
Summary of HYSPLIT Modifications for
Short-Range Homeland Security Simulations
The dispersion equations used in HYSPLIT versions prior to 4.7 were more appropriate for longer-range simulations.
For instance, the vertical mixing coefficient profile in the boundary layer was replaced by its average value to smooth
some of the short-term fluctuations. Both horizontal and vertical mixing was computed from a diffusion coefficient,
which required some assumptions about the turbulent length scale when converted to the turbulent velocity variance.
Further, observational data could not be easily incorporated into the calculation, nor could turbulence data generated
by some of the newest generation meteorological forecast models. All these deficiencies have been addressed with
HYSPLIT version 4.7.
New Diffusion / Dispersion Parameterizations
The HYSPLIT code was restructured to be able to use the TKE (turbulent kinetic energy) fields from ETA (and other
models) to compute dispersion. These changes are also required for the model to use measured turbulence data, regardless
of whether TKE fields are available from the meteorological model. The dispersion subroutines and corresponding
meteorological data arrays now contain the turbulent velocity variance (m2/s2) rather than a diffusion coefficient
(m/s2). The equations used to compute the turbulent particle motion or puff growth did not change. The dispersion
computation method can be selected from the model's “namelist” configuration file. Options include the use of the ETA
or RAMS model's TKE field, measured velocity variances (if available in the meteorological data input file), or HYSPLIT's
previous boundary layer (BL) parameterizations. An additional option was added to computed the mixed layer depth from
the TKE profile. New relationships for the boundary layer velocity variances as a function of u*, w*, and zi,
applicable for short-range dispersion simulations are incorporated into the code. These equations also permit the
decomposition of the TKE into its vertical and horizontal components as a function of the BL properties. A more
detailed discussion of the new equations added to HYSPLIT 4.7 can be found in the recently updated Technical
Memorandum:
http://www.arl.noaa.gov/data/web/models/hysplit4/win95/arl-224.pdf
Information on how to configure the model's input files for these new options can be found in the updated User's
Guide:
http://www.arl.noaa.gov/data/web/models/hysplit4/win95/user_guide.pdf
The Computation of Turbulent Velocity Variances
New equations were added to compute the turbulence directly from boundary layer stability functions (adapted from
Kantha and Clayson, 2000, Small Scale Processes
in Geophysical Fluid Flows). This method does not use the diffusivity
and hence no assumptions are required about the turbulence scales. Either equation set (diffusivity or turbulence) can
be selected for a simulation. However, simulations using the new turbulence equations require more CPU time than the
diffusivity based calculation. For instance, in the boundary layer, the following equations would be used in stable
and neutral conditions:
w'2 = 3.0 u*2 (1 - z/zi)3/2
u'2 = 4.0 u*2 (1 - z/zi)3/2
v'2 = 4.5 u*2 (1 - z/zi)3/2
and in unstable conditions:
w'2 = w*2 (z/zi)2/3 (1 - z/zi)2/3 (1 + 0.5 R2/3)
u'2 = v'2 = 0.36 w*2
R = 0.2 (Heat flux at inversion to surface)
An important aspect of introducing a new calculation scheme is to show that the model's performance has actually
improved. High resolution meteorological data are not available for most of the historical tracer experiments
currently available for analysis. It makes little sense trying to test a model's performance on the 10 km scale
when the meteorological data's grid points are 250 km apart at six hour intervals. In this respect it is necessary
to incorporate some of the local meteorological observations that have been archived with many of these tracer
experiments.
Blending Observations for Higher Resolution HYSPLIT Simulations
A series of programs were developed to produce higher resolution meteorological data sets from the coarse resolution
archives. These data can then be used for shorter range simulations. In particular, local observational data can be
blended into existing gridded data files to permit simulations to easily transition from observed local data to the
mesoscale, regional, or global domain. A future application (not yet incorporated) would be to customize relatively
coarse grid data to be more representative of finer spatial scales by incorporating high resolution topography, land
use data, and perhaps a mesoscale meteorological model in an assimilation mode. In the current blending procedure,
the observational data processing consists of four steps:
1) The TKE field (only available from the ETA and RAMS models) is used to compute the 3D turbulent velocity
variances (u'2, v'2, w'2). These new fields are then added as additional records to
each level of the original data file, replacing the TKE field.
2) The second step performs a bilinear spatial interpolation to create new grid points between those of the existing
grid. The new grid spacing should be comparable to the spacing of any observational data that will be subsequently
blended into the data file.
3) Normally the meteorological model output fields are usually of rather coarse temporal resolution. The third step
is to linearly interpolate the data file to a finer temporal frequency to match the temporal frequency of the observations.
4) In the final step, the gridded meteorological data file is edited based upon observations within the domain such as
wind direction, speed, and turbulence. A correction factor is computed to match the interpolated gridded data to the
same location, height, and time as the observation. All the gridded data within the mixed layer are adjusted by the
same correction factor.
