77 compiler. Replacing Tij
's by their estimates in equation (27), the covariance matrix of for the weight flows from the PIERS dataset was found to be
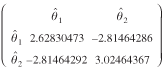 (38)
(38)
The correlation between 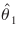 (the parameter estimate for the distance measure) and
(the parameter estimate for the distance measure) and 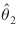 (the parameter estimate for the travel time measure) is readily apparent from equation (38). The negative sign of the covariances should not be disconcerting. It shows that, if for some small shift in the observations, were to increase, would decrease to "compensate."
(the parameter estimate for the travel time measure) is readily apparent from equation (38). The negative sign of the covariances should not be disconcerting. It shows that, if for some small shift in the observations, were to increase, would decrease to "compensate."
Similarly, the covariance matrix of for the value flows from the PIERS dataset was found to be
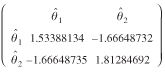 (39)
(39)
The correlation between and is similarly apparent from equation (39).
Computation of Covariance of Estimates
for Transborder Data
The covariance matrices of 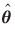 from the Transborder dataset for the weight and value flows, respectively, were found to be
from the Transborder dataset for the weight and value flows, respectively, were found to be
 (40)
(40)
and
 (41)
(41)
These last two covariance matrices in equations (40) and (41) show relatively high correlation between (the parameter estimate for the distance measure) and (the parameter estimate for the travel time measure) and relatively low correlation between 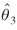 (the parameter estimate for the transformed travel time measure) and or . The interpretation of the negative signs is the same as above.
(the parameter estimate for the transformed travel time measure) and or . The interpretation of the negative signs is the same as above.
For illustration purposes, an example of the usefulness of the computed covariance matrices for 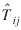 's in computing confidence intervals is shown in table 4. The table shows a few Nij
's,
's in computing confidence intervals is shown in table 4. The table shows a few Nij
's, 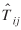 's, percentage difference between Nij
and
's, percentage difference between Nij
and 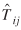 , and 90% confidence intervals constructed by adding and subtracting 1.65 times the standard error available from the variances.
, and 90% confidence intervals constructed by adding and subtracting 1.65 times the standard error available from the variances.
CONCLUSIONS
The most characteristic and indeed more restrictive feature of the Poisson distribution is the equality between its mean and variance. Many types of spatial interaction phenomena exhibit restricted (variance less than their means) or extra variation (variance greater than their means). Yet, the framework described above is very robust. Its robustness stems from the many types of asymptotic results that establish the Poisson distribution as the unique limiting form for a wide range of interaction processes when the population size increases and the overall influence of each individual interaction decreases.
More specifically, this research demonstrates that, to the extent the behavior of each shipping firm can be thought of as a very small interaction process, the resultant interaction process (i.e., the realized pattern of origin-destination commodity shipments) can be thought of as the superposition of all these processes and thus characterized by gravity models. The limited empirical analysis in this paper confirmed this conjecture and thus establishes an extremely rich framework for future experimentation.
Future applications of the proposed framework could conduct additional exploratory analyses to determine which factors affecting the demand for freight shipments are origin-based, destination-based, or separation-based. Another important issue needing more attention in the future is the requirement that, when the proposed modeling framework is used for forecasting, the travel times and costs used as impedance measures should be consistent with those obtained during the traffic assignment.
In summary, this paper has provided evidence that the movement of freight shipments can now be estimated within a desired confidence level as a result of maximum likelihood estimation of Poisson gravity models. The freight transportation modeler has two procedures available for computing reliable information within a predetermined accuracy: one for computing freight flow estimates and one for computing covariance matrices. These procedures can accommodate any reasonable number of separation measures,, and the large number of origins and destinations typically encountered in practice.
ACKNOWLEDGMENTS
This paper reports on research conducted by the author for the Bureau of Transportation Statistics, U.S. Department of Transportation.
REFERENCES
Bishop, Y.M.M., S.E. Fienberg, and P.W. Holland. 1975. Discreet Multivariate Analysis: Theory and Practice.
Cambridge, MA: MIT Press.
Boots, B. and P. Kanaroglou. 1988. Incorporating the Effects of Spatial Structure in Discrete Choice Models of Migration. Journal of Regional Science
28:495–507.
Cambridge Systematics. 1997. A Guidebook for Forecasting Freight Transportation Demand, NCHRP Report 388. Transportation Research Board, National Research Council.
Fotheringham, A. and M. O'Kelly. 1989. Spatial Interaction Models: Formulations and Application. Studies in Operational Regional Science.
Boston, MA: Kluwer Academic Publishers.
Gensler, W. and M. Meade. 1988. Locational and Population Factors in Health Care-Seeking Behavior in Savannah, Georgia. Health Services Research
22:443–462.
Lo, L. 1991. Spatial Structure and Spatial Interaction: A Simulation Approach. Environment and Planning A
23:1279–1300.
Lowe, J. and A. Sen. 1996. Gravity Model Applications in Health Planning Analysis of an Urban Hospital Market. Journal of Regional Science
36:(3)437–462.
Memmot, F.W. 1983. Application of Statewide Freight Demand Forecasting Techniques, NCHRP Report 260. Transportation Research Board, National Research Council.
Metaxatos, P. 2002. International Trade Traffic Study (Section 5115): Measuring the Ton-Miles and Value-Miles of International Trade Traffic Carried by Highway for Each State: Estimation of Origin-Destination Flows and Confidence Intervals, Final Report, prepared for the U.S. Department of Transportation, Bureau of Transportation Statistics. March.
Meyburg, A.H. and J.R. Mbwana, eds. 2002. Conference Synthesis: Data Needs in the Changing World of Logistics and Freight Transportation. New York Department of Transportation, Albany, NY. Available at http://www.dot.state.ny.us/ttss/conference/synthesis.pdf.
Openshaw, S. and C.J. Connolly. 1977. Empirical Derived Deterrence Functions for Maximum Performance Spatial Interaction Models. Environment and Planning A
9:1067–1079.
Rao, C.R. 1973. Linear Statistical Inference and Its Application.
New York, NY: Wiley.
Sen, A. and T.E. Smith. 1995. Gravity Models of Spatial Interaction Behavior.
New York, NY: Springer-Verlag
Sen, A. and R.K. Pruthi. 1983. Least Squares Calibration of the Gravity Model When Intrazonal Flows are Unknown. Environment and Planning A
15:1545–1550.
U.S. Department of Transportation (USDOT). 1996. Quick Response Freight Manual,
DOT-T-97-10. Washington, DC. September 1996.
Weber, J.S. and A. Sen. 1985. On the Sensitivity of Gravity Model Forecasts. Journal of Regional Science
25:317–336.
Yun S. and A. Sen. 1994. Computation of Maximum Likelihood Estimates of Gravity Model Parameters. Journal of Regional Science
34:199–216.
Author address:
Paul Metaxatos, University of Illinois at Chicago, 412 South Peoria Street, Suite 340, Chicago, IL 60607. Email: pavlos@uic.edu.
KEYWORDS: freight origin-destination flow estimation, covariance of estimates, gravity model.
1. The superscript f denotes that the quantity is an estimate for the forecast period.
2. See http://www.bts.gov/ntda/tbscd/desc.html, as of January 2004, for more information.
3. Currently, the gross weight limit for a 6-axle combination truck is 80,000 pounds.
|