This blending process is not intended to be a replacement for 4D data assimilation, but a quick way to adjust the
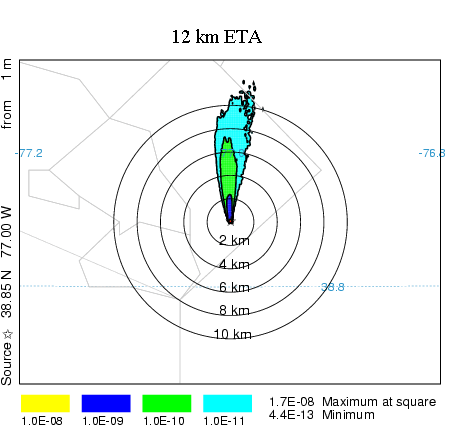
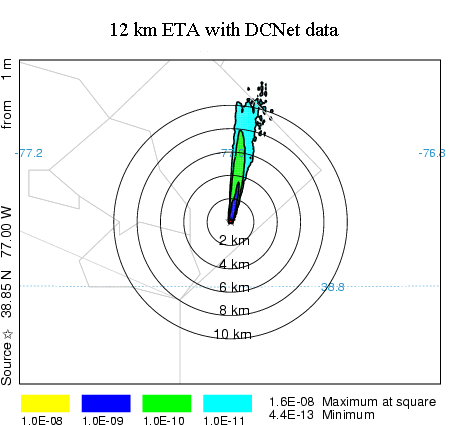
initial transport direction to match observations near the pollutant release location. An example calculation is shown
in the illustration below. The 12 km ETA fields and the DCNet tower data were interpolated into a 2-km 15 minute
resolution data grid. A one-hour duration plume release using only the ETA fields is shown on the left and the same
calculation using local tower data (DCNet) blended into the ETA grid is shown on the right. The calculation with the
tower data shows a more easterly component to the transport direction. Concentrations are about the same.
 |
 |
 |
HYSPLIT Verification over Washington, D.C. using METREX data
The meteorological data blending procedure has been tested against tracer data collected during METREX. The
Metropolitan Tracer Experiment (METREX) consisted of simultaneous 6-h duration perfluorocarbon releases from two
locations every 36-h in the Washington D.C. suburbs for one year (1984). Sequential 8-h air concentrations were
collected at three locations in the urban area. Monthly average tracer concentrations were collected at 93 locations.
The experimental data archive is available on-line at
http://www.arl.noaa.gov/ss/transport/tracer.html#METREX.
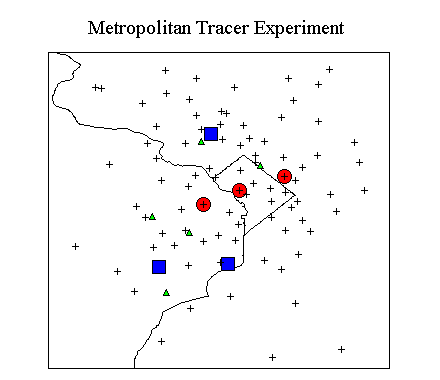
The experimental domain is shown on the adjacent map. The tracer release locations are shown as the blue squares;
the sequential sampling locations are the red dots; meteorological towers are the green diamonds; and the monthly
sampling locations are shown by the plus symbols. For reference, the approximate distance between the sequential
sampling locations is 10 km.
|
Although meteorological data were collected during METREX, these files are not compatible with HYSPLIT. The 2.5
deg 6-h NCAR/NCEP reanalysis data were interpolated to a 5 km resolution 30-min interval grid covering a 1 deg square
domain centered over Washington D.C. Meteorological tower observations at five locations, collected during METREX, were
blended into the gridded data using the interpolation procedure discussed in the previous section. The model was run
for 1984 for each release location. However, only the results from the monthly sampling network are discussed because
they provide the greatest number of sampling locations within 10 km of each release location. The measured data and
model results were converted to the DATEM compatible format (
http://www.arl.noaa.gov/datem) so that existing
statistical programs could be used for data analysis. The results, summarized in the Table shown below, have been
averaged for the entire year so that the statistics represent the means and variations between the 93 monthly sampling
locations. The PMCH was released from Rockville, MD, from January through May and from Lorton, VA, the rest of the year,
while the PDCH was released from Mt. Vernon, VA, the entire year. Absolute PDCH numbers are higher because its release rate
was six times that of the PMCH release rate. Concentration units are in pico grams (pg/m3). The diffusivity approach
is the original Hysplit mixing scheme and the turbulent velocity method is the new approach for short-range dispersion
discussed in the previous section.
| Statistic |
Reanalysis Data Diffusivity |
Reanalysis Data Turbulent Velocity |
+ Tower Data Diffusivity |
+ Tower Data Turbulent Velocity |
| |
pmch |
pdch |
pmch |
pdch |
pmch |
pdch |
pmch |
pdch |
Correlation |
0.90 |
0.65 |
0.88 |
0.59 |
0.91 |
0.55 |
0.86 |
0.80 |
Mean Calculated |
132 |
297 |
130 |
282 |
23 |
70 |
116 |
296 |
Mean Measured |
72 |
385 |
72 |
385 |
72 |
385 |
72 |
385 |
Ratio C / M |
1.83 |
0.77 |
1.80 |
0.73 |
0.32 |
0.18 |
1.6 |
0.77 |
NMSE (pg/m 3 ) |
0.93 |
4.40 |
1.00 |
4.85 |
8.62 |
23.5 |
0.86 |
3.36 |
Bias (pg/m 3 ) |
+60 |
-88 |
+58 |
-103 |
-49 |
-315 |
+44 |
-89 |
Percent x2 |
40 |
55 |
42 |
54 |
21 |
9 |
48 |
64 |
Percent x5 |
94 |
98 |
92 |
92 |
73 |
38 |
93 |
98 |
In general the use of the turbulent velocity variance method provides slightly better results than the
diffusivity method only when the finer resolution tower data are introduced into the calculation. These results,
shown in the last two columns, have the lowest NMSE and the greatest number of samples within a factor of two of
the measurements. The introduction of tower data without corresponding improvements to the model result in a
degradation of performance. The poor performance of the model when the older diffusivity method is used with the
tower data is believed to be caused by too much vertical mixing. The addition of the tower temperatures to the
reanalysis data temperature profiles resulted in larger changes to the vertical mixing in the diffusivity method
than in the turbulent velocity method.
|

